
Las técnicas de Procesamiento del Lenguaje Natural (PLN) permiten automatizar procesos y extraer valor a partir de grandes volúmenes de texto. La extracción de temas de impacto en conversación online, por ejemplo, pretende detectar y caracterizar conversaciones concretas dentro de un conjunto de textos tan amplio como el que podemos extraer de las redes sociales.
La función principal de esta caracterización es, además de la comparativa de marcas, seguimiento de campañas, reseñas de productos o informes de reputación, descubrir hilos de conversación no evidentes e incipientes en torno a un tema de interés.
Un posible caso de uso de la caracterización de temas de conversación es el análisis de textos en redes sociales a través de Lynguo. Esta herramienta de monitorización y análisis de redes sociales nos permite descargar los datos necesarios, identificar los temas de conversación en torno a un interés, compararlos y etiquetarlos en los textos.
Configuración de la escucha y descarga de datos para el análisis de texto
El primer paso para la caracterización automática de temas de conversación es configurar la escucha y descargar los datos necesarios. Lynguo permite recoger la conversación en torno a un conjunto de palabras seleccionadas en medios sociales como Twitter, Facebook, blogs o medios digitales, analiza el sentimiento de los textos descargados y permite clasificarlos según una configuración personalizada.
 Las palabras a monitorizar se pueden organizar en “intereses” dentro de Lynguo, para después comparar los datos de cada conversación a través de su Dashboard y poder extraer insights. Es importante elegir bien las palabras de la escucha, ya que una palabra puede tener diferentes significados en distintos contextos. Esto ayuda a focalizar la escucha y minimizar el riesgo de ruido.
Las palabras a monitorizar se pueden organizar en “intereses” dentro de Lynguo, para después comparar los datos de cada conversación a través de su Dashboard y poder extraer insights. Es importante elegir bien las palabras de la escucha, ya que una palabra puede tener diferentes significados en distintos contextos. Esto ayuda a focalizar la escucha y minimizar el riesgo de ruido.
Si queremos conocer la conversación en redes sociales en torno a un tema concreto, por ejemplo, supermercados, descargamos los datos a través de Lynguo. En este caso, se han monitorizado en Twitter los supermercados Alcampo, AhorraMás y Eroski. La configuración de la escucha es sencilla en este ejemplo, ya que son nombres de marcas muy representativos que dejan poco lugar a contenido no deseado. Sin embargo, no todos los casos son así. Si quisiéramos extraer contenido de la ciudad de León, habría que filtrar otros contenidos que podrían traer ruido como “Seat León”, “Paco León” o el término “león” cuando hace referencia al animal. Para ello, el Instituto de Ingeniería del Conocimiento (IIC) cuenta con un equipo de lingüistas computacionales especialistas en procesamiento del lenguaje natural y desambiguación contextual.
Detección de temas de conversación con Machine Learning
Una vez que los datos se encuentran en la base de datos de Lynguo, se llevan a cabo diversos procesos de limpieza y preprocesado que se determinan y ajustan en función de las características de los textos. El borrado de información o URLs irrelevantes son ejemplos de los procesos de limpieza.
 Para la detección de la temática de conversación se usan técnicas de Machine Learning. Los temas de una conversación se extrae a partir de grupos de palabras característicos de esa conversación. Para obtener estos grupos de palabras que conforman cada uno de los temas detectados, son imprescindibles los modelos de aprendizaje automático no supervisado. Una vez se han parametrizado adecuadamente estos modelos, la función principal de los mismos es el perfilado temático de cada texto, es decir, la obtención de los titulares e ideas principales de la conversación monitorizada.
Para la detección de la temática de conversación se usan técnicas de Machine Learning. Los temas de una conversación se extrae a partir de grupos de palabras característicos de esa conversación. Para obtener estos grupos de palabras que conforman cada uno de los temas detectados, son imprescindibles los modelos de aprendizaje automático no supervisado. Una vez se han parametrizado adecuadamente estos modelos, la función principal de los mismos es el perfilado temático de cada texto, es decir, la obtención de los titulares e ideas principales de la conversación monitorizada.
Tras la obtención de los grupos temáticos de conversación, éstos se ordenan automáticamente de acuerdo a criterios de congruencia obtenidos a partir de los valores de frecuencia (número de veces que un término aparece en un texto) y relevancia de los términos que conforman la conversación. Por ejemplo, un término puede ser característico de una conversación tanto si aparece con mucha frecuencia con respecto a una conversación general del español, como si aparece muy poco. En el caso de una conversación gastronómica sobre la ciudad de León, el término “cecina” aparecerá con mucha más frecuencia que en una conversación general de gastronomía. Sin embargo, la frecuencia de aparición del término “calçots” será prácticamente nula.
Tras esta ordenación automática es necesaria la revisión por parte de un lingüista computacional, que comprueba que los resultados obtenidos a partir de los procesos de aprendizaje automático no supervisado se adaptan a las necesidades del cliente, del proyecto y a la naturaleza de los datos.
Volviendo a nuestro ejemplo de datos de supermercados, obtenemos los siguientes temas de conversación sobre el interés “Alcampo”, ordenados por orden de congruencia, de donde extraemos sus palabras más representativas:
| TEMAS DE CONVERSACIÓN | PALABRAS REPRESENTATIVAS DEL TEMA |
|---|---|
| 1. Comparativa de supermercados | Carrefour supermercado online más_barato alcampo mercadona la_ocu hipercor el_corte_inglés más_caro eroski caprabo cadena hacer_la_compra |
| 2. Ofertas de empleo | madrid empleo azafata trabajo alcampo ayudante pio xii vendedor reponedor sevilla profesional buscar cádiz pescadería panadería caja descripción_del_puesto |
| 3. Fiestas regionales | celebrar fiesta lugar tradicional acto aniversario feria la_virgen_de vino restaurante día recorrer calle antiguo entrada celebración año santo rincón cofradía |
| 4. Crecimiento de la empresa | crecer último año cifra total registrar respecto aumentar datos anterior superar alcanzar situar enero crecimiento mes trimestre españa parar incremento |
Tabla 1. Temas de conversación detectados en la monitorización de supermercados en Twitter.
Como se puede observar en la tabla 1., los temas de conversación extraídos pueden ser muy variados, yendo desde contenidos sobre la comparación de distintas cadenas de supermercados y sus servicios (opiniones, reseñas, artículos de prensa digital) hasta temas económicos como el crecimiento de estas empresas. Cabe destacar que se pueden descubrir otros temas de conversación imprevistos, como puede ser las fiestas regionales dentro de una conversación en torno a los supermercados, donde estos actúan como patrocinadores o localización de estos eventos.
Visualización de los temas de conversación en Lynguo
A través de nuestra herramienta Lynguo, es posible visualizar y estudiar los datos de cada tema de conversación. Una vez seleccionados los temas de conversación relevantes para el proyecto, se hace una correspondencia entre los temas elegidos y los textos descargados.
Lynguo permite la creación de tags (etiquetas) personalizados, que usamos en este caso para crear las etiquetas correspondientes a los temas de conversación elegidos. Los textos descargados son marcados con estas etiquetas y son almacenados en la base de datos de Lynguo.
A través de los filtros superiores de la interfaz web, es posible filtrar por cada tag y comparar las gráficas del Dashboard relativas a cada uno de ellos. Además, en la sección de Warehouse es posible ver las correspondencias entre cada texto y su tema de conversación asociado.
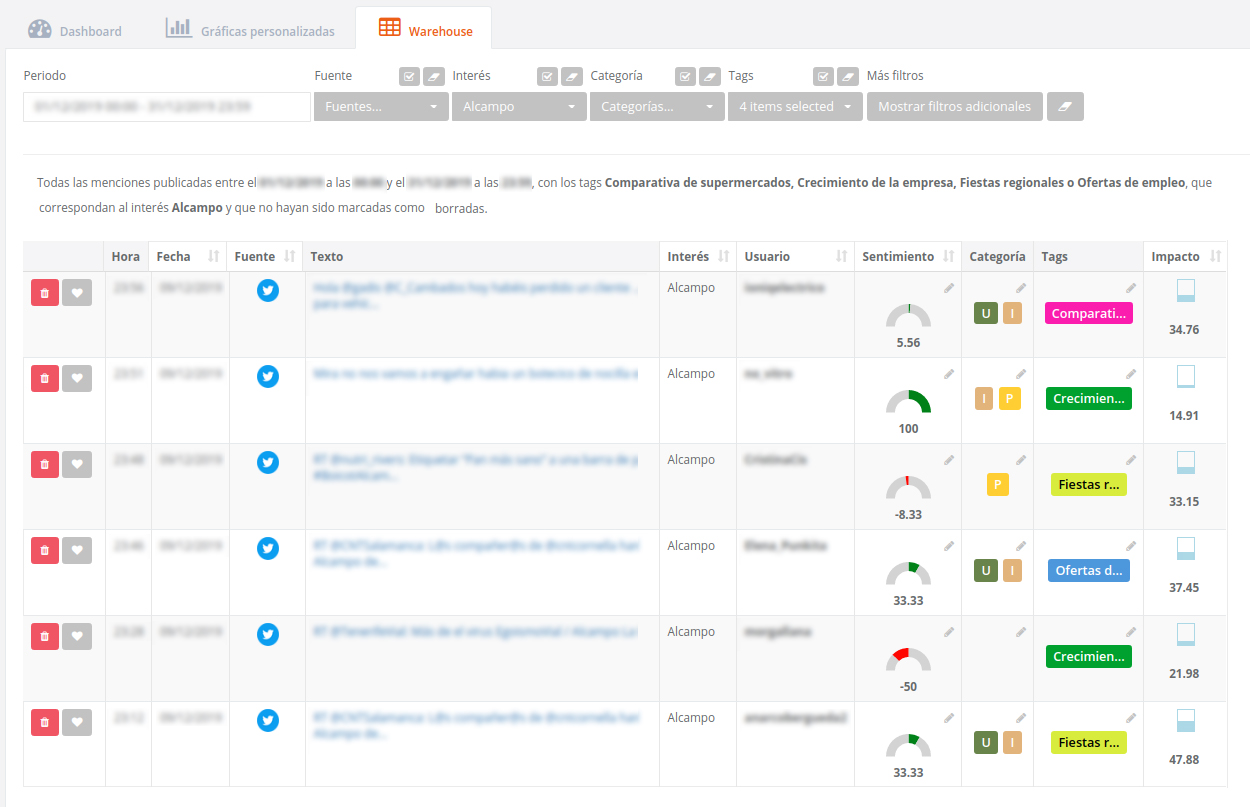
Esta imagen corresponde al Warehouse filtrando por los tags que corresponden a los temas de conversación. Se puede ver como a cada texto se le ha asignado un tema con un tag. Nota: los datos potencialmente sensibles se han ocultado para poder publicar este post.
En conclusión, gracias a nuestra herramienta de escucha de redes sociales Lynguo y al expertise de nuestras lingüistas computacionales e ingenieros de software somos capaces de segmentar la conversación de grandes volúmenes de textos en temas de conversación relevantes para nuestros clientes.
