El Procesamiento del Lenguaje Natural (PLN) es una de las ramas del Machine Learning que más atención ha recibido en los últimos años, tanto por parte de la comunidad científica como por parte de las empresas, que ven en sus técnicas un arma para diferenciarse de la competencia, automatizar procesos, mejorar sus productos y conocer mejor a sus clientes, entre otros.
Algunas de las aplicaciones del PLN más conocidas son la generación de textos, detectar automáticamente entidades (Named Entity Recognition o NER) o clasificar textos, aunque hay muchas más. Esta versatilidad del NLP, y su aplicabilidad a múltiples problemas del mundo real en numerosas disciplinas, resalta la importancia de estas técnicas para diferentes sectores. Además, la investigación en nuevos modelos, especialmente los Transformers, ofrece nuevas posibilidades y está mejorando sus resultados al tener en cuenta el contexto.
La evolución del PLN
El Procesamiento del Lenguaje Natural ha evolucionado enormemente en los últimos años, y es que un investigador difícilmente podría imaginarse hace diez años el estado del arte en el que nos encontramos actualmente. En aquel momento, la forma típica de enfrentarse a un problema de análisis de texto era obteniendo variables del texto del tipo Bag of Words (BoW), las cuales se utilizaban como entrada de un modelo de Machine Learning.
Con la explosión del Deep Learning a mediados de la última década, así como con la irrupción de los embeddings (representaciones matriciales estáticas del texto, en las que cada palabra del vocabulario está codificada en un vector), las técnicas de PLN cada vez contaban más con el propio texto como fuente de entrada de un modelo. Así, los modelos basados en Redes Neuronales Recurrentes que hacían uso de embeddings se convirtieron en el estándar, al menos hasta finales del año 2017, pues eran capaces no sólo de tener en cuenta el significado general de cada palabra, sino también la posición de las mismas en la frase.
Esquemáticamente, el funcionamiento de estas Redes Neuronales Recurrentes se puede ver en la siguiente figura, donde se aprecia cómo se va generando una representación del documento completo a base de ir mezclando los embeddings (las x en la figura), de forma incremental, en un solo vector, explotando la naturaleza secuencial de los datos de texto.
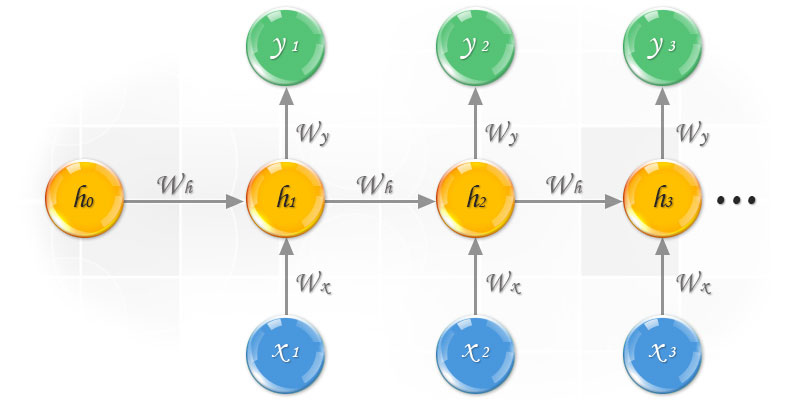
Fuente: https://towardsdatascience.com/recurrent-neural-networks-d4642c9bc7ce
La irrupción de los Transformers en PLN
En un paper de Google de finales del año 2017 -“Attention is All You Need”- se presentó la arquitectura del Transformer, un modelo que tenía como principal innovación la sustitución de las capas recurrentes, como las LSTMs que se venían usando hasta ese momento en PLN, por las denominadas capas de atención.
Estas capas de atención codifican cada palabra de una frase en función del resto de la secuencia, permitiendo así introducir el contexto en la representación matemática del texto, motivo por el cual a los modelos basados en Transformer se les denomina también Embeddings Contextuales.
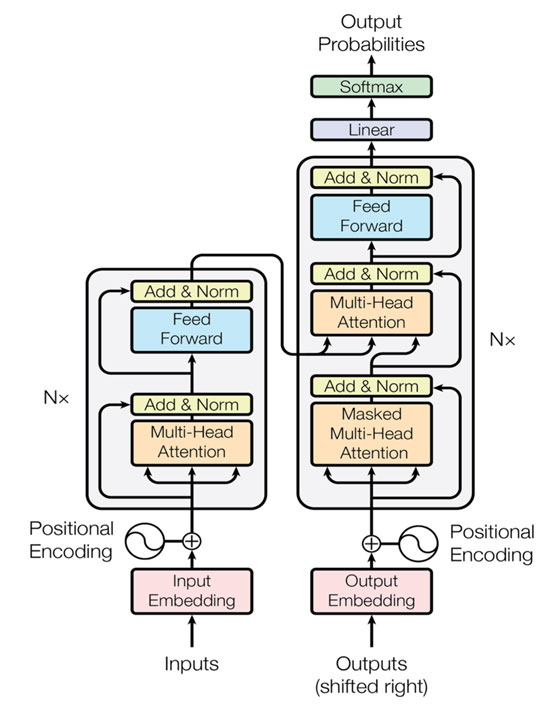
Fuente: https://arxiv.org/abs/1706.03762
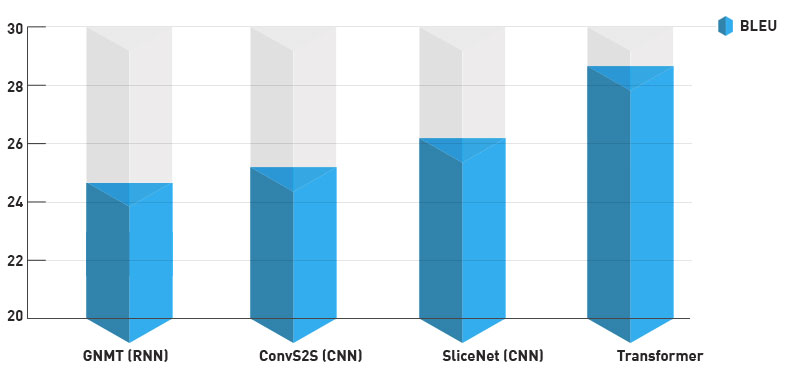
La arquitectura de Transformer incluye otras innovaciones, como los embeddings posicionales, que permiten al algoritmo conocer la posición relativa de cada palabra del texto. Además, en el paper original se examina la aplicación de esta arquitectura a tareas de traducción, demostrando ser mucho más efectiva que los métodos anteriores en este aspecto, como se puede ver en el gráfico inferior.
¿Cómo se trabaja con los Transformers?
Con Transformers, se suele trabajar en dos fases:
- Pre-training. En esta fase, el modelo aprende cómo se estructura el lenguaje de forma general, además de conseguir un conocimiento genérico del significado de las palabras. Esto se hace de manera parecida a los exámenes de idiomas, resolviendo “ejercicios” en los que el modelo tiene que predecir qué palabra o palabras faltan en una frase.
- Fine-tuning. Una vez están pre-entrenados, se le añaden ciertas capas a la arquitectura para adaptar los modelos a tareas concretas, y se los re-entrena en esas tareas.
El avance de los Transformers, así como su implantación de uso, están siendo posibles gracias a grandes volúmenes de texto en diferentes idiomas disponibles gratuitamente en Internet, así como al aumento de las capacidades de cómputo de los últimos años.
¿Cuál es el futuro de los Transformers?
Estos modelos avanzan hacia arquitecturas progresivamente más grandes, que son entrenadas con la mayor cantidad de textos posibles. La obtención del mejor modelo de lenguaje se ha convertido en una competición entre los grandes jugadores del mercado. De esta se beneficia la comunidad científica al completo pues, en general, están liberando los modelos obtenidos.
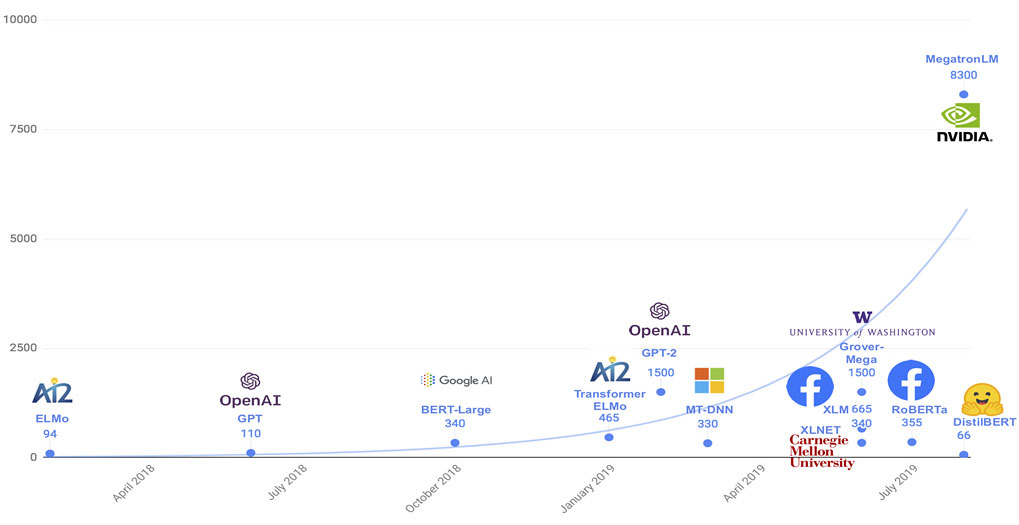
Fuente: https://www.kdnuggets.com/2020/02/microsoft-open-sources-zero-deepspeed-language-model.html
Una línea de investigación que también está atrayendo mucha atención es la relativa a intentar hacer modelos basados en la arquitectura de Transformer que sean más ligeros sin sacrificar efectividad, a la vez que permitan codificar secuencias de texto más largas, pues las principales limitaciones para su aplicación general son el extensivo uso de los recursos del ordenador y su tamaño limitado de secuencia. En esta línea, se están desarrollando modelos como el Reformer o los Compressive Transformers.
Aplicación de los Transformers en el IIC
En el Instituto de Ingeniería del Conocimiento (IIC) estamos a la vanguardia en los avances de la Inteligencia Artificial en sus diferentes campos, siendo el PLN una de las ramas que más atrae nuestra atención por los diversos usos que tiene. Por ello, estamos investigando la aplicación de los Transformers a diferentes tareas de análisis de texto, con el objetivo de ofrecer a nuestros clientes soluciones de calidad exquisita, a la altura del estado del arte.
Estas investigaciones se están usando internamente para mejorar nuestros servicios de PLN, como el análisis del sentimiento o la clasificación automática de textos. Como siempre, en el IIC tratamos de extraer el máximo valor de las investigaciones que realizamos para aportar aplicaciones de negocio innovadoras y efectivas, y el PLN es una de nuestras especialidades. Por ello, esperamos que la satisfacción de nuestros clientes vaya en aumento con la integración de los servicios basados en Transformers.
Nuevo estado del arte: versatilidad de los transformers en PLN
Desde su irrupción en el paradigma del PLN, los modelos basados en la arquitectura de Transformer se han convertido en el nuevo estado del arte en tareas de análisis de texto, siendo así la familia de modelos que mejores resultados han obtenido en las diferentes aplicaciones de NLP: generación de textos, resumen de textos, identificación de entidades, clasificación de documentos, responder a preguntas, desambiguación de términos, etc.
Son algoritmos de propósito general, debido a la fase de pre-entrenamiento comentada previamente, por lo que tienen una gran versatilidad para adaptarse a las diferentes tareas de análisis de texto, pudiendo tener así un uso muy amplio y simplificando la movilidad y la transición de unas tareas a otras.
La investigación en estos algoritmos está avanzando rápidamente, además de estar evolucionando hacia modelos más compactos, con menos requisitos de capacidad de cómputo y capaces de gestionar secuencias de texto más largas. Por ello, se espera que cada vez podamos aplicar estas arquitecturas a más tareas de análisis de texto con una mayor efectividad, así como que se democratice y generalice el uso de estos algoritmos.

Hola, existen sistemas que detecten automaticamente frases sexistas mediante el uso de transformen en el PLN?
Hola, ya se puede aplicar Transformers para realizar análisis de sentimientos?