
El Procesamiento del Lenguaje Natural (PLN – Natural Language Processing (NLP)) es un campo de trabajo e investigación multidisciplinar que incluye lingüística, ciencias de la computación e inteligencia artificial, cuyo fin es estudiar las interacciones entre los lenguajes naturales (inglés, español, chino…) y los ordenadores.
Dentro del PLN, podemos hablar más concretamente de las técnicas de Natural Language Understanding (NLU – Comprensión de Lenguaje Natural), que incluyen tareas como la clasificación de textos (temática, de opinión o de emociones), la detección y relación de entidades (named entity recognition y named entity linking) o la extracción de información. Es en este último ámbito donde tiene cabida la detección de temas o topic extraction que trata este artículo, con un ejemplo del ámbito jurídico.

Figura 1. Temas de conversación en el marco de PLN.
¿En qué consiste la tarea de topic extraction?
La detección de temas, temáticas o topic extraction consiste en el procesamiento automático no supervisado de textos con el objetivo de identificar los asuntos o motivos sobre los que dichos textos versan. En otras palabras, mediante esta técnica de PLN es posible descubrir qué temas concretos se tratan en un conjunto de documentos, por ejemplo.
Aparte de los temas que subyacen a los datos en conjunto, es posible saber automáticamente de qué trata cada documento individual o la frecuencia con la que cada tema aparece. Además, la extracción de temas puede aplicarse sobre un conjunto de documentos para saber cuánto se parecen entre ellos o cuánto difieren entre sí, es decir, conocer si la muestra de datos es más heterogénea u homogénea temáticamente hablando.
La extracción de temas cobra especial relevancia cuando se ve enmarcada en un contexto concreto o en un área de conocimiento o negocio particular. Así, esta técnica es aplicable a infinidad de casos como, por ejemplo, saber qué temas se tratan en la filmografía española de los últimos 20 años, aspectos de los que hablan las opiniones de los usuarios de webs que valoran la satisfacción de un comercio o restaurante, tendencias y modas (dietas, ejercicio físico, hábitos, etc.) en redes sociales o asuntos de los que trata la legislación de un país (y de los que no) en un momento temporal concreto.
Cómo construir temas paso a paso con PLN
Pero, ¿cómo descubrir los temas que subyacen a un conjunto de datos? La extracción de temas puede dividirse en varios pasos que parten, como casi cualquier tarea de PLN, del procesado de los textos. La figura 2 resume los pasos a seguir en la extracción de temas.
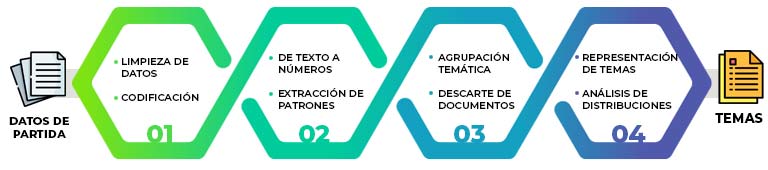
Figura 2. Proceso de extracción de temas.
El primer paso es la limpieza de los datos. El objetivo de esta fase es eliminar textos repetidos o comprobar la codificación de los mismos, es decir, observar si existe algún carácter que no se visualice correctamente o que no forme parte del idioma al que pertenecen los datos.
Tras la limpieza de los datos, el segundo paso es aplicar un algoritmo de extracción de temas. Este algoritmo funciona, a grandes rasgos, en tres fases:
 La primera fase consiste en traducir cada uno de los textos a su equivalente numérico (vectores). Así, las capas posteriores de procesado pueden extraer patrones del contenido de los textos sobre los que establecer comparaciones.
La primera fase consiste en traducir cada uno de los textos a su equivalente numérico (vectores). Así, las capas posteriores de procesado pueden extraer patrones del contenido de los textos sobre los que establecer comparaciones.
En la segunda fase, el algoritmo de extracción de temas establece dichas comparaciones entre los textos y forma grupos con aquellos textos que más se parecen temáticamente. Además, se genera otro grupo con los textos que no pertenecen específicamente a ninguno de los temas más salientes detectados, sino que constituyen menciones puntuales a aspectos diversos.
La tercera fase consiste en decidir qué términos son los más apropiados para representar el tema del que habla cada uno de los grupos de textos. Estos términos son la clave para poder interpretar, siempre dentro del contexto específico de análisis, la información extraída de los datos.
A continuación, se presenta un caso práctico aplicado al ámbito jurídico.
Caso de topic extraction: sentencias ‘millennial’ vs. sentencias ‘zentennial’
De acuerdo con el Real Decreto 181/2008, de 8 de febrero, “el «Boletín Oficial del Estado» (BOE), diario oficial del Estado español, es el medio de publicación de las leyes, disposiciones y actos de inserción obligatoria”[1].
El BOE contiene distintos tipos de documentos: leyes y reales decretos, sentencias, boletines oficiales de las Comunidades Autónomas o el Diario Oficial de la Unión Europea en español.
Así, a través del BOE se pueden detectar los temas que se tratan a nivel legal en un periodo de tiempo concreto. Para mostrar un ejemplo de aplicación de la extracción de temas en el ámbito jurídico, se han tomado las sentencias que aparecen en el BOE (Samy et al., 2020) en los años 1990, 1991 y 1992 por un lado (6,8 MB), y las de los años 2000, 2001 y 2002 (6,4 MB) por otro[2], con para obtenerlos temas que tratan y compararlos.
La tabla 1 muestra la cantidad de textos asociados a cada uno de los seis primeros temas extraídos para cada periodo. Los temas de la tabla 1 se encuentran ordenados de mayor a menor por volumen de textos, es decir, el tema 1 es el más frecuente dentro de los seis temas más frecuentes. En cambio, el tema 6 es el menos frecuente dentro del top seis de temas más frecuentes.
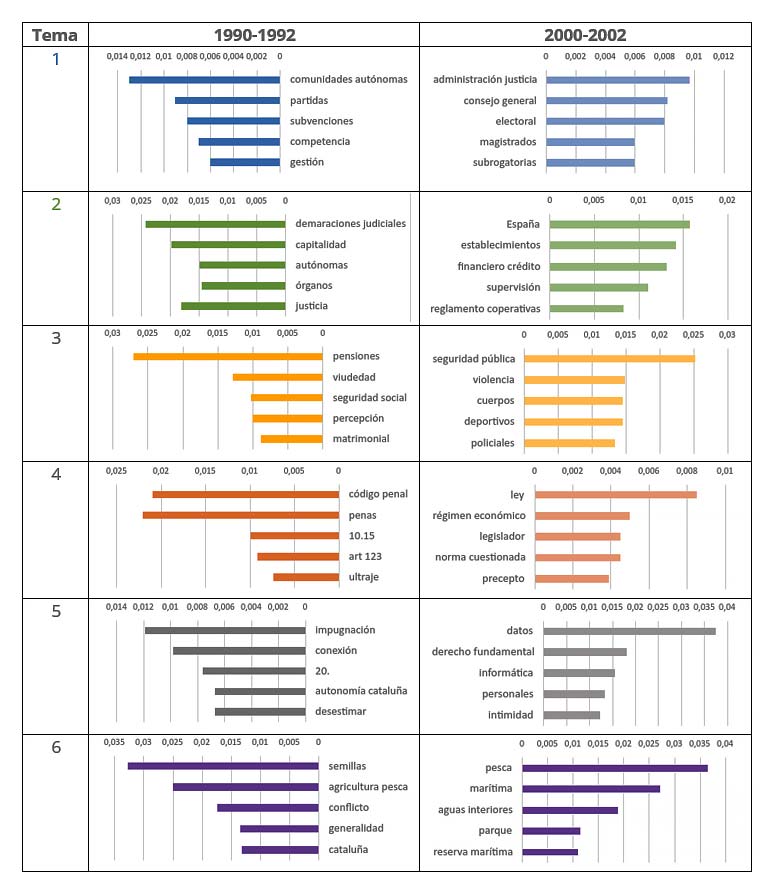
Tabla 2. Temas de conversación más frecuentes en sentencias del BOE en los periodos 1990-1992 y 2000-2002.
En vista de la información recogida en la tabla 2, se puede observar que las sentencias de principio de los noventa tratan aspectos relacionados con ayudas y subvenciones en las comunidades autónomas, demarcaciones judiciales de las autonomías o la percepción de pensiones de viudedad. Sin embargo, las sentencias de principio de los años 2000 hablan sobre el consejo economía, violencia en eventos deportivos o la protección de datos personales en el ámbito digital.
Es interesante señalar que las sentencias de ambos periodos temporales se hace mención a actividades del sector primario (tema 6), como muestran los ejemplos a continuación:
Ejemplo 1 (1990-1992)
El artículo 8. de la Orden del Ministerio de Agricultura, Pesca y Alimentación de 5 de noviembre de 1986 por la que se instrumenta la concesión de la prima en beneficio de los ganaderos de ovino y caprino, en tanto que atribuye al SENPA el pago de la prima, en virtud de las resoluciones favorables de los expedientes por las Comunidades Autónomas, ha invadido las competencias de la Generalidad de Cataluña, pues, de conformidad con lo expuesto en el precedente fundamento jurídico 5. no existe razón alguna constitucionalmente válida que justifique excepcionar la regla de ejecución descentralizada de las ayudas.
Ejemplo 2 (2000-2002)
En segundo lugar, también es preciso recordar que «la delimitación del título competencial «pesca fluvial» no puede ignorar, en absoluto, la inescindible conexión que existe entre el recurso natural objeto de esa actividad y en el medio en el que habita», por lo que, si bien «en esencia, el concepto pesca hace referencia a la actividad extractiva de recursos naturales en sí misma considerada, ésta comprende también, dado que es presupuesto inherente a esa actividad, el régimen de protección, conservación y mejora de los recursos pesqueros» (SSTC 15/1998, FJ 4, y 110/1998, FJ 2).
Además, atendiendo a las tablas 1 y 2 y al análisis de los datos, es posible conocer la presencia de cada uno de los temas en el conjunto de datos estudiado. Así, se puede saber que el 34% de las sentencias del BOE de principios de los 90 tratan sobre aspectos relacionados con las partidas presupuestarias destinadas a ayudas y subvenciones a las comunidades autónomas, o que ya a principios de los 2000 comenzaba a despuntar (menos del 2% de los textos) el tema de la protección de datos personales en el ámbito digital.
¿Extracción de topics supervisada o no supervisada?
La técnica descrita en este artículo hace referencia a la extracción no supervisada de temas. Una de las posibles reflexiones que surgen de la extracción de topics es si esta ha de ser siempre no supervisada o si, por el contrario, existen aproximaciones supervisadas para resolver la misma tarea.
Para contestar a esta pregunta parece necesario concretar en qué escenarios conviene aplicar técnicas de extracción de temas no supervisadas y en cuáles es preferible aplicar estrategias supervisadas.
La figura 3 muestra dos esquemas de extracción de temas: uno supervisado y otro no supervisado. En ambos casos se precisa una fase de modelado y una fase de análisis de los datos y del negocio. Así mismo, a través de sendos esquemas se obtiene una categorización de los datos. Sin embargo, es importante mencionar que las fases de cada una de las estrategias no siguen el mismo orden.
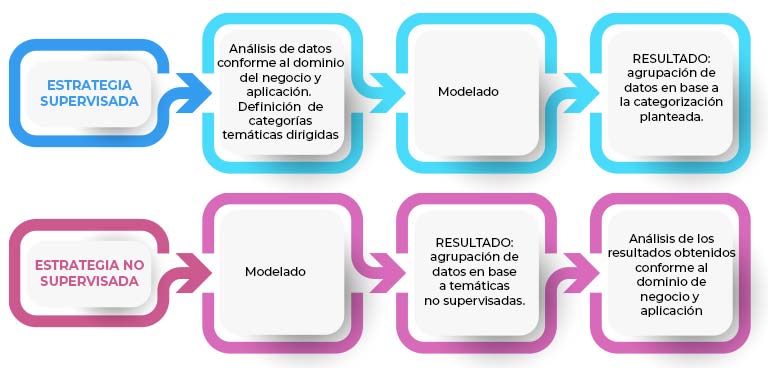
Figura 3. Esquemas de representación de estrategias de agrupación de textos supervisadas y no supervisadas.
Las estrategias supervisadas cobran mayor importancia cuando el conocimiento del negocio o del ámbito de aplicación es muy concreto. Así, la mayor carga de esfuerzo se concentra en definir las categorías que sobresaldrán de los datos. Los resultados esperados tras el modelado se encuentran dirigidos en base a las categorías predefinidas. En otras palabras, no se obtendrán resultados para todo aquello que no se ajuste a las categorías que hayan sido previamente definidas.
Las estrategias no supervisadas son más útiles cuando se buscan aspectos nuevos, desconocidos para el ámbito de aplicación de los datos. Por ello, el grueso del análisis recae en la interpretación de las agrupaciones obtenidas, puesto que pueden desvelar aspectos inesperados, a priori, para el área de negocio en cuestión.
Conclusiones sobre la extracción de topics
Una vez visto en qué consiste la extracción de temas y un caso concreto, se puede entrever su utilidad. Estas son las claves de esta tarea de PLN:
- La extracción de temas es una tarea de PLN que permite obtener información sobre los asuntos de los que trata un conjunto de datos.
- La extracción de temas puede ser supervisada (cuando el conocimiento del negocio o del ámbito de aplicación es muy concreto, con categorías predefinidas) y no supervisada (cuando se buscan aspectos nuevos, desconocidos para el ámbito de aplicación).
- Este artículo se centra en la extracción de temas automática y no supervisada, que reduce los costes en tiempo de revisión y análisis de los datos previos al modelado.
- Este tipo de extracción permite concretar los temas principales de los que trata un conjunto de datos, así como aspectos secundarios que subyacen a los mismos y que, a priori, pueden no ser tan evidentes.
- La extracción de temas es aplicable a diferentes ámbitos y marcos contextuales, lo que la convierte en una aproximación flexible y muy útil para diferentes áreas de negocio que buscan ampliar conocimiento y descubrir o revelar información sobre los datos de su ámbito particular.
Referencias
Samy, D., Arenas-García, J. & Pérez-Fernández, D. (2020). 2020. Legal-ES: A Set of Large Scale Resources for Spanish Legal Text Processing. En Proceedings of the First workshop on Language Technologies for Government and Public Administration (LT4Gov). Language Resources and Evaluation Conference (LREC 2020). 32-36. Marseille, 11–16 May 2020. Fecha de acceso: 14/02/2022.
[1] Artículo 1. https://www.boe.es/buscar/act.php?id=BOE-A-2008-2389&p=20210512&tn=1#a1
[2] Es importante mencionar que el BOE contiene solamente un subconjunto del total de sentencias que se publican. Las sentencias en su totalidad son publicadas por el Centro de Documentación Judicial (CENDOJ). Los resultados que se muestran en este post parten únicamente de las sentencias publicadas en el BOE en los periodos temporales definidos en el texto.
