
En el verano de 2018, DeepMind y OpenAI anunciaron, separadamente, que habían entrenado sendos agentes de aprendizaje por refuerzo capaces de superar el primer nivel del juego Montezuma’s Revenge, de Atari.
Sabiendo que ya hay agentes que, desde hace tiempo, superan todos los niveles de algunos juegos de Atari, incluso mejor que un jugador humano experto, esto no parece una noticia demasiado importante. Pero sí lo es, porque Montezuma’s Revenge es muy diferente a los demás. Tanto que se pensaba que sería uno de los grandes desafíos del aprendizaje por refuerzo.
El aprendizaje por refuerzo en el juego Montezuma’s Revenge
Los algoritmos de aprendizaje por refuerzo suelen funcionar bien si las recompensas son lo suficiente frecuentes como para que un agente que elija acciones aleatorias reciba una recompensa con una probabilidad razonable. Esto es así porque, en estas situaciones, las acciones que de entrada fueron aleatorias, son reforzadas con el sistema de recompensas.
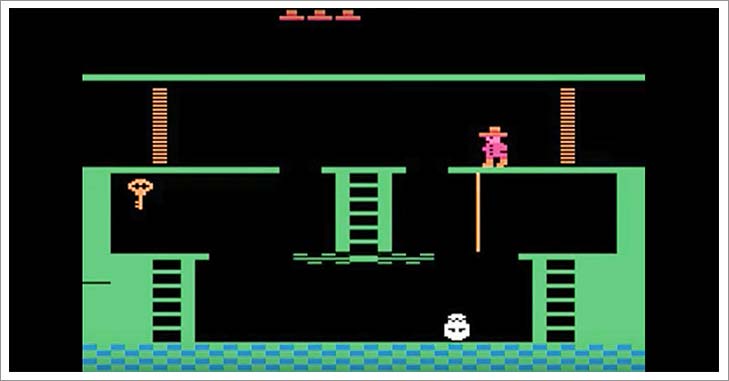
Lo que diferencia el Montezuma’s Revenge de otros juegos de Atari es que las puntuaciones crecen muy de vez en cuando, después de haber realizado una secuencia determinada de tareas. Lo entenderemos mejor con este ejemplo. Para que el marcador suba puntos al principio del primer nivel, es necesario:
- bajar por unas escaleras
- saltar entre dos plataformas agarrándose a una cuerda
- bajar otra escalera
- saltar sobre un enemigo que se mueve
- subir otra escalera y
- finalmente coger la llave.
En términos de acciones, o de botones que se tienen que pulsar para llegar hasta ahí, es necesaria una secuencia determinada de 100 botones, con la que hay que dar entre todas las combinaciones posibles. Y para terminar el primer nivel, hay que pasar por 23 habitaciones más de este estilo. Además, hay muchas condiciones que llevan a la muerte, por ejemplo, caer desde muy alto.
Por ello, los métodos que han empleado los autores de algunas publicaciones se basan en el aprendizaje a partir de ejemplos o demostraciones realizadas por una persona.
La propuesta de aprendizaje por refuerzo de DeepMind
DeepMind propone un método para que un agente de aprendizaje por refuerzo aprenda a jugar con vídeos de YouTube en los que aparecen expertos jugando al juego ([1]). En lugar de darle al agente un solo aumento de puntuación cuando consigue la llave, se le dan pequeñas recompensas a medida que pasa por unos puntos determinados del mapa que se obtienen a partir de esos vídeos.
Los autores de la publicación resuelven el problema de aprender a partir de vídeos en varios pasos:
- Construyen un modelo que, dados dos frames, predice cuánto tiempo ha pasado entre ellos.
- Construyen otro modelo que aprende la relación entre los sonidos del videojuego y las observaciones visuales. Esto tiene sentido porque, habitualmente, cuando jugamos con una consola, se produce un sonido al darse un acontecimiento importante (saltos, muerte…). De este modo, el modelo ha aprendido él solo a identificar acciones (o frames) relevantes para el juego.
- Se entrena al agente de aprendizaje por refuerzo, que será recompensado cada vez que llegue a uno de esos frames importantes que hemos mencionado.
En otro artículo reciente, también publicado por DeepMind ([2]), se proponen y prueban una serie de mejoras teóricas para el aprendizaje de un agente en general. Estas innovaciones ayudan a que la estimación del agente sobre lo buena o mala que es una acción en cada uno de los puntos del mapa sea mejor.
No obstante, al probar estas mejoras con Montezuma’s Revenge, vuelven a necesitar la ayuda de una demostración de un jugador humano, ya que, sin ella, el agente sigue sin aprender. Sin un ejemplo, se quedaba en 2.000 puntos, mientras que con una demostración, alcanzaba los 38.000 puntos.
Los resultados de OpenAI: reinicios inteligentes
Pocas semanas después de la publicación de los resultados de DeepMind, OpenAI compartió un post ([3]) en el que muestra cómo consiguieron entrenar a un agente que también superaba el primer nivel de este juego, usando de nuevo demostraciones humanas, pero con un enfoque algo distinto.
El agente se inicia primero al lado de la llave, y puede realizar las acciones que desee hasta que consiga la llave o muera. El juego vuelve a empezar en el mismo punto hasta que el agente consiga la llave en un 20% de las ocasiones.
 Luego, la pantalla se reinicia con el agente un poco más lejos de la llave, a mitad de la escalera, y vuelven a dejarlo libre, repitiendo la jugada tantas veces como sea necesario para que el agente llegue a la llave un 20% de las veces. En cada uno de los reinicios de las partidas, el agente empieza un poco más hacia atrás, hasta comenzar al principio de la pantalla.
Luego, la pantalla se reinicia con el agente un poco más lejos de la llave, a mitad de la escalera, y vuelven a dejarlo libre, repitiendo la jugada tantas veces como sea necesario para que el agente llegue a la llave un 20% de las veces. En cada uno de los reinicios de las partidas, el agente empieza un poco más hacia atrás, hasta comenzar al principio de la pantalla.
Simplemente situando al agente en el lugar adecuado en la fase de aprendizaje adecuada, los investigadores de OpenAI consiguieron 74.500 puntos utilizando el mismo tipo de algoritmo con el que entrenaron al agente que jugó al Dota2. La estrategia funciona porque, al iniciar de forma inteligente al agente, se reduce el número de situaciones que éste debe explorar para llegar a la recompensa.
En este vídeo de ejemplo podemos verlo. Aunque gran parte del juego es idéntica a la demostración que le hicieron al agente, éste supera la puntuación del ejemplo (71.500 puntos) porque recoge más diamantes por el camino.
El aprendizaje por imitación, clave para el aprendizaje por refuerzo
Cada uno de estos enfoques utiliza la demostración de un jugador humano de una forma distinta: la primera, para diseñar las recompensas que se le dan al agente; la segunda, para que se estime con más precisión lo bueno de una acción determinada en cada uno de los lugares de la pantalla; la tercera, para saber dónde reiniciar en sucesivas iteraciones.
La idea de aprender del ejemplo es natural, todos hemos aprendido muchas habilidades así, por imitación. Ahora bien, a diferencia de los ordenadores, nosotros somos capaces de generalizar con una sola demostración.
Además, no hay duda de que contamos con otra ventaja, ya que entendemos por nuestra experiencia en el mundo, las películas u otros videojuegos que las escaleras sirven para subir o bajar, que las lianas se pueden usar para saltar entre plataformas y que una llave puede ser un objetivo relevante en el juego.
Precisamente por la falta de intuición, y porque el aprendizaje por refuerzo requiere de mucho cómputo para descubrir estrategias sin ningún tipo de ayuda, el aprendizaje por imitación es, en muchas ocasiones, clave para esta tecnología. En este sentido, contar con una supervisión mínima del experto puede ayudar a conseguir resultados prácticos más rápidamente.
Bibliografía
[1]Yusuf Aytar, Tobias Pfaff, David Budden, Tom Le Paine, Ziyu Wang, Nando de Freitas, Playing hard exploration games by watching YouTube.
[2] Tobias Pohlen, Bilal Piot, Todd Hester, Mohammad Gheshlaghi Azar, Dan Horgan, David Budden, Gabriel Barth-Maron, Hado van Hasselt, John Quan, Mel Večerík, Matteo Hessel, Rémi Munos, Olivier Pietquin, Observe and Look Further: Achieving Consistent Performance on Atari.
[3] Tim Salimans, Richard Chen, Learning Montezuma’s Revenge from a Single Demonstration.
