
Cada día estamos expuestos a multitud de estímulos y contenidos informativos que llegan hasta nuestros ojos y oídos desde diversas fuentes, por ejemplo, libros, prensa escrita o contenidos audiovisuales (redes sociales, televisión, radio, podcasts, plataformas de streaming, etc.). Pero ¿qué pasaría si un alto porcentaje de esa información no fuera accesible para ti? De esta necesidad de romper las barreras informativas y de facilitar el acceso a todo tipo de contenidos escritos surge la Lectura Fácil (LF).
Este post trata de poner el Procesamiento del Lenguaje Natural (PLN) al servicio de la LF. Por un lado, a través de la generación automática de textos adaptados y, por otro, con la evaluación automática de textos en LF, para lo que el IIC ha desarrollado una herramienta que agiliza esta labor.
¿Qué es la Lectura Fácil?
Según recoge García Muñoz (2012), existen distintas definiciones de Lectura Fácil (LF). La International Federation of Library Associations and Institutions (1997) dice que la LF tiene que ver con la adaptación lingüística de un texto con el fin de hacerlo más fácil de leer, pero no más fácil de comprender. Por otro lado, el Grupo Educación y Diversidad (EDI) propone en 2009 una definición más global, por la que la LF se define como un planteamiento general sobre la accesibilidad a la información y a la comprensión de los mensajes escritos de las personas con diversidades intelectuales y de aprendizaje.
Más recientemente, Discapnet (2022) llama Lectura Fácil a aquellos contenidos resumidos y realizados con lenguaje sencillo y claro, de forma que puedan ser entendidos por personas con discapacidad cognitiva o discapacidad intelectual, personas con baja formación cultural o problemas de tipo social. En resumen, la LF trata de democratizar y hacer accesible la información adaptando contenidos (generalmente escritos) a las necesidades lingüísticas de colectivos que presentan dificultades asociadas al lenguaje.
La Lectura Fácil (LF) adapta contenidos a muchos niveles. A nivel lingüístico, considera elementos como los presentados en la figura 1, pero también elementos visuales como imágenes, dibujos o pictogramas que facilitan la asociación de ideas y la comprensión a nivel global. La LF también trata elementos de diseño y maquetación como la tipografía, el espaciado y la composición de la información, así como asuntos formales como la inclusión de logos e información de contacto de asociaciones de LF y apoyos informáticos disponibles.
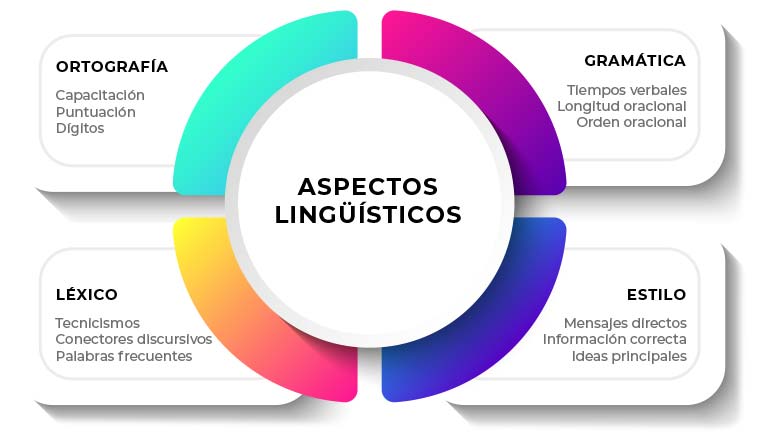
Figura 1. Resumen de aspectos lingüísticos que tiene en cuenta la LF
A continuación, se presentan tres pares de textos en sus versiones originales (izquierda) y adaptadas a Lectura Fácil (derecha). El ejemplo 1 contiene un fragmento del inicio de El niño con el pijama de rayas en versión original (Boyne, 2006) y adaptada a LF (Huesca, 2009). El ejemplo 2 es una noticia tecnológica en versión original (Martí, 2021) y en LF (Hinojosa, 2022). El ejemplo 3 es una sentencia de constitución de apoyos para el ejercicio de la capacidad jurídica de una persona en versiones original y LF.

Generación automática de textos en Lectura Fácil
La redacción de textos en Lectura Fácil (LF) es costosa en tiempo y necesita de personal cualificado a distintos niveles. Del mismo modo que sucede con las técnicas de traducción automáticas, la generación automática de textos puede servir de herramienta de apoyo a los redactores especializados en LF: los modelos de lenguaje actuales del estado del arte como MT5 (Xue et al. 2021), GPT-4 (OpenAI. 2023) o Falcon (Technology Innovation Institute. 2023) son muy útiles para generar una versión preliminar el texto en LF que, posteriormente, es corregida por redactores humanos.
Esta metodología de trabajo está ampliamente extendida en el ámbito de la traducción y cuenta con multitud de beneficios como, por ejemplo, reducir el tiempo de generación de nuevos textos adaptados, generalizar la adaptación de contenidos que hoy en día se ve reducida a algunas publicaciones especializadas o que los redactores puedan centrarse en los casos realmente complejos de adaptar por tratarse de ámbitos especializados (sentencias o informes médicos). A continuación, se muestra un ejemplo de cómo el Procesamiento del Lenguaje Natural (PLN) puede servir para generalizar y hacer más accesibles los contenidos publicados en Lectura Fácil.
El ejemplo 4 es una noticia publicada en la web de Plena Inclusión Madrid. El ejemplo 5 es la adaptación a lectura fácil del ejemplo 4 escrita por un redactor humano. Los ejemplos 6 y 7, que veremos después, son adaptaciones a LF del ejemplo 4, pero esta vez escritos por los modelos de generación de lenguaje GPT-3 y GPT-4.

Ejemplo 4. Noticia Plena Inclusión Madrid publicada el 18.10.2022

Ejemplo 5. Noticia Plena Inclusión Madrid publicada el 18.10.2022 adaptada a LF
Como apuntábamos, los ejemplos 6 y 7 han sido escritos mediante distintas técnicas de generación de texto. Para generar el ejemplo 6 se ha recabado un corpus de noticias de distintas comunidades autónomas publicadas por Plena Inclusión. Este corpus está compuesto por 400 pares de noticias originales y sus adaptaciones en LF que son utilizados para ajustar un modelo de lenguaje GPT-3. Con este modelo, se realizan predicciones sobre noticias originales para que genere la versión en Lectura Fácil (LF), como ilustra el ejemplo 6. Sin embargo, el ejemplo 7 ha sido generado a partir ChatGPT (modelo GPT-4) en base a unas instrucciones concretas de redacción en LF basadas en García Muñoz (2012), por ejemplo, incidiendo en el uso oraciones cortas o evitando la polisemia.

Ejemplo 6. Noticia Plena Inclusión Madrid adaptada a LF con GPT-3

Ejemplo 7. Noticia Plena Inclusión Madrid adaptada a LF con GPT-4.
A la hora de comparar los ejemplos 6 y 7 contra el ejemplo 5, redactado por un humano, se puede apreciar que el ejemplo 6 imita mejor la forma de redactar de una persona, tanto en expresión como en longitud del texto. Sin embargo, el ejemplo 7 incluye información más detallada que sí aparece en la versión original de la noticia (véase ejemplo 4). Pero ¿cómo saber si los textos generados tanto por humanos como por medios tecnológicos se adaptan a las pautas de redacción de Lectura Fácil? En la siguiente sección se presenta un analizador de textos en LF desarrollado en el IIC.
Analizador automático de Lectura Fácil desarrollado en el IIC
Para redactar un texto en versión Lectura Fácil (LF), los revisores de LF generan una versión del texto original que es evaluada, generalmente, en base a rúbricas, como la ilustrada en la figura 2. A partir de estas evaluaciones manuales se comprueba si aparecen o no ciertos aspectos formales, lingüísticos, etc., por ejemplo, los superlativos. Este proceso conlleva una importante inversión de tiempo, lo que impacta directamente en el coste de la generación de contenido de calidad en LF, la tipología de contenidos que se adapta a LF y la frecuencia con la que estas adaptaciones pueden ser publicadas.

Figura 2. Rúbrica de evaluación (Rivero-Contreras y Saldaña. 2019)
Con idea de facilitar la tarea de evaluación de la adecuación de textos a su versión en Lectura Fácil, el Instituto de Ingeniería del Conocimiento (IIC) ha desarrollado una herramienta para el análisis automático de aspectos lingüísticos. Dicho analizador comprende índices recogidos en la literatura del estado del arte sobre qué características lingüísticas han de tener los textos adaptados a LF para facilitar la comprensión de la información que contienen.
Esta herramienta utiliza técnicas de PLN para extraer información sobre los textos y poder calcular así distintas métricas en base a cuatro grandes pilares:
- la extensión oracional,
- la puntuación,
- la complejidad léxica
- y la complejidad sintáctica.
Cada uno de estos pilares de análisis está compuesto por distintos subíndices que analizan características particulares de los textos. Por ejemplo, en el caso del análisis de la puntuación, la métrica global de puntuación que proporciona la herramienta se sustenta sobre los subíndices que analizan el uso de las comas, puntos y coma o de las comillas, entre otros.
Resultados del análisis de textos en Lectura Fácil
Para ilustrar el funcionamiento del analizador de lectura fácil del IIC, se presentan cuatro gráficas obtenidas en base al análisis de los ejemplos 1-3. En el eje de abscisas de cada una de estas gráficas se encuentran los seis textos analizados: ‘Novela’ y ‘Novela_LF’ hacen referencia a los extractos de El niño con el pijama de rayas; ‘Noticia’ y ‘Noticia_LF’ y ‘Sentencia’ y ‘Sentencia_LF’ hacen mención a la noticia tecnológica y a la sentencia, respectivamente. En el eje de ordenadas se representa el valor obtenido para cada métrica global.
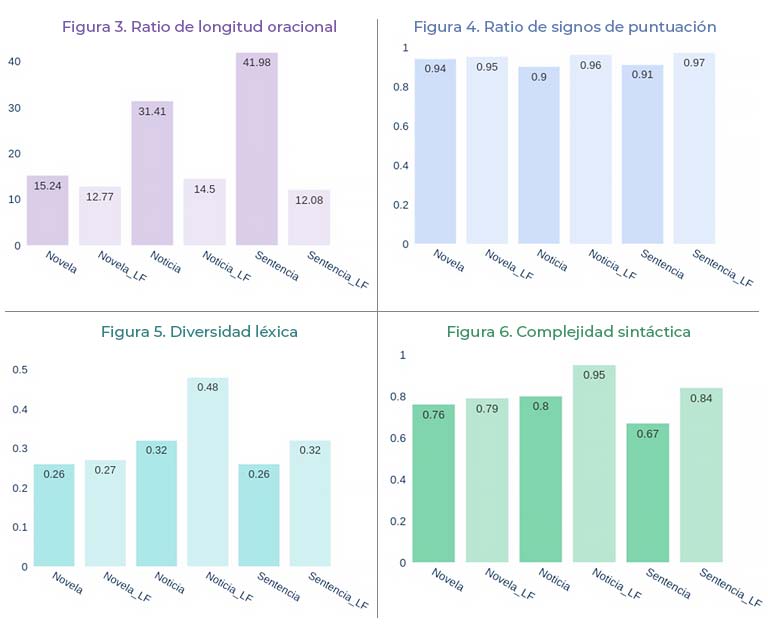
La figura 3 muestra la ratio de palabras por oración para los ejemplos 1-3. Los textos originales contienen una ratio de palabras por oración más elevada que las adaptaciones a LF, que no superan las 15 palabras por oración de media. Cabe destacar que la ratio para la novela original se encuentra mucho más cercana de los textos en LF que la de la noticia y la sentencia originales, compuestas por oraciones más largas.
La figura 4 muestra la ratio de puntuación para cada texto. De acuerdo con esta ratio, cuanto más cercano es el valor obtenido a 1, más sencillo de interpretar es el texto en lo que a puntuación se refiere. Las versiones LF superan los 0.95 puntos. Los textos originales alcanzan como máximo 0.94 puntos.
La figura 5 muestra la ratio de diversidad léxica. La diversidad léxica tiene en cuenta la presencia de palabras léxicas diferentes que incluye un texto. La diversidad léxica es un ejemplo del tipo de factores que componen el eje de análisis léxico de los textos. Un texto con un índice de diversidad léxica cercano a 0.5 es más sencillo de comprender que un texto con una diversidad léxica que se aproxima a 0 (o bien muchas de sus palabras son iguales, generando redundancia, o bien muchas de sus palabras son diferentes). En la figura 5, la noticia en LF tiene un índice de diversidad léxica de 0.48. A 0.16 puntos se encuentran la noticia original y la sentencia en LF. Los textos con un índice de diversidad léxico más bajos y, por tanto, más complicados de leer, son la novela en sus dos versiones y la sentencia original.
 Por último, la figura 6 muestra la ratio de complejidad sintáctica oracional. Esta métrica tiene en cuenta el uso de la coordinación, yuxtaposición y subordinación, entre otros. Los valores cercanos a 1 indican que el texto es más sencillo de comprender, mientras que los cercanos a 0 muestran que el texto es sintácticamente más complicado. La gráfica 6 refleja que los textos en LF se encuentran por encima del 0.79 de complejidad sintáctica, siendo la noticia en LF el texto más sencillo de comprender. En contrapartida, la sentencia original es el texto más complejo de comprender sintácticamente hablando.
Por último, la figura 6 muestra la ratio de complejidad sintáctica oracional. Esta métrica tiene en cuenta el uso de la coordinación, yuxtaposición y subordinación, entre otros. Los valores cercanos a 1 indican que el texto es más sencillo de comprender, mientras que los cercanos a 0 muestran que el texto es sintácticamente más complicado. La gráfica 6 refleja que los textos en LF se encuentran por encima del 0.79 de complejidad sintáctica, siendo la noticia en LF el texto más sencillo de comprender. En contrapartida, la sentencia original es el texto más complejo de comprender sintácticamente hablando.
Así, esta herramienta se presenta como un complemento de mucha utilidad para la redacción y evaluación de textos en LF. El redactor accede en un golpe de vista a información como la presentada en las gráficas 3-6 que facilita y agiliza el proceso de revisión de los textos a evaluar, señalando aspectos lingüísticos a reescribir y poniendo el foco en aquellos aspectos de los textos originales que pueden resultar un escoyo a la hora de generar una adaptación de calidad.
¿Qué puede aportar el PLN a la Lectura Fácil?
La Lectura Fácil (LF), su aplicación y la adaptación de textos son uno de los medios que favorecen la democratización de la accesibilidad a la información. El contenido escrito accesible y de calidad fomenta la inclusión en distintos planos de la vida social, personal y laboral de las personas con algún tipo de afectación que implique al lenguaje. La publicación de contenido en lectura fácil se convierte así en una necesidad para la mejora de la calidad de vida de muchas personas. Sin embargo, la creación manual de dicho contenido es un proceso que consume muchos recursos.
Con idea de mejorar la accesibilidad de contenidos, reducir tiempos y costes de publicación, en este artículo se ha explorado la posibilidad de utilizar técnicas de PLN y sacarles partido a los modelos de lenguaje del estado del arte para la generación automática de textos adaptados en LF de manera más ágil, permitiendo a los redactores centrar sus esfuerzos en los casos más complejos y reduciendo tiempo de adaptación. Además, se presenta un evaluador de LF desarrollado en el IIC que permite conocer automáticamente qué aspectos lingüísticos de los textos son mejorables, reduciendo el tiempo y esfuerzo de análisis.
Referencias
Boyne, J. (2006). El niño con el pijama de rayas. http://www.ieselpicacho.es/biblioteca/wp-content/uploads/2016/01/El-nino-con-el-pijama-de-rayas-John-Boyne.pdf Fecha de acceso: 09.05.2023.
CADIS HUESCA (2009). El niño con el pijama de rayas. https://docs.google.com/file/d/0B70imXT2spOfUlI2dl9tSFdWaW8/edit?resourcekey=0-6B01Yrc0xzXbhm24C8VuPA Fecha de acceso: 09.05.2023
Discapnet. (2022). Definición de lectura fácil. https://www.discapnet.es/vida-independiente/accesibilidad-de-comunicacion/lectura-facil. Fecha de acceso: 30.11.2022.
García Muñoz, O. (2012). Lectura fácil: Métodos de redacción y evaluación. https://www.plenainclusion.org/sites/default/files/lectura-facil-metodos.pdf. Fecha de acceso: 17.05.2023
GRUPO EDUCACIÓN Y DIVERSIDAD (EDI). (2009:2011). Lectura fácil, estructura textual y comprensión lectora en niños con discapacidad y niños inmigrantes. www.grupo-edi.com/lectura_facil.pdf. Fecha de acceso: 01.12.2022.
Hinojosa, A. (2022). ¿Para qué sirve “la nube”? https://planetafacil.plenainclusion.org/para-que-sirve-la-nube/ Fecha de acceso: 09.05.2023.
International Federation of Library Associations and Institutions (IFLA). (2012). Directrices para materiales en lectura fácil. https://www.ifla.org/wp-content/uploads/2019/05/assets/hq/publications/professional-report/120-es.pdf. Fecha de acceso: 02.12.2022.
Martí, A. (2021). Google Drive vs Onedrive vs Dropbox vs iCloud: comparativa de las apps de móvil de los principales servicios en la nube. https://www.xataka.com/servicios/google-drive-vs-onedrive-vs-dropbox-vs-icloud-comparativa-apps-movil-principales-servicios-nube Fecha de acceso: 09.05.2023.
Open AI. (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774 Fecha de acceso: 19.06.2023.
Rivero-Contreras, M. y Saldaña, D. (2019). Rúbrica de evaluación de textos en lectura fácil: Material para facilitar la aplicación de la Norma Española Experimental UNE 153101 EX. (versión 2.1). Manuscrito inédito, Laboratorio de Diversidad, Cognición y Lenguaje, Departamento de Psicología Evolutiva y de la Educación, Universidad de Sevilla, Sevilla. https://idus.us.es/bitstream/handle/11441/84619/R%c3%babrica%20Adaptaci%c3%b3n%20textos%20en%20LF_v2.1_2019_07.pdf?sequence=3&isAllowed=y Fecha de acceso: 01.12.2022.
Technology Innovation Institute – TII. (2023). Introducing Falcon LLM. https://falconllm.tii.ae/ Fecha de acceso: 19.06.2023.
Xue, L., Constant, N., Roberts, A., Kale, M., Al-Rfou, R., Siddhant, A., Barua, A. & Raffel, C. (2021). mT5: A massively multilingual pre-trained text-to-text transformer. https://arxiv.org/abs/2010.11934 Fecha de acceso: 19.06.2023
