
Las aplicaciones de Procesamiento del Lenguaje Natural (PLN) pueden ser especialmente útiles para el sector legal, por el tiempo que sus profesionales pasan entre grandes cantidades de documentos. Herramientas que los ayuden a clasificarlos y navegar por los textos pueden ser un buen punto de partida para optimizar su trabajo.
Ese es el objetivo de Mapa del Expediente, sistema de inteligencia artificial desarrollado por el Instituto de Ingeniería del Conocimiento (IIC) en colaboración con Garrigues y que Álvaro Barbero, Chief Data Scientist del IIC, presentó en la edición de Big Things Conference 2021. En su charla NLP in Legaltech – Empowering our lawyers with language models, el experto explicó cómo funciona esta herramienta orientada al tratamiento y organización de expedientes judiciales de gran volumen.
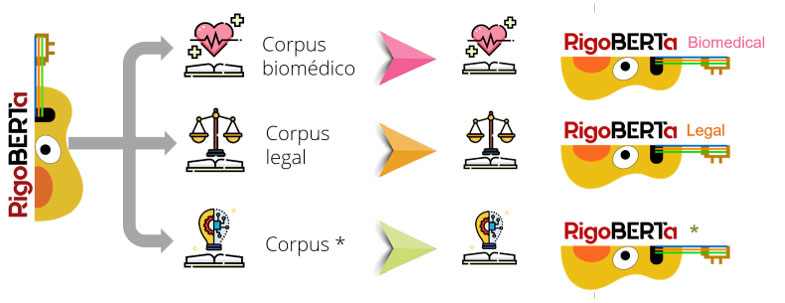
Además, su intervención fue una buena ocasión para presentar el nuevo modelo de lenguaje en español del IIC: RigoBERTa. Tras dos años de investigación, este modelo consigue un rendimiento mayor que los disponibles en un gran número de tareas de Procesamiento del Lenguaje Natural (PLN) y cuenta con la posibilidad de adaptarse a diferentes dominios del lenguaje en español.
Clasificación de documentos y detección de entidades en el sector legal
Mapa del Expediente aborda dos tareas de PLN relevantes para el sector legal: la clasificación de documentos y la detección de entidades nombradas en el texto (personas y organizaciones).
El sistema es capaz, en primer lugar, de procesar un expediente judicial en forma de documentos escaneados, digitalizándolos mediante técnicas de OCR (Optical Character Recognition) y catalogando cada documento individual según la clase de escrito (partes, actas de declaración, diligencias, autos, etc.).
 Además, detecta aquellas personas u organizaciones que aparecen mencionadas en los textos y es capaz de establecer una red de relaciones entre estas entidades, que se visualizan en forma de grafo. De este modo, permite a los usuarios consultar de manera rápida los documentos relevantes o las personas y empresas involucradas en cada caso.
Además, detecta aquellas personas u organizaciones que aparecen mencionadas en los textos y es capaz de establecer una red de relaciones entre estas entidades, que se visualizan en forma de grafo. De este modo, permite a los usuarios consultar de manera rápida los documentos relevantes o las personas y empresas involucradas en cada caso.
Para realizar estas tareas, la herramienta cuenta con un modelo del lenguaje en español adaptado al sector legal. Este fue desarrollado a partir de una metodología propia del IIC para ajustar los modelos de lenguaje generales a dominios concretos.
En este caso, se realizó una adaptación en dos fases: primero se reentrenó al modelo de lenguaje BETO con un corpus legal-administrativo recopilado de fuentes abiertas y después se utilizaron datos del propio despacho de abogados, para generar una versión todavía más específica (Garrigues-BETO).
El modelo de lenguaje en español del IIC: RigoBERTa
Otra de las novedades que el IIC ha traído este año a Big Things Conference es su primer modelo de lenguaje en español: RigoBERTa. Ya en la pasada edición, el propio Álvaro Barbero anunciaba este proyecto de investigación que consistía en desarrollar un modelo con más y mejores datos, mayor hardware, mejor arquitectura y que fuera capaz de adaptarse a diferentes dominios. Ahora, tras dos años de trabajo, lanzan la versión 1.0.
Entre los detalles técnicos, el experto explicó que el modelo se ha entrenado con cuatro fuentes de datos en español que suponen más de 450 mil millones de palabras. Además, se basa en la arquitectura del modelo de lenguaje DeBERTa, de Microsoft, que ya supera el rendimiento humano en tareas de PLN en inglés según el test de SuperGLUE.
Desde el IIC, siguen trabajando en este campo y ofrecen sus avances en modelos de lenguaje en español a cualquier negocio o sector, por su capacidad para adaptar esta tecnología a distintos dominios.
¿Quieres saber más de RigoBERTa?
