
Como resultado de un proyecto de investigación conjunto entre el Instituto de Ingeniería del Conocimiento (IIC) y Garrigues, ambas entidades hemos desarrollado y puesto a prueba el nuevo sistema de inteligencia artificial Mapa del Expediente, orientado al tratamiento y organización de expedientes judiciales de gran volumen.
Este sistema es capaz de recibir toda la documentación de un expediente judicial en forma de documentos escaneados, para analizarla, catalogarla y organizarla de forma automática. De este modo, permite a los usuarios consultar de manera rápida los documentos relevantes, las personas o empresas concretas involucradas en el caso, analizar su red de relaciones o encontrar fácilmente documentos de un tipo determinado.
Todo ello es posible con la integración en el sistema del primer modelo de lenguaje en español adaptado al sector legal, también desarrollado desde el IIC y que, en una segunda fase, se entrenó con datos del propio despacho de abogados.
Clasificación de textos y detección de entidades en el dominio legal
En particular, el sistema Mapa del Expediente es capaz de procesar un expediente judicial en la forma de ficheros PDF, que supone agregar todo tipo de documentación en cientos de páginas.
Mediante técnicas de OCR (Optical Character Recognition), se transcriben y digitalizan todas las páginas del volumen, descartando automáticamente aquellas páginas en blanco o que no contengan información, y se divide el volumen en cada una de sus partes o documentos individuales.
Además, se marca cada documento extraído con el tipo de documentación del que se trata, pudiendo así catalogar automáticamente varias clases de escritos: partes, actas de declaración, cédulas de citación, diligencias, providencias o autos, entre otros.
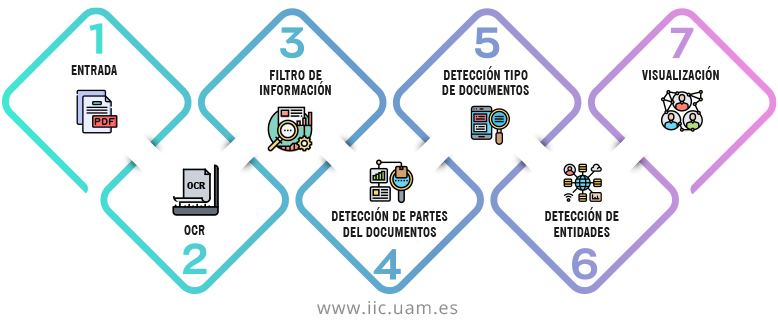
Diagrama de alto nivel del sistema desarrollado
Sumado a lo anterior, el sistema de inteligencia artificial para abogados también detecta aquellas personas u organizaciones que aparecen mencionadas en los diferentes documentos, y es capaz de establecer una red de relaciones entre estas entidades.
De esta manera, es posible conocer rápidamente en qué escritos se menciona a una persona concreta o qué empresas están relacionadas a través de una resolución judicial. Toda esta información puede visualizarse en forma de un grafo, conformando un auténtico mapa que permite navegar por el expediente.

Ejemplo de visualización del grafo de Cédulas de Citación de un expediente. Los nodos azules son Cédulas, mientras que los nodos verdes son organizaciones mencionadas en las Cédulas, y los morados refieren a personas.
Modelo de lenguaje del español legal
Para implementar estas capacidades, el sistema de inteligencia artificial cuenta con un potente modelo del lenguaje del español legal, creado por el IIC y que mejora significativamente la precisión en tareas de Procesamiento del Lenguaje Natural (PLN) sobre las tecnologías al uso.
Los modelos de lenguaje son ya los cimientos de cualquier sistema avanzado de tratamiento del texto. Existen modelos generalistas como BERT o GPT-3, en inglés, que sin embargo pueden no ajustarse a un dominio concreto del lenguaje, como puede ser la terminología y jerga empleadas en sectores especializados como el legal.
Como parte de nuestra investigación, ya adelantábamos que el IIC ha desarrollado una metodología para la adaptación de modelos de lenguaje ya existentes a diferentes dominios, reajustándolos y adaptándolos al lenguaje de un sector concreto. Y como primer resultado, se ha desarrollado ese primer modelo del lenguaje en español adaptado al sector legal.
Partiendo de BETO, el modelo general del español desarrollado por la Universidad de Chile, este se ha reentrenado con un gran corpus legal-administrativo de más de 500 millones de palabras, recopilado de fuentes abiertas. Tras esta adaptación, se obtuvo el primer modelo del lenguaje del español legal: Legal-BETO.
Adicionalmente, y en una segunda fase de adaptación en colaboración con Garrigues, se utilizaron datos de expedientes recopilados por este despacho de abogados para generar una versión más específica del modelo de lenguaje, bautizada como Garrigues-BETO.
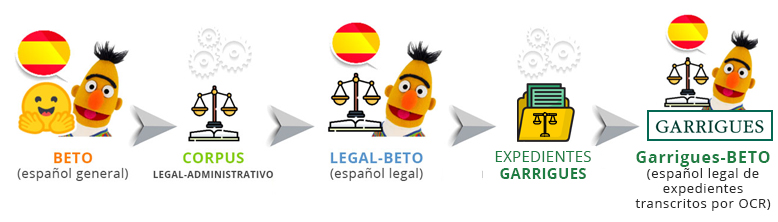
Efectividad del modelo de lenguaje en Mapa del Expediente
 Ya puesto en práctica el sistema Mapa de Expediente con Garrigues, las ventajas de contar con un modelo de lenguaje adaptado al dominio legal son claras si analizamos dos partes del sistema que hacen uso de esta tecnología y que abordan dos problemas concretos del sector legal: la clasificación de documentos y la detección de entidades nombradas en el texto (personas, organizaciones y localizaciones).
Ya puesto en práctica el sistema Mapa de Expediente con Garrigues, las ventajas de contar con un modelo de lenguaje adaptado al dominio legal son claras si analizamos dos partes del sistema que hacen uso de esta tecnología y que abordan dos problemas concretos del sector legal: la clasificación de documentos y la detección de entidades nombradas en el texto (personas, organizaciones y localizaciones).
Entre los resultados experimentales, se ha podido comprobar que el modelo Garrigues-BETO ofrece mejores resultados que el estado del arte en modelos de lenguaje en español, facilitando una aplicación real del sistema Mapa del Expediente en el sector legal.
Con el auge de las nuevas tecnologías en Inteligencia Artificial y Procesamiento del Lenguaje Natural es de esperar que cada vez más los especialistas del sector legal hagan uso de herramientas de este tipo para realizar su trabajo de manera más eficiente. De esta forma, pueden concentrar su tiempo en tareas de alto valor, relegando la organización y estructuración de la información a sistemas automáticos. Proyectos como Mapa del Expediente demuestran que tal evolución es posible y está a nuestro alcance.
