
Hace mucho que se habla de que la información es poder, pero hasta ahora no habíamos tenido la capacidad de almacenarla, relacionarla y analizarla tan fácilmente. La digitalización ha democratizado el acceso a todo tipo de datos, posibilitando así su tratamiento en diferentes ámbitos para convertirla en conocimiento.
Es el Data Mining el conjunto de técnicas que permite explorar grandes volúmenes de datos para obtener nueva información. Y si dentro del Big Data, hablamos de datos en texto, hay que hacer referencia a una de sus variantes: el Text Mining.
Aproximadamente el 80% de la información de la red está por escrito. Además de documentos e informes, en el mundo digital quedan registrados mensajes de correo electrónico, comentarios en blogs o en redes sociales, respuestas a encuestas, etc. Y toda esa información puede ser útil para emprender acciones o tomar decisiones.
Sin embargo, se trata de información no estructurada, datos en bruto que hay que procesar para explotar todas sus posibilidades. Aquí entra en juego una de las disciplinas que más ha evolucionado recientemente dentro de la Inteligencia Artificial: el Procesamiento del Lenguaje Natural (PLN), como herramienta que permite analizar, comprender y hasta generar nuevos textos automáticamente.
¿Cómo se relacionan el Data Mining y el Procesamiento del Lenguaje Natural (PLN)?
¿Qué tienen en común el Data Mining y el Procesamiento del Lenguaje Natural (PLN)? Se trata de conceptos relacionados con el análisis Big Data y el análisis de texto, respectivamente, y que encuentran su punto de unión en el Text Mining.
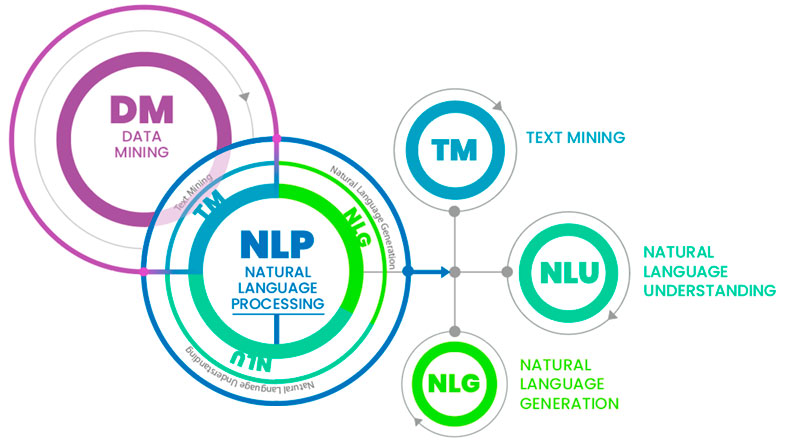
Por un lado, el Data Mining, también conocido como minería de datos o exploración de datos, hace referencia al conjunto de técnicas que se encargan de descubrir información novedosa o asociaciones implícitas en bases de datos cada vez más grandes. Estas tienen aplicación en distintos ámbitos para la detección de patrones o anomalías que permitan, a su vez, evaluar riesgos o hacer predicciones.
Dentro de este, puede englobarse el Text Mining que, con el mismo objetivo, se aplica a la información en texto. Es por esto que normalmente requiere técnicas de análisis diferentes, al tratarse de información no estructurada.
Por otro lado, el PLN consiste en transformar el lenguaje natural en un lenguaje formal, por ejemplo, el de la programación, que los ordenadores puedan procesar. Y esto mismo lo convierte en una herramienta para el Text Mining.
Así pues, el PLN sería una metodología para hacer Text Mining, al permitir estructurar la información en texto de la que disponemos y facilitar su análisis y la identificación de patrones propia del Data Mining.
Tareas de Procesamiento del Lenguaje Natural (PLN)
El Procesamiento del Lenguaje Natural (PLN) o Natural Language Processing (NLP) es la disciplina de la Inteligencia Artificial que permite el tratamiento computacional del lenguaje humano, y que pone el foco en la comprensión y en el manejo del significado en documentos escritos.
Este se realiza desde la lingüística computacional que, usada muchas para designar lo mismo que PLN, se encarga de la creación o desarrollo de formalismos y recursos sobre el funcionamiento del lenguaje. Esa transformación del texto en información estructurada es la base de muchos sistemas automáticos de análisis lingüístico, y el punto de partida para extraer valor de cualquier texto.

Después, los sistemas de PLN se basan en conjuntos de textos (corpus) representativos, que pueden estar anotados o no, y utiliza técnicas de Machine Learning para automatizar las tareas de análisis de texto, que van desde la comprensión del texto hasta la generación de nuevos textos en base a lo aprendido en los corpus.
Text Mining y análisis de texto
El PLN puede complementar al Text Mining o minería de textos, como una metodología que facilita su principal objetivo. Se trata del conjunto de técnicas que trata de descubrir esa información no explicita o de generar nueva información a partir del análisis de grandes volúmenes de texto.
Al transformar el texto en información estructurada, es más fácil descubrir la información relevante, con aplicaciones en la búsqueda de información, la clasificación de documentos o la detección de topics y detección automática de entidades, pero también sirve de base para posteriores análisis más complejos.
Entender el texto: Natural Language Understanding (NLU)
Dentro de esta disciplina, también hablamos de Natural Language Understanding (NLU), la parte del PLN centrada en comprender el texto escrito. Este análisis lingüístico tiene aplicaciones como la traducción automática, los sistemas de pregunta-respuesta, la categorización de textos o el análisis de sentimiento.
En el desarrollo de estas aplicaciones, los lingüistas computacionales tienen que atender al idioma y la terminología de los dominios a los que pertenecen los textos (redes sociales, textos médicos o documentos legales). Sin embargo, el PLN está evolucionando y actualmente se desarrollan modelos de lenguaje más generalizados y que tienen en cuenta el contexto, con arquitecturas como los Transformers.
Generación de texto: Natural Language Generation (NLG)
Otra de las aplicaciones del PLN, relevante hoy en día, es el Natural Language Generation (NLG), centrada en la generación del lenguaje. A través de estas técnicas, se pueden desarrollar los interfaces conversacionales que en los últimos años han progresado tanto.
Estas aplicaciones, no obstante, siempre necesitan una fase previa de procesamiento y comprensión de los textos, para después generar uno nuevo según lo aprendido. Desde el IIC, hemos investigado recientemente en esta línea, para estudiar cómo se generarían noticias falsas sobre la COVID-19 a partir de otras noticias o papers, y si estás pueden ser verosímiles.
Así pues, en un momento en el que la información en texto queda almacenada digitalmente para su análisis, el PLN se convierte en la parte de la IA que más está evolucionando, por el potencial del análisis lingüístico en muchos ámbitos y procesos de negocio. Desde el IIC, estamos al tanto de estas innovaciones y desarrollamos modelos de lenguaje adaptados para extraer valor automáticamente de la información disponible en cualquier sector.
