
El aprendizaje por refuerzo es una de las técnicas que más se están empleando en la actualidad para enseñar a los ordenadores a jugar. Uno de los ejemplos más publicitados es el AlphaGo, una inteligencia artificial que ha conseguido aprender a jugar y ganar al Go, aunque existen otros que aprenden a jugar a videojuegos e incluso son capaces de jugar de forma colaborativa – al Dota2 – con estas técnicas. Pero el aprendizaje por refuerzo es más antiguo de lo que pensamos.
¿Qué es MENACE?
En los años 60, Donald Michie desarrolló lo que hoy consideramos el primer algoritmo de aprendizaje por refuerzo: MENACE. Michie era un investigador en Inteligencia Artificial que había colaborado con Turing, entre otros, en las instalaciones militares Bletchley Park, donde descifraban mensajes del ejército alemán durante la Segunda Guerra Mundial.
Con este algoritmo, que llamó MENACE (Machine Educable Noughts And Crosses Engine), un ordenador podía aprender a jugar al tres en raya. Como en aquella época los equipos informáticos no eran fácilmente accesibles, usó unas pocas cajas de cerillas y unas cuentas de colores para implementarlo.
Funcionamiento del primer algoritmo de aprendizaje por refuerzo
El funcionamiento de MENACE era sencillo. La máquina original está compuesta por varias cajas de cerillas que contienen unas cuentas de colores. Cada caja representa una situación posible del tablero. Cuando es el turno de MENACE, se abre la caja que corresponde a cómo está el tablero y se extrae una cuenta de forma aleatoria. El color de la cuenta indica dónde se debe colocar el marcador en el tablero:
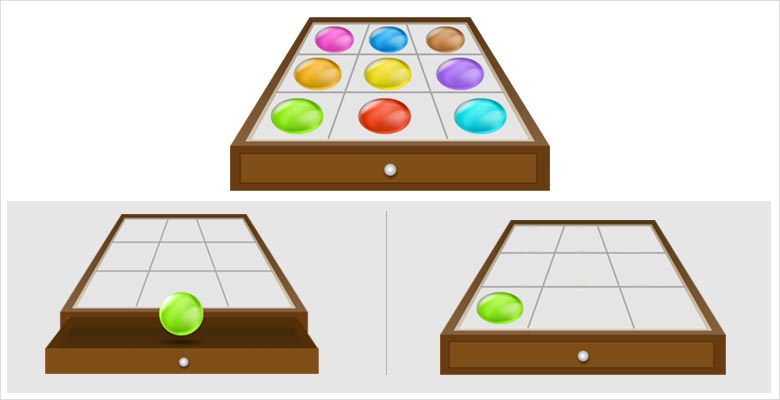
A continuación, el oponente de MENACE realiza su turno, y se continúa así hasta que uno de los dos gane o se llenen todas las casillas del tablero. Según el resultado final de la partida, se le recompensa a MENACE (si gana o si empata) o se le castiga.
Al construir MENACE, no obstante, se hicieron algunas simplificaciones para reducir el número de cajas y acelerar el aprendizaje de la máquina como, por ejemplo, imponer que siempre empieza MENACE y eliminar las cajas en las que sólo queda un espacio en blanco en el tablero, ya que la máquina no puede decidir en esas situaciones. De este modo, el total de cajas necesarias para construir MENACE se reduce a… ¡304!
El aprendizaje por refuerzo de MENACE
Para que MENACE aprendiese a jugar, Michie puso 4 cuentas de cada color posible en las cajas que corresponden al primer turno del juego, 3 de cada en las cajas del tercer turno del juego (y el segundo de MENACE), 2 de cada en las del quinto turno del juego, y una de cada color posible en las cajas del séptimo turno del juego.
Durante cada partida, se anotaban los movimientos de MENACE y se dejaban abiertas las cajas que se habían usado. Al final del juego nos podíamos encontrar con los siguientes casos:
- MENACE GANA. Si MENACE había ganado, se introducían en cada caja abierta tres cuentas del mismo color que había usado en su turno correspondiente.
- MENACE EMPATA. Si había empatado, se devolvían las cuentas empleadas a sus cajas.
- MENACE PIERDE. En el caso de que MENACE perdiese, las cuentas que se usaron para el juego no se volvían a introducir. De este modo, se fomentaban los movimientos que habían llevado a una victoria (puesto que, al haber más cuentas de los colores empleados, éstos serían más probables en las siguientes partidas), y los que habían llevado a una derrota se hacían menos probables.
Teniendo en cuenta el sistema de castigos y recompensas, podemos comprender mejor por qué Michie puso un número distinto de cuentas de cada color dependiendo de lo avanzado que estuviera el juego: las decisiones en los últimos turnos de este juego son más determinantes para el resultado de la partida.
Por ejemplo, si MENACE pierde, de la caja correspondiente al último turno se retira la única cuenta del color empleado en esa partida. Así, nos aseguramos de que esta elección nunca vuelva a ocurrir. No obstante, de la caja correspondiente al primer turno, se retira una de las 4 cuentas del mismo color, es decir, esta elección es menos probable en futuras partidas, pero no imposible, porque no podemos atribuirle toda la ‘culpa’ de haber perdido.
Con el primer algoritmo de aprendizaje por refuero, Michie consiguió que MENACE ganase o empatase siempre contra un jugador humano, después de unas pocas partidas de entrenamiento. También existe una versión programada de MENACE, sin cajas de cerillas.
Los algoritmos actuales de aprendizaje por refuerzo (reinforcement learning), aunque más sofisticados y automáticos que MENACE, se basan en el mismo principio: fomentar las acciones realizadas en partidas con victoria, y desincentivar las acciones realizadas en partidas con derrota.
