
El Instituto de Ingeniería del Conocimiento (IIC) ha desarrollado un modelo de lenguaje adaptado al dominio legal que mejora significativamente la precisión de nuestras soluciones de Procesamiento del Lenguaje Natural (PLN) para el sector legal.
 El desarrollo de este modelo de lenguaje en español adaptado al sector legal surge como parte de un proyecto de investigación del IIC donde se ha estudiado la explotación y creación de modelos de lenguaje en español: RigoBERTa
El desarrollo de este modelo de lenguaje en español adaptado al sector legal surge como parte de un proyecto de investigación del IIC donde se ha estudiado la explotación y creación de modelos de lenguaje en español: RigoBERTa
Modelos de lenguaje en PLN
Dentro del Procesamiento del Lenguaje Natural moderno, los modelos de lenguaje se han convertido en los cimientos fundamentales de cualquier sistema avanzado de tratamiento del texto, permitiendo mejorar significativamente la fiabilidad de estos sistemas.
Como ya explicábamos en el post Transformers en Procesamiento del Lenguaje Natural, un modelo de lenguaje es una red neuronal artificial de gran tamaño, capaz de analizar ingentes volúmenes de texto escrito para aprender la estructura con la que se presentan las palabras de un determinado idioma.
Modelos como BERT, RoBERTa, T5 o GPT-3 son modelos del lenguaje inglés que durante los últimos años han demostrado capacidades sorprendentes como la generación de noticias, pero también una alta efectividad a la hora de resolver problemas de PLN complejos como la traducción automática, la generación de resúmenes, o la recuperación de información en base a preguntas formuladas en lenguaje natural.
¿Cómo se aplica un modelo de lenguaje?
La forma de aplicación de un modelo de lenguaje generalmente consta de dos pasos:
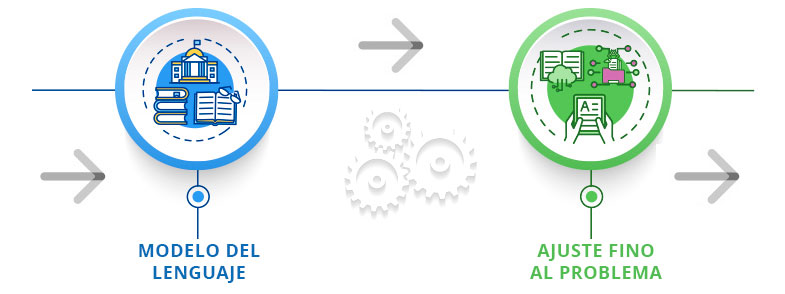
- Aprendizaje del modelo de lenguaje o pre-entrenamiento: partiendo de un modelo de red neuronal artificial “en blanco”, se realiza un proceso de aprendizaje en el que la red analiza un corpus de gran tamaño del idioma de interés, para así aprender la distribución habitual de las palabras en textos de ese idioma.
- Ajuste fino al problema: el modelo de lenguaje se reajusta para resolver una tarea concreta de PLN, como pudiera ser la clasificación de documentos por temáticas, o el resumen automático de noticias. Para ello es necesario un corpus anotado específico del problema resolver, que el modelo de lenguaje usará como guía para aprender a resolver la tarea objetivo.
Aunque el Aprendizaje del modelo de lenguaje supone un alto coste en recursos, tanto computacionales como de recopilación y limpieza de corpus, el modelo de lenguaje generado puede reutilizarse en múltiples tareas diferentes en el mismo idioma. De esta manera, un modelo del lenguaje español puede reajustarse a diferentes problemas de PLN en español con un coste moderadamente bajo, produciendo así soluciones efectivas para todos estos problemas, y de mayor calidad que si no se dispusiera de tal modelo de lenguaje.
No obstante, un punto clave en el desarrollo de soluciones de PLN es la consideración del dominio del lenguaje. Los términos y jerga empleadas en sectores especializados, como puede ser el médico, difieren mucho de la empleada en el sector financiero, que a su vez no son comparables a las del sector legal.
Los modelos del lenguaje generalistas suelen crearse empleando corpus recopilados a partir de extracciones de páginas web, noticias en medios generalistas, obras literarias o webs enciclopédicas (ej. Wikipedia), por lo que no se ajustan del todo al lenguaje empleado en dominios concretos.
Adaptación del modelo del lenguaje al sector legal
En el IIC hemos desarrollado una metodología para la adaptación a diferentes dominios de modelos de lenguaje ya existentes. De esta forma, somos capaces de reajustar un modelo de lenguaje construido de manera generalista y adaptarlo al lenguaje de un sector concreto.
Este modelo de lenguaje adaptado al dominio se puede emplear como base con la que realizar el ajuste fino para los diferentes problemas del sector, consiguiendo así soluciones de mayor calidad. Concretamente y como primer resultado aplicable al sector de esta metodología, hemos creado el primer modelo del lenguaje en español adaptado al sector legal.
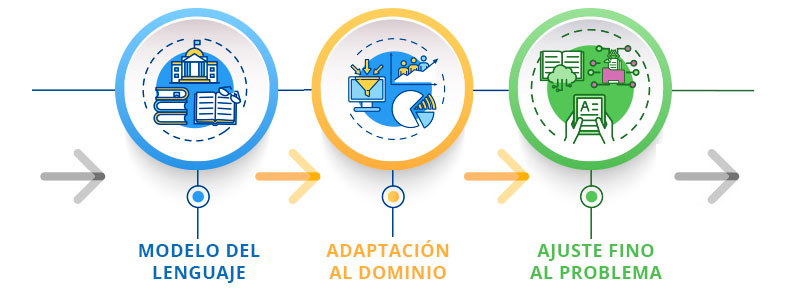
Para la creación de este primer modelo del lenguaje en español para el sector legal hemos partido de BETO, el modelo general del español desarrollado por la Universidad de Chile, y hemos realizado un proceso de adaptación a un gran corpus del español legal-administrativo, de más de 500 millones de palabras, en torno a un 25% del tamaño del corpus empleado por BETO.
Este corpus legal-administrativo ha sido recopilado en base a fuentes abiertas, para después ser curado por nuestro equipo de lingüistas computacionales y sometido a procesos de limpieza, garantizando así su calidad.

Resultados del modelo de lenguaje al sector legal
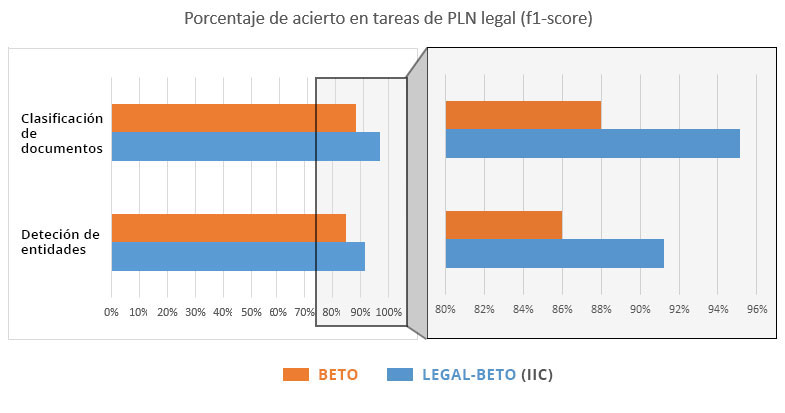
Las ventajas de contar con un modelo de lenguaje adaptado al dominio legal son claras una vez se pone en la práctica con dos problemas concretos del sector legal:
- Clasificación de documentos de varias páginas según tipología, en 8 categorías diferentes.
- Detección de entidades nombradas en el texto: personas y organizaciones.
La siguiente figura muestra los resultados experimentales sobre la ganancia en acierto obtenido al utilizar nuestra adaptación al sector legal del modelo de lenguaje (Legal-BETO IIC), en comparación con emplear el modelo del español general sin adaptación (BETO). La diferencia en acierto es significativa, permitiendo alcanzar cotas de rendimiento muy elevadas, lo que facilita el uso práctico y real de nuestras soluciones de PLN en el sector legal.
– Actualización a 2 de agosto de 2021 –
Dos días tras la publicación de este post, y bajo el paraguas del Plan de Impulso de las Tecnologías del Lenguaje de la Agenda Digital, se liberó de manera abierta el modelo RoBERTalex, enfocado también en el español utilizado en el dominio legal. Hemos añadido a los resultados los obtenidos por este modelo en los mismos problemas.
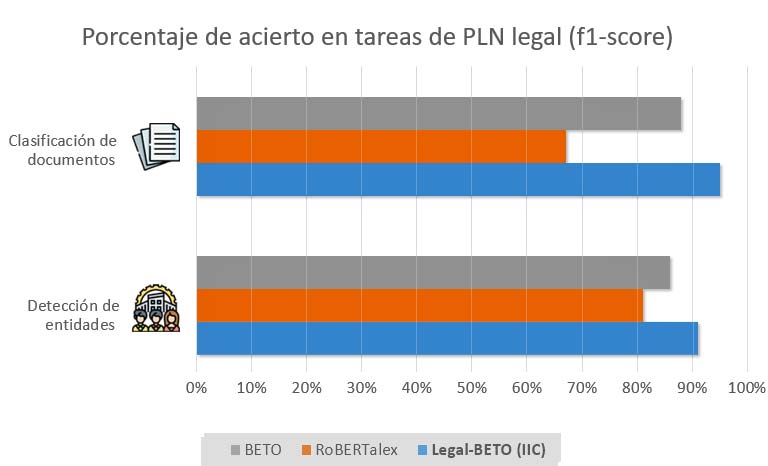
La diferencia en acierto obtenida por el modelo del IIC es significativa, permitiendo alcanzar cotas de rendimiento muy elevadas, lo que facilita el uso práctico y real de nuestras soluciones de PLN en el sector legal.
Adaptación de RigoBERTa a otros sectores
En nuestro proyecto de investigación RigoBERTa contamos con un equipo altamente especializado de científicos de datos, ingenieros informáticos y lingüistas computacionales.
Nuestro objetivo es continuar desarrollando modelos de lenguaje adaptados a diferentes dominios, así como modelos de lenguaje del español general de mayor calidad que los disponibles de manera abierta. Con esto pretendemos potenciar nuestras soluciones de PLN más allá del estado del arte actual en español, permitiendo así la creación de soluciones líderes en diversos sectores especializados.
¿Te interesa aplicar las técnicas de Procesamiento del Lenguaje Natural en tu sector?
