
¡Bienvenidos al emocionante mundo del lenguaje natural con RigoBERTa 2, la evolución más impresionante de nuestra línea de trabajo! Desde el Instituto de Ingeniería del Conocimiento (IIC), os presentamos nuestro último logro en el campo de la inteligencia artificial y el Procesamiento del Lenguaje Natural (PLN): RigoBERTa 2 es el resultado de un arduo trabajo y dedicación y representa una mejora significativa respecto a su predecesor, nuestro primer modelo de lenguaje RigoBERTa.
Como un modelo de lenguaje encoder-only, es decir, no generativo, RigoBERTa 2 ha superado todas nuestras expectativas, destacándose como el líder indiscutible en comprensión de texto en castellano, superando a todos los modelos encoder-only monolingües y multilingües que trabajen en español en nuestras rigurosas pruebas. En este artículo, exploraremos en detalle las razones por las cuales RigoBERTa 2 se posiciona como el modelo líder en su categoría y cómo su enfoque en la comprensión textual nos permite vislumbrar un futuro emocionante en el ámbito del procesamiento del lenguaje natural.
|
|
|
 –limitada a fines de investigación y no comerciales–
–limitada a fines de investigación y no comerciales–
Apostamos por la comprensión y el análisis del lenguaje
En un momento en el que el mundo de la inteligencia artificial está siendo inundado por el hype sobre generación de texto, RigoBERTa 2 destaca por su enfoque en la comprensión y análisis de lenguaje. En tareas de comprensión de texto como clasificación de textos, detección de entidades o respuesta extractiva a preguntas, los modelos de tipo Encoder funcionan mejor que modelos generativos gigantes como ChatGPT, como explicamos hace unos meses en el artículo ChatGPT y los modelos de lenguaje en la práctica.

Aunque la generación de texto es indudablemente emocionante y ha abierto nuevas posibilidades creativas, reconocemos que la comprensión de texto es la base fundamental para el desarrollo de aplicaciones prácticas y precisas en diversos campos. RigoBERTa 2 aborda este desafío de manera eficaz, ofreciendo una solución altamente efectiva y eficiente para entender el contenido en español, lo que lo convierte en una herramienta muy valiosa para tareas que requieran una comprensión profunda del lenguaje.
Mientras muchos modelos en el mercado centran su atención en la generación de texto, nuestra apuesta por RigoBERTa 2 ha sido ampliar las fronteras de la comprensión del lenguaje, permitiendo a usuarios y empresas acceder a información relevante, tomar decisiones más informadas y facilitar la interacción con el mundo digital en el idioma español.
Poniendo a prueba a RigoBERTa 2
Durante el desarrollo de RigoBERTa 2, llevamos a cabo un riguroso benchmark con 22 datasets en castellano, abarcando tareas de respuesta extractiva a preguntas, detección de entidades y clasificación de textos en todas sus formas. Para comparar el rendimiento de RigoBERTa 2, hemos probado también modelos como mDeBERTa-v3, RoBERTa-large del Plan de Tecnologías del Lenguaje en colaboración con el BSC, también conocido como MarIA-large, xlm-roberta-large y BETO, entre otros. Estos modelos seleccionados son el resultado de la evaluación continua de modelos de lenguaje en tareas en castellano.
Para desarrollar este benchmark, se llevaron a cabo 3 experimentos independientes diferentes. El primero de ellos estaba enfocado en el dominio biomédico, ya que es un campo de interés para el IIC. El segundo y tercer benchmark son más generales, y se basan en las tareas utilizadas en la evaluación de los modelos MarIA, así como de la primera versión de RigoBERTa.
En las tablas que presentamos a continuación, podemos apreciar cómo RigoBERTa 2 supera en general al resto de modelos en la mayoría de las tareas evaluadas. En particular, RigoBERTa 2 ha logrado mejoras significativas en la detección de entidades y en la clasificación de textos, lo que destaca su capacidad para comprender y contextualizar el lenguaje de manera más efectiva que sus competidores.

Tabla 1. Benchmark en dominio biomédico (Pincha para ampliar la imagen).

Tabla 2. Benchmark general 1 (Pincha para ampliar imagen)
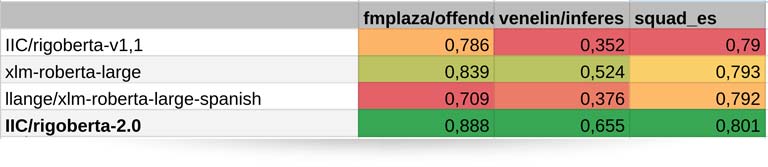
Tabla 3. Benchmark general 2.
Sin embargo, es importante mencionar que las primeras versiones de RigoBERTa, sorprendentemente, mantienen una clara ventaja competitiva en las tareas de respuesta extractiva a preguntas, superando al resto de modelos evaluados, incluyendo a RigoBERTa 2. Esto es porque la arquitectura de los modelos de la familia RigoBERTa 1 es especialmente efectiva para tareas de respuesta extractiva a preguntas, mientras que en RigoBERTa 2 nos hemos centrado en utilizar una arquitectura más apta para tareas de clasificación y detección de entidades. De este modo, obtenemos modelos complementarios.
El benchmark realizado confirma que RigoBERTa 2 ha alcanzado un nivel sobresaliente en el procesamiento del lenguaje natural en español, superando a sus competidores en la mayoría de las tareas evaluadas. De esta forma, esperamos que RigoBERTa 2 continúe siendo una herramienta valiosa para potenciar aplicaciones y soluciones en el ámbito de la comprensión de texto en el idioma español.
En conclusión, RigoBERTa 2 representa un hito importante en el avance de nuestra línea de investigación en procesamiento del lenguaje natural en castellano. Desde el IIC, queremos agradecer el apoyo y el interés mostrado en RigoBERTa 2 y nos comprometemos a seguir avanzando en la investigación y desarrollo de tecnologías de lenguaje natural para mejorar las experiencias y soluciones de nuestros clientes. Asimismo, animamos a otras empresas a aprovechar todas las ventajas de RigoBERTa 2 ., para experimentar de primera mano el poder de contar con el mejor modelo de comprensión de texto en español y llevar sus proyectos y aplicaciones de PLN al siguiente nivel

¿Es posible tener acceso a Rigoberta 2?
Hola José Luis, gracias por el interés en RigoBERTa 2. El modelo de lenguaje RigoBERTa 2 es un modelo comercial. Para cualquier otra pregunta puedes contactar con nosotros. Gracias por el interés.
Misma duda por aquí