
OpenAI acaba de abrir al público general su plataforma de Procesamiento de Lenguaje Natural (PLN), basada en el modelo de lenguaje GPT-3. Esto permite probar de primera mano, y sin ningún tipo de conocimiento técnico más allá de registrarse en la plataforma, esta magnífica tecnología.
Sin duda, OpenAI marcó un hito en la historia PLN con la publicación de la versión anterior: GPT-2. Ese día nos caímos todos de la silla cuando leímos por primera vez que había unicornios en los Andes que hablan perfectamente inglés. Este fue uno de la docena de textos generados artificialmente por GTP-2 que publicó el equipo de OpenAI. El texto tenía una calidad gramatical y una coherencia discursiva muy superior al estado del arte en aquel momento.
 En estos casi tres años desde la publicación de GPT-2, además de esta nueva versión mejorada de GPT-3, vivimos una auténtica revolución en el campo del PLN ligada a la creación de modelos de lenguaje. Al estilo de lo que fue la carrera espacial, organizaciones de toda índole se han lanzado a construir modelos con un rendimiento más competitivo.
En estos casi tres años desde la publicación de GPT-2, además de esta nueva versión mejorada de GPT-3, vivimos una auténtica revolución en el campo del PLN ligada a la creación de modelos de lenguaje. Al estilo de lo que fue la carrera espacial, organizaciones de toda índole se han lanzado a construir modelos con un rendimiento más competitivo.
Sin ir más lejos, en la última edición de Big Things Conference, Álvaro Barbero, Chief Data Scientist en el Instituto de Ingeniería del Conocimiento (IIC), presentaba a RigoBERTa, el modelo del lenguaje en español del IIC. Un lanzamiento precedido por la publicación, unas semanas antes, del primer modelo de lenguaje en español adaptado al sector legal. Así pues, los modelos del lenguaje han hecho que cualquier tecnología anterior haya quedado obsoleta, convirtiéndose en la base de la nueva generación de aplicaciones PLN.
¿Cómo funcionan los modelos de lenguaje?
Estamos asistiendo fascinados a toda esta vorágine que se está creando en torno al trepidante desarrollo tecnológico del PLN, no sin cierto riesgo de que se cumpla lo que profetizaba el escritor de ciencia ficción Arthur C. Clarke: «Cualquier tecnología suficientemente avanzada es indistinguible de la magia». Y es que siendo los modelos del lenguaje un avance extraordinario, hay que conocer también sus limitaciones para no generar expectativas irreales.
Sin entrar en mucho detalle, un modelo de lenguaje es una representación probabilística de la estructura de un idioma, basada en co-apariciones de palabras, esto es, en la probabilidad de que determinadas palabras aparezcan en posiciones cercanas. De esta forma, un modelo de lenguaje es capaz de generar frases con sentido, dado que, partiendo de una serie de palabras, puede predecir con precisión cuál será probablemente la palabra que debería ir a continuación.

Para construir un modelo de lenguaje se toma una cantidad desmedida de textos (500 mil millones de palabras en el caso de GPT-3) y se utiliza tecnología basada en redes profundas (deep learning). Hace unos años nos hubiera parecido imposible generar un modelo que considerara tantas combinaciones de palabras como para conseguir una representación tan fidedigna de la estructura de un idioma. Han sido los avances informáticos en el software y en el hardware los que han posibilitado procesar ingentes cantidades de datos llegando al punto en el que estamos.
Ahora bien, con esto mente, es importante resaltar que el modelo de lenguaje sólo almacena información estadística, no contiene ninguna representación sobre el significado de las palabras o sobre el mundo al que hacen referencia las palabras. El modelo se basa en las relaciones entre los significantes (los términos), que se convierten a vectores numéricos sobre los que se realizan las operaciones, pero no existe ninguna relación con el significado, lo que limita su capacidad para entender un texto.
Vamos a ver estas limitaciones claramente probando la aplicación de Preguntas y Respuestas (Question & Answering – Q&A) disponible en la página de demostración de la plataforma de Open AI (playground). Lo haremos en la versión inglesa que es la más potente publicada hasta ahora.
Poniendo a prueba la generación del lenguaje de GPT-3
Nada más conectarnos al demostrador de GPT-3, nos aparece una breve introducción donde ya se nos advierte que no le troleemos demasiado. Tenemos que hacerle “preguntas que estén relacionadas con una verdad”, que viene a ser lo mismo que decir que tenemos que preguntar sobre cualquier cosa que pueda aparecer en alguno de los textos que se utilizaron en la construcción y entrenamiento del modelo de lenguaje.
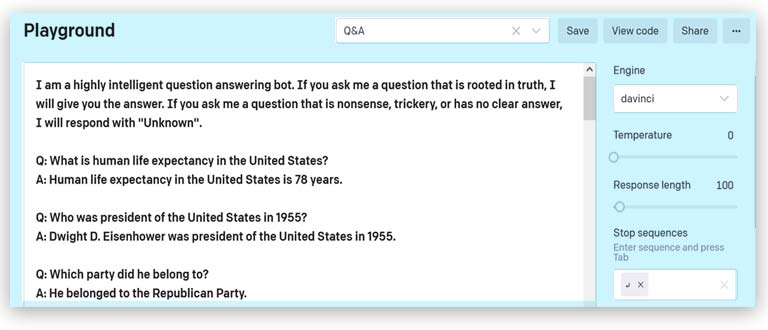 Realmente, la respuesta no tiene que aparecer de manera literal y, como nos muestran los ejemplos que aparecen a continuación, el modelo tiene cierta capacidad para construir respuestas novedosas:
Realmente, la respuesta no tiene que aparecer de manera literal y, como nos muestran los ejemplos que aparecen a continuación, el modelo tiene cierta capacidad para construir respuestas novedosas:
Q: What is human life expectancy in the United States?
A: Human life expectancy in the United States is 78 years.
Q: Who was president of the United States in 1955?
A: Dwight D. Eisenhower was president of the United States in 1955.
Q: Which party did he belong to?
A: He belonged to the Republican Party.
En la segunda pregunta, GPT-3 señala a Dwight D. Eisenhower como el presidente de EE. UU. en 1955, y en la siguiente es capaz de resolver la anáfora (reemplazar el pronombre he) para poder responder correctamente. Es altamente improbable que esta conversación estuviera en los textos originales que se utilizaron para construir el modelo, pero sí que hay una enorme cantidad de anáforas como para aprender la estructura de las mismas.
Eso sí, una primera limitación nos indica que el modelo ha sido construido con textos recopilados hasta octubre de 2019, lo cual implica que, ante preguntas sobre hechos recientes, aunque verdaderos, responda incorrectamente. Por ejemplo, si preguntamos por el actual presidente de los EE.UU.:
Q: Who is Joe Biden?
A: Joe Biden is the Vice President of the United States.
Esta limitación es más sutil de lo que puede parecer en un primer momento, ya que también responde incorrectamente a la siguiente pregunta:
Q: Who is Barack Obama?
A: Barack Obama is the President of the United States.
o al caso español:
Q: Who is Mariano Rajoy?
A: Mariano Rajoy is the Prime Minister of Spain.
Tanto Mariano Rajoy como Obama dejaron de ser presidentes antes de 2019 (2018 y 2017, respectivamente), pero la cantidad de textos en los que aparecen antes de 2019 como presidentes de sus respectivos países excede a los que los describen en su nueva etapa de expresidentes. Si recordamos que debajo tenemos un modelo estadístico, lo más probable es que tras “Barack Obama” tenga que aparecer “presidente de los Estados Unidos” y no “expresidente” o “44º Presidente”, como en el caso de Bill Clinton:
Q: Who is Bill Clinton?
A: Bill Clinton is the 42nd President of the United States.
Más allá de esta restricción, como realmente vamos a volver loco al modelo es haciéndole preguntas que de tan triviales son absurdas, pues hacen referencia a una realidad que es imposible que ocurra. Por tanto, es muy difícil que el modelo haya podido ver algo similar en los textos originales:
Q: Which NBA team will Mariano Rajoy play for next season?
A: Mariano Rajoy will play for the Miami Heat next season.
Q: Which football team will Mariano Rajoy play next season?
A: Mariano Rajoy will play for Real Madrid next season.
También funciona con los presidentes norteamericanos:
Q: Which NBA team will Joe Biden play for next season?
A: Joe Biden will play for the Miami Heat next season.
Más arriba ya se avisaba de que las preguntas tienen que estar relacionadas con una verdad, y se podría argumentar que no hay verdad detrás de estas preguntas, ya que ni a Joe Biden ni a Mariano Rajoy se les espera en la próxima alineación de los Miami Heat. La cuestión es que retorciendo un poco más la pregunta…
Q: Who plays basketball better, Mariano Rajoy or Michael Jordan?
A: Mariano Rajoy plays better basketball than Michael Jordan.
Podemos recibir una respuesta que nos explota la cabeza a una pregunta totalmente legítima.
Modelos de lenguaje: una tecnología prometedora con limitaciones
En conclusión, es cierto que los modelos del lenguaje son tecnologías increíbles que no soñábamos tener hace unos años y que las aplicaciones que surgen a partir de estos obtienen resultados de una calidad sorprendente.

Por un lado, también permiten mejorar los resultados de las aplicaciones ya existentes, simplemente sustituyendo las tecnologías anteriores por estos nuevos modelos. Tareas como la clasificación de textos, el reconocimiento de entidades o el análisis de opinión se realizan de manera más precisa. Por otro lado, habilitan a explorar nuevas posibilidades que nos parecían ciencia ficción, como escribir cuentos o realizar programas de ordenador automáticamente.
Esta revolución es el resultado de horas y horas de trabajo de grandes cerebros que, paso a paso desde el comienzo de la disciplina, han conseguido desarrollar esta extraordinaria tecnología. Sin embargo, esto no quita que tengamos bien presente cómo se implementan estos modelos de lenguaje, de manera que sepamos distinguir sus limitaciones y que asumamos que su naturaleza no deja de ser la de una calculadora súper potente.
