
Los datos demuestran ser cada vez más la base para el desarrollo de proyectos de cualquier tipo en cualquier organización. Su análisis permite centrarse en la información y el conocimiento disponibles, dejando a un lado intuiciones y valoraciones subjetivas que pueden no ser acertadas a la hora de tomar decisiones.
En Lingüística Computacional (LC) y en Procesamiento del Lenguaje Natural (PLN), los datos se recogen en corpus, que no dejan de ser conjuntos de datos (textos) reales y representativos de un dominio concreto de la lengua a la que pertenecen.

Así, por ejemplo, un corpus puede estar compuesto por textos de diferente naturaleza en función de si se trata de textos orales (entrevistas, conversaciones, tertulias) o escritos (facturas, sentencias, informes médicos), de si pertenecen a una temática concreta (financieros, publicitarios, literarios), de si contienen textos en varias lenguas (monolingüe o multilingüe) o si pertenecen a distintas variedades dentro de una misma lengua (español europeo vs español latinoamericano). Sin embargo, independientemente de toda esta compleja casuística que determina el diseño exacto de un corpus y que, en esencia, refleja la naturaleza de los datos, hay dos propiedades esenciales que deben tenerse en cuenta a la hora de trabajar con estos corpus: la representatividad y el equilibrio.
Tanto la representatividad como el equilibrio juegan un papel crucial en aplicaciones y proyectos de análisis de datos y de PLN. Por un lado, cuanto más representativo sea el corpus de partida, más fácilmente se podrán generalizar los resultados obtenidos frente a nuevos datos.
Por otro, herramientas como algoritmos de aprendizaje automático (Machine Learning – ML) o aprendizaje profundo (Deep Learning – DL) tendrán más posibilidades de éxito a la hora de abordar distintas tareas de PLN y análisis de datos cuanto más equilibrado sea el corpus.
¿Cómo conseguimos un corpus representativo y equilibrado?
¿De qué hablamos cuando hablamos de la representatividad y equilibrio en relación con un corpus?
La representatividad de un corpus
La representatividad de un corpus puede ser entendida de distintas maneras. Por un lado, Leech (1991: 27) dice que el nivel de representatividad de un corpus es alto cuando los descubrimientos o resultados obtenidos a partir de dicho corpus pueden generalizarse a otros datos que pertenecen al mismo dominio. Por otro lado, Biber (1993: 43) explica que la representatividad de un corpus viene marcada por el grado en que una muestra incluye a toda la gama de variabilidad de una población. En este caso, la población hace referencia al corpus recogido.
Es importante mencionar que la representatividad de un corpus viene determinada por el grado de especificidad del propio corpus. Es decir, si se trata de un corpus de español general (que represente el español sin un dominio concreto), la idea es que contenga porciones de todos los dominios y variedades posibles para conseguir una imagen estática global del idioma. Si, por el contrario, se trata de un corpus de dominio específico como pueden ser los datos de una empresa, la idea es que el corpus contenga datos especializados de aquella parcela del lenguaje que se quiere representar. Una vez definida la representatividad, llega el turno del equilibrio.
El equilibrio de un corpus
El equilibrio de un corpus se entiende en base a la proporción que existe entre la cantidad de categorías o etiquetas asociadas al corpus y la cantidad de datos pertenecientes a cada una de ellas. Por ejemplo, supongamos que una plataforma de visualización de contenido multimedia quiere realizar una tarea de clasificación automática según el género del contenido nuevo que va llegando en base a las sinopsis asociadas.
Un corpus equilibrado en este ejemplo presentaría un número más o menos parecido de sinopsis asociadas a cada género. Por el contrario, si nos encontrásemos con muchas sinopsis asociadas a algunos de los géneros y muy pocas asociadas a otros, nuestro corpus estaría desequilibrado o desbalanceado.
Este contraste entre equilibrio y desbalanceo es justo lo que muestra gráficamente la figura 1, donde la cantidad de sinopsis por cada género cinematográfico es similar en el corpus de la derecha (con una media de 150 sinopsis por categoría), pero bastante desigual en el de la izquierda (con una variación de 166 sinopsis entre las sinopsis de ciencia ficción y aventura).
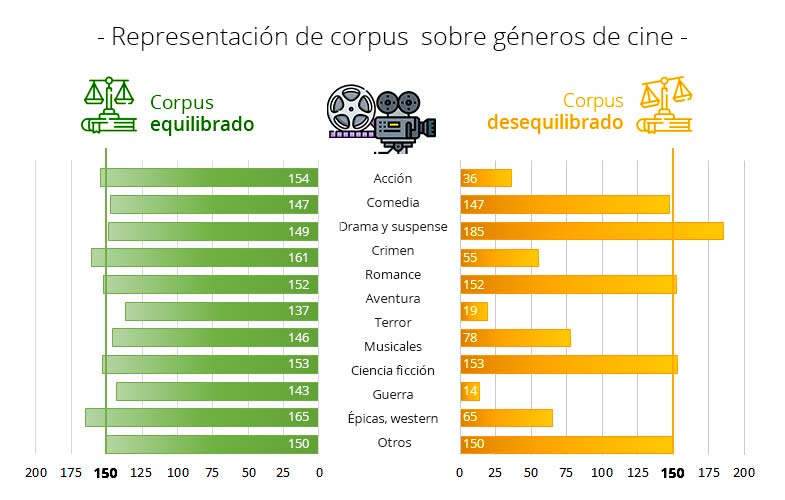 Figura 1. Representación de corpus equilibrado y corpus desbalanceado sobre géneros de cine.
Figura 1. Representación de corpus equilibrado y corpus desbalanceado sobre géneros de cine.
Impacto de la representatividad y el equilibrio en aprendizaje automático
Pero, ¿qué sucede si los datos no son representativos o el corpus se encuentran desbalanceado? Por un lado, que la muestra de datos que constituye el corpus no sea representativa quiere decir que las conclusiones que se vayan a extraer del análisis de esos datos no serán generalizables a otras muestras de datos similares.
 Esto impacta directamente sobre los algoritmos de aprendizaje automático que se utilizan hoy en día en la resolución de multitud de tareas de análisis de datos y de PLN. Los algoritmos aprenden extrayendo patrones de los datos, por tanto, si los datos de partida no son representativos de los datos futuros sobre los que se podría aplicar la solución concreta diseñada, los patrones que los algoritmos hayan extraído no serán válidos para resolver la tarea dada sin ser ajustados nuevamente.
Esto impacta directamente sobre los algoritmos de aprendizaje automático que se utilizan hoy en día en la resolución de multitud de tareas de análisis de datos y de PLN. Los algoritmos aprenden extrayendo patrones de los datos, por tanto, si los datos de partida no son representativos de los datos futuros sobre los que se podría aplicar la solución concreta diseñada, los patrones que los algoritmos hayan extraído no serán válidos para resolver la tarea dada sin ser ajustados nuevamente.
El impacto que produce el desbalanceo de los datos sobre las herramientas de aprendizaje automático es diferente. El corpus puede estar desbalanceado por diferentes motivos. El primero de ellos, porque la muestra se encuentre sesgada, o, en otras palabras, no sea representativa tal y como se explica en el apartado anterior.
El segundo caso de desbalanceo de los datos puede tener que ver con que la propia naturaleza de los datos dibuje una distribución muy desigual de las categorías a tener en cuenta y que precisamente esa distribución desigual sea característica de los propios datos.
En el caso de tener un corpus desbalanceado como el que se presenta a la izquierda en la figura 1 sobre el negocio de contenidos multimedia, los algoritmos aprenderán a clasificar mejor aquellas categorías que están más representadas que las que son menos frecuentes.
Soluciones para un corpus desbalanceado
Entonces, ¿no es posible aplicar técnicas de aprendizaje automático a corpus desbalanceados? La respuesta es sí, aunque ese desbalanceo de datos suponga un reto al que deben enfrentarse los científicos de datos y los lingüistas computacionales. En este escenario lo ideal es aplicar técnicas de balanceo, como la ampliación de los datos (oversampling).
 Partiendo de la idea de que los datos se dividen generalmente en dos conjuntos, uno de entrenamiento (del que los algoritmos y modelos de aprendizaje automático aprenden a extraer patrones) y otro de evaluación (sobre el que se evalúa el acierto de dichos algoritmos y modelos), esta estrategia de ampliación de los datos tiene que ver con aumentar “artificialmente” el volumen de datos del conjunto de entrenamiento de aquellas categorías que se encuentran menos representadas o que son menos frecuentes.
Partiendo de la idea de que los datos se dividen generalmente en dos conjuntos, uno de entrenamiento (del que los algoritmos y modelos de aprendizaje automático aprenden a extraer patrones) y otro de evaluación (sobre el que se evalúa el acierto de dichos algoritmos y modelos), esta estrategia de ampliación de los datos tiene que ver con aumentar “artificialmente” el volumen de datos del conjunto de entrenamiento de aquellas categorías que se encuentran menos representadas o que son menos frecuentes.
De esta manera, los modelos cuentan con un mayor número de ejemplos de los que aprender y extraer patrones. Así se consigue un conjunto de entrenamiento donde todas las categorías cuentan con una cantidad de datos similar, lo que facilita que todas ellas sean algo así como “igual de visibles” para el modelo.
Es importante recalcar que, aunque se modifica la distribución de los datos y se corrige el desbalanceo de las categorías en el conjunto de entrenamiento, la distribución real del conjunto de evaluación permanece intacta para que los resultados de dicha evaluación siempre reflejen la complejidad del caso de uso concreto y real a resolver.
En resumen, todo apunta a que los datos son una fuente esencial de información a exprimir con el fin de refinar la toma de decisiones y conocer en profundidad el negocio particular al que nos dedicamos. Vivimos en la era de los datos, y por ello hay que tomar ciertas precauciones a la hora de utilizarlos y analizarlos.
En este artículo se han tratado: la representatividad y el equilibrio como dos aspectos a tener en cuenta cuando se trabaja con datos, el impacto que tienen dichos aspectos a la hora de extraer conclusiones tanto para proyectos de análisis de datos como de PLN y, finalmente, algunas medidas paliativas para subsanar el desbalanceo en los mismos.
Referencias
-
- Biber, D. (1993). Representativeness in corpus design. Literary and Linguistic Computing. 8: 243-257.
- Leech, G. (1991). The state of the art in corpus linguistics. En K. Aijmer & B. Altenberg (eds.). English Corpus Linguistics. London: Longman; 8-29.
