
En el post ¿Cómo crear un chatbots con Machine Learning y PLN? vimos la importancia de los chatbots hoy en día, algunos tipos de bots que existen y nociones básicas para diseñar un asistente conversacional. La alta demanda de estas herramientas hace que las plataformas disponibles para crearlas sean cada vez más robustas y ofrezcan posibilidades de diseño más complejas que en el anterior post no vimos.
Para conocer un poco más las opciones que aportan a los chatbots plataformas como Watson Assistant o Dialogflow, vamos a ver dos de las estrategias conversacionales que ofrecen: las variables de contexto y los llamados slots. Ambos permiten gestionar y recopilar la información relevante del usuario y resultan prácticamente imprescindibles para crear un asistente avanzado.
Variables de contexto en chatbots
Las variables de contexto, también llamadas parámetros, sirven para almacenar información que el usuario va aportando a lo largo de la conversación y que puede resultar relevante para el posterior desarrollo de la misma. Es decir, estos datos almacenados pueden ser recuperados por el chatbot a lo largo del diálogo.

En las plataformas disponibles para diseñar asistentes conversacionales, las variables de contexto se identifican normalmente con el símbolo del dólar ($) delante. Su utilidad suele ser almacenar un valor de una entidad detectada en la respuesta del usuario, aunque también es posible activar o desactivar variables de contexto (asignándoles “true” o “false/null” como valor) o almacenar en ellas el input literal del usuario. Algunos ejemplos de uso de variables de contexto podrían ser:
- Almacenar el número de teléfono en una variable de contexto. Para ello, la respuesta del usuario debe contener un teléfono que haga saltar la entidad @telefono, y este será guardado en una variable de contexto llamada $teléfono.
- Activar una variable de contexto cuando el usuario hable sobre una campaña de marketing concreta. Para ello, cuando el usuario mencione dicha campaña que se quiere monitorizar, se detectará la entidad @c_marketing y la variable $c_marketing pasará a tener el valor “true”, indicándose, así, que en esa conversación se ha tratado esa campaña.
- Almacenar el nombre del usuario en la variable $nombre. Como no es posible tener una entidad con todos los nombres posibles, se guarda en $nombre la respuesta literal del usuario a la pregunta “¿Cómo te llamas?”.
Porque estás leyendo este post, te interesa leer también
Slots o ranuras para recopilar información en chatbots
 Por otro lado, los slots, también llamados ranuras o parámetros, son una estrategia conversacional para recopilar información del usuario y permiten poner en uso las variables de contexto. Aunque varía la manera de implementarlos según qué plataforma se utilice, los slots siempre van a buscar, en la respuesta del usuario, la información que se le indique y la van almacenar en una variable de contexto.
Por otro lado, los slots, también llamados ranuras o parámetros, son una estrategia conversacional para recopilar información del usuario y permiten poner en uso las variables de contexto. Aunque varía la manera de implementarlos según qué plataforma se utilice, los slots siempre van a buscar, en la respuesta del usuario, la información que se le indique y la van almacenar en una variable de contexto.
Existen slots obligatorios y opcionales. Estos últimos van a intentar detectar en el input del usuario la información para guardar en la variable de contexto; si está presente, la almacenan, y si no, el diálogo continúa. Sin embargo, los slots obligatorios tratan de recabar información imprescindible, por lo que esta debe ser almacenada en la variable para poder continuar con la conversación. Así, cuando la información a detectar por el slot no se encuentre en la respuesta del usuario, se le preguntará por dicha información hasta que la proporcione.
Existen otras estrategias para tratar datos obligatorios que, según el tipo de chatbot y la finalidad del mismo, pueden ser más apropiadas, pero es muy interesante conocer la opción de los slots porque ayudan a ahorrar tiempo y hacen que el asistente quede más condensado en menos nodos.
A continuación, se explica, mediante un ejemplo de conversación, cómo tratar información necesaria para el diálogo mediante subnodos (explicados en el anterior post) y mediante slots.
Cómo recopilar información imprescindible para el diálogo
Para explicar con un ejemplo práctico cómo funcionan las dos estrategias para recopilar información imprescindible para el diálogo, retomaremos el ejemplo que se utilizaba en el post ¿Cómo crear un chatbot con Machine Learning y PLN?: un asistente para una floristería. Para ello, vamos a considerar un posible diálogo con este chatbot:
Usuario: Me gustaría hacer un pedido.
En primer lugar, vamos a ver la estrategia de recopilación de información mediante subnodos. Tal y como se muestra en la Figura 1, este chatbot tiene cuatro nodos raíces: uno para cada intención a detectar (#horario, #direccion y #pedido) y otro de recuperación del diálogo. El nodo que salta cuando se detecta #pedido es el más complejo, pues, una vez activada la intención, entra por uno de sus cinco subnodos dependiendo de las entidades encontradas en el input del usuario. Por eso, para salir por el quinto subnodo (el que confirma el pedido), el asistente siempre tiene que haber recabado cierta información imprescindible: las entidades @producto y @flor, almacenadas en las variables $producto y $flor.
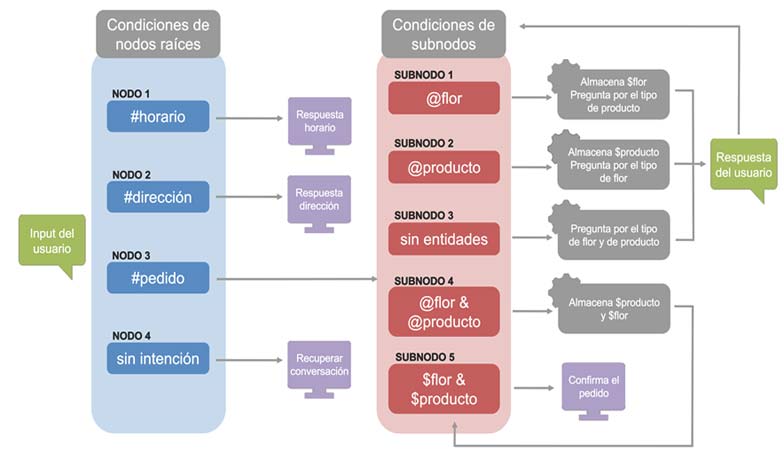
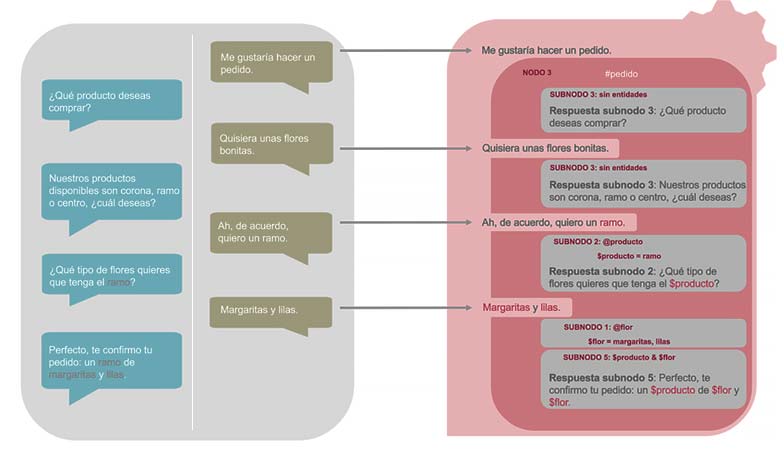
Esta conversación va avanzando según lo configurado en los nodos y subnodos, y de acuerdo con la información que el usuario va aportando en sus respuestas. Así, tal y como se observa en la Figura 2, el chatbot va guardando la información de las entidades en las variables de contexto para después acceder a ellas en la última respuesta, para confirmar el pedido.
Primeramente, accede al nodo 3 (#pedido), no encuentra entidades y, por tanto, entra por el subnodo 3 y pregunta por el tipo de producto que desea el usuario. Como tampoco encuentra @flor ni @producto en la respuesta del usuario, vuelve a acceder al subnodo 3 y a preguntar por lo mismo. En este caso, el usuario sí responde con el tipo de producto que quiere, por lo que el asistente entra al subnodo 2 al reconocer la entidad @producto, almacena la variable $producto y pregunta por el tipo de flor. En su respuesta, el usuario indica margaritas y lilas, esto activa el subnodo 1, hace que se guarde la variable $flor y activa la salida del nodo 3 mediante la respuesta del subnodo 5, que confirma el pedido.
 La estrategia de subnodos con distintas condiciones para recabar información imprescindible en la conversación puede ser muy útil en algunos casos. Sin embargo, existe la posibilidad de conseguir el mismo objetivo mediante los slots. Por eso, es fundamental conocer ambas estrategias para decidir cuál conviene cada vez.
La estrategia de subnodos con distintas condiciones para recabar información imprescindible en la conversación puede ser muy útil en algunos casos. Sin embargo, existe la posibilidad de conseguir el mismo objetivo mediante los slots. Por eso, es fundamental conocer ambas estrategias para decidir cuál conviene cada vez.
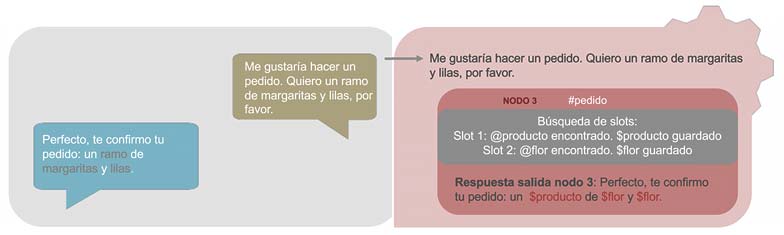
Como hemos dicho, se podría tener la misma conversación que acabamos de ver, pero con slots obligatorios. En este caso, como se muestra en la Figura 3, el asistente solo tendría cuatro nodos. El tercer nodo, el de #pedido, sigue siendo el más complejo, esta vez porque contiene los slots para intentar detectar las entidades @producto y @flor. Cuando estas entidades se han detectado y, por tanto, se ha guardado la información en las variables de contexto, los slots dejan de entrar en funcionamiento. Así, del nodo 3 se sale únicamente cuando las variables de contexto $producto y $flor contienen la información aportada por el usuario sobre @producto y @flor.
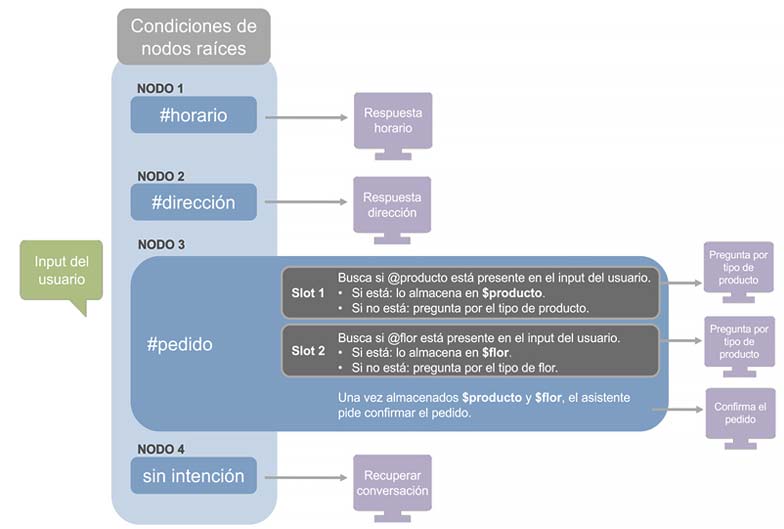
En la Figura 4 se puede apreciar cómo el asistente gestiona las respuestas del usuario cuando se encuentra en un nodo que contiene slots. En este caso, ambos slots son obligatorios, por eso, siempre que al chatbot le faltan variables de contexto que rellenar, sigue preguntando para completar tales variables. Por tanto, solo se sale de un nodo con slots obligatorios cuando todos y cada uno de los slots han sido activados y se ha almacenado información en sus variables de contexto. Siguiendo el ejemplo, mientras se esté dentro del nodo 3, los slots van a estar buscando rellenar las variables de contexto que continúen vacías. Así, hasta que el chatbot no tiene las variables $producto y $flor con datos, no se sale del nodo 3 con la respuesta de salida.
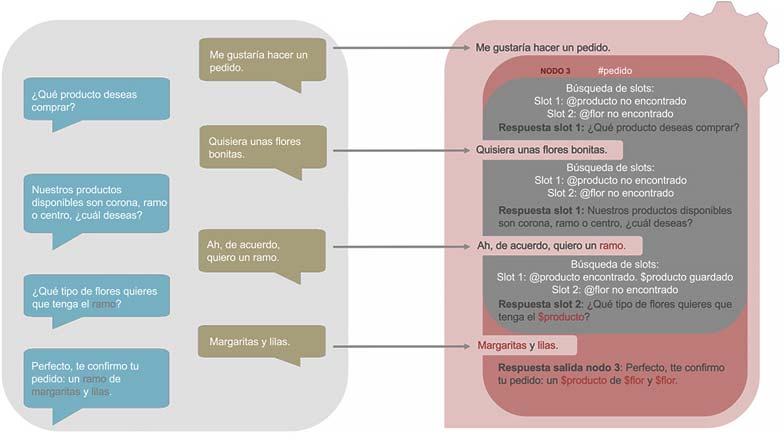
Si la conversación que se mantuviese con el asistente fuera diferente, el recorrido por los slots también lo sería. Por ejemplo, imaginemos que el usuario dice directamente: “Me gustaría hacer un pedido. Quiero un ramo de margaritas y lilas, por favor”. En este caso, también se detecta la intención #pedido y, por tanto, el diálogo entra en el nodo 3. Sin embargo, tal y como se muestra en la figura 5, los slots detectan en esa respuesta las entidades @producto y @flor. Por tanto, registran estos datos en sus correspondientes variables y obvian preguntar al usuario por alguno de ellos. Así, la conversación con el chatbot se reduce a dos interacciones.
Otro ejemplo sería si el usuario proporcionara la información para $flores, pero no para producto: mediante el segundo slot se almacenaría esta información, y el slot 1 haría que se preguntase por el tipo de producto. Como estas conversaciones podríamos imaginar cientos de otras y el recorrido del diálogo estará siempre determinado por la información que el usuario dé en sus inputs.
Conclusiones sobre el uso slots o nodos como estrategias conversacionales
Con estos ejemplos hemos intentado explicar de una manera más sencilla cómo es el funcionamiento de los slots, en los que siempre van a estar presentes las variables de contexto. Se trata de una estrategia conversacional que puede suplir en muchos casos a los subnodos, pues de ambas maneras se puede gestionar información relevante para el diálogo y que el usuario puede no proporcionar de primeras por no considerarla importante.

Como todo, cada una de estas formas de gestionar una conversación tiene sus ventajas y sus desventajas. Por un lado, el uso de slots permite ahorrar tiempo en el diseño del diálogo y que este sea más compacto, con menos nodos. Además, al evaluarse todos los slots por igual y sin orden (tanto los obligatorios como los opcionales), la recolección de datos en variables es más flexible.
Por otro lado, no hay que olvidar la utilidad de los subnodos para resolver este tipo de necesidades conversacionales. Aunque es cierto que tanto las dimensiones como la complejidad del chatbot aumentan cuando decidimos utilizarlos, también pueden resultar muy útiles si queremos recopilar la información con condiciones más sofisticadas y complejas (tanto condiciones de entrada como de salida de los subnodos). También es relevante que, mediante los subnodos, es posible almacenar las variables con un orden concreto, cosa que con los slots no es posible porque se evalúan todos a la vez sin distinción.
Y esto es todo sobre cómo recopilar información mediante variables de contexto, slots y subnodos; habrá que evaluar bien cuál es la opción más idónea para cada caso, haciendo un análisis de qué datos se quieren recopilar, cómo y de qué manera. En el siguiente post, abordaremos la estrategia de las digresiones conversacionales para intentar que nuestro asistente genere conversaciones más naturales.
