
Tradicionalmente, la mayoría de los métodos de Inteligencia Artificial –IA– han sido considerados cajas negras a las que les damos una serie de datos y nos devuelven una predicción. Sin embargo, en ocasiones es indispensable conocer por qué nuestro modelo está tomando las decisiones que está tomando.
Por ejemplo, en el ámbito médico, la toma de decisiones se trata de un punto crítico, pues una decisión puede influir directamente en la salud de las personas. Por ello, si se utilizan estos métodos de IA como ayuda en la toma de decisiones es necesario saber algo más sobre cómo afecta cada variable a la predicción emitida por el modelo.
También es útil saber si nuestro modelo está sesgado a la hora de realizar predicciones o cuándo un modelo de IA se está desviando del criterio previsto en ciertas decisiones. Al fin y al cabo, cuando estamos entrenando un modelo de Inteligencia Artificial, lo que intentamos es descubrir los patrones que siguen los datos. Si los datos que utilizamos tienen sesgos, ocasionados mayormente por las personas al introducir la información, nuestro modelo de IA también aprenderá conforme a esos sesgos.

¿Cómo es posible conocer las decisiones que está tomando nuestro modelo si es una caja negra? ¿Cómo podemos evitar que nuestro modelo tome decisiones sesgadas? Para resolver estas cuestiones, surge la explicabilidad e interpretabilidad de los modelos. Las técnicas de explicabilidad, locales y globales, intentan extraer información sobre las decisiones que toman los modelos de Inteligencia Artificial.
Métodos de explicabilidad de la Inteligencia Artificial
Algunos modelos de Inteligencia Artificial son interpretables per se. Modelos sencillos como regresiones, que de por sí nos ofrecen la importancia de cada variable en las decisiones que se toman, o árboles de decisión, que por su propia estructura nos indican el camino de decisiones sobre las distintas variables que conducen a la predicción o decisión final.

Sin embargo, en la mayoría de las ocasiones necesitaremos hacer uso de algoritmos más complejos que no son tan transparentes en cuanto a las razones por las que se ha llegado a una conclusión concreta. Estos algoritmos se denominan algoritmos de caja negra, ya que su interpretabilidad es prácticamente nula.
Tener que utilizar modelos interpretables puede suponer una pérdida de flexibilidad a la hora de solucionar problemas de aprendizaje automático. Por ello, para la explicabilidad de los modelos de caja negra, surgen los denominados métodos de explicabilidad agnósticos.
Estas técnicas de interpretabilidad son ajenas al modelo de aprendizaje que se está utilizando y, aunque no nos otorguen una visión clara de las decisiones que toman los algoritmos de caja negra, sí que nos aportan una aproximación que nos ayuda a comprender mejor el problema que estamos tratando. A su vez, los modelos agnósticos de interpretabilidad se pueden clasificar en modelos de explicabilidad global y modelos de explicabilidad local.
Modelos de interpretabilidad global de algoritmos
Uno de los objetivos de la interpretabilidad de los modelos es explicar cuáles son las variables que un algoritmo está utilizando para tomar una decisión. Para este problema se puede utilizar la técnica denominada Permutation Importances. El objetivo es sencillo: medir el error de predicción de un modelo antes y después de permutar los valores de cada variable. De esta forma, podemos calcular cuáles son las variables que más influencia tienen en las predicciones que toma el modelo. El problema de este método es que estamos asumiendo que no existe dependencia entre las variables.
Un método similar es el de los Partial Dependence Plots. Este método de explicabilidad consiste en escoger una serie de valores para evaluar el comportamiento de una variable concreta del conjunto de datos. La forma de calcular esta métrica de explicabilidad es configurando la variable escogida, para todas las instancias del conjunto, a cada valor de una lista que hayamos decidido previamente y calculando la diferencia de error que obtenemos con cada uno.
Con el modelo Partial Dependence Plots podemos medir la importancia que tienen los distintos valores de una variable para las predicciones del algoritmo. En este método también estamos asumiendo que no existe dependencia entre las variables.
Modelos de interpretabilidad local de algoritmos
Gracias a los métodos de explicabilidad global, podemos saber cómo se comporta nuestro modelo de forma general. Esto es, conocer qué variables está teniendo en cuenta para tomar decisiones y cómo afectan los valores de esas variables a las predicciones en general. Sin embargo, frecuentemente queremos saber qué está ocurriendo con cada predicción que el modelo está generando, cómo afectan los valores de cada variable a cada predicción concreta. Los modelos de explicabilidad local nos ayudan a solucionar este problema.
 El modelo de explicabilidad local más extendido es el de los valores Shapley. Los valores Shapley se basan en teoría de juegos, es decir, cuánto valor aporta cada jugador al juego completo. En nuestro caso, intentamos saber cuánto valor aporta cada variable a la predicción que se ha realizado. Sin embargo, el cálculo de los valores Shapley es muy costoso computacionalmente, aunque existen una serie de propiedades que siempre cumplen y que ayudan a optimizar los algoritmos. Estas propiedades son:
El modelo de explicabilidad local más extendido es el de los valores Shapley. Los valores Shapley se basan en teoría de juegos, es decir, cuánto valor aporta cada jugador al juego completo. En nuestro caso, intentamos saber cuánto valor aporta cada variable a la predicción que se ha realizado. Sin embargo, el cálculo de los valores Shapley es muy costoso computacionalmente, aunque existen una serie de propiedades que siempre cumplen y que ayudan a optimizar los algoritmos. Estas propiedades son:
- Eficiencia: la suma de los valores Shapley es el valor total del juego.
- Simetría: si dos jugadores son iguales, sus valores Shapley son iguales.
- Aditividad: si hay un juego que se puede dividir en dos, los componentes Shapley también se pueden descomponer.
- Jugador nulo: si un jugador no aporta valor al juego, su valor es 0.
Por ejemplo, con la propiedad de la aditividad se puede descomponer un conjunto de clasificadores, calcular los valores Shapley para cada clasificador y, sumando los valores Shapley obtenidos para cada clasificador, obtener los valores finales.
Aunque los valores Shapley nos aportan una visión local de cada predicción, al agruparlos, podemos observar el comportamiento global del modelo. Agrupando los valores Shapley que se obtienen en cada predicción, veremos el comportamiento del modelo con los distintos valores que tiene cada variable.
En un caso de salud, por ejemplo, tenemos un modelo sencillo que predice si una persona va a tener un infarto a partir de los análisis médicos que se haya realizado. Seguramente observaremos que, para las predicciones positivas (el paciente ha sufrido una parada cardiaca), los valores Shapley para los valores altos del colesterol sean también muy altos y sean bajos para los valores bajos de colesterol.
Esta situación indica que, cuánto más altos sean los valores de colesterol, más influyen en la predicción de que el paciente va a sufrir una parada cardíaca. Y de la misma manera, los valores Shapley bajos para los valores bajos de colesterol nos indican que, aunque también influyen en la predicción, influyen de forma negativa, es decir, bajan la probabilidad de que el paciente sufra una parada cardiaca.
Restricciones de los modelos de interpretabilidad de algoritmos
Existen una serie de restricciones que tienden a indicarnos que los modelos de interpretabilidad no son siempre óptimos y que dependerá del problema que queramos resolver. Las restricciones más reseñables dentro de la explicabilidad son: la balanza explicabilidad-precisión y el coste computacional.
 Como ya hemos mencionado, existen modelos más interpretables, como son los algoritmos de regresión o los árboles de decisión, pero estos a su vez no tienen por qué obtener buenos resultados en cuanto a las predicciones que realizan, depende del problema que estemos tratando.
Como ya hemos mencionado, existen modelos más interpretables, como son los algoritmos de regresión o los árboles de decisión, pero estos a su vez no tienen por qué obtener buenos resultados en cuanto a las predicciones que realizan, depende del problema que estemos tratando.
Es cierto que, si tenemos la oportunidad de utilizar este tipo de modelos más sencillos y obtener buenos resultados, además vamos a poder tener modelos que, per se, son explicables. Sin embargo, en la mayoría de los problemas de Inteligencia Artificial, queremos utilizar modelos más complejos y, por lo tanto, mucho menos explicables.
Es entonces cuando entran en juego los modelos de interpretabilidad agnósticos que, ya sabemos, tienen ciertas desventajas o rasgos negativos que debemos asumir, como la independencia de variables o el coste computacional que conlleva utilizarlos.
Los algoritmos de interpretabilidad agnósticos son de por sí computacionalmente costosos, y además trabajan sobre modelos previamente entrenados. Es decir, tenemos que sumar el coste computacional que conlleva entrenar un modelo al coste computacional que conlleva utilizar los algoritmos de explicabilidad.
Depende del problema con el que estemos tratando, esta situación será más o menos viable. Si por ejemplo tratamos con miles de predicciones al minuto, o incluso menos, es prácticamente imposible obtener la explicabilidad para cada una de las predicciones.
Casos de explicabilidad de algoritmos en salud

Los algoritmos de Inteligencia Artificial se basan en el propio conocimiento que contienen los datos para realizar predicciones. Por diversas razones, generalmente sociales, los datos pueden estar sesgados y, por ende, los algoritmos de IA aprenden de estos sesgos. Con los algoritmos de explicabilidad podemos detectar si nuestros modelos están sesgados y podemos intentar solucionarlo para que no se tengan en cuenta esos sesgos.
Además, para personas ajenas al campo de la IA puede ser complejo comprender cómo funcionan los algoritmos de Inteligencia Artificial y se preguntan por qué toman las decisiones que están tomando o cómo afecta cada variable en la decisión que toma el modelo. En el área de Big Data e IA en Salud del Instituto de Ingeniería del Conocimiento (IIC) nos hemos encontrado ante estas situaciones y, en numerosos proyectos, ha sido necesario aplicar estas técnicas de explicabilidad de la IA.
Explicabilidad sobre la aceptación de presupuestos en salud
Por ejemplo, en el área de Salud hemos utilizado estas técnicas para explicarle a expertos de una clínica qué variables están influyendo en la aceptación de presupuestos para tratamientos médicos. Nuestro objetivo era construir un modelo que fuese capaz de predecir si un presupuesto, compuesto por variables demográficas y una serie de tratamientos médicos, va a ser aceptado por el paciente o no. Uno de los aspectos más importantes de este proyecto era que se pudiesen conocer las razones por las que un presupuesto va a ser aceptado o rechazado. Aquí es donde entra la explicabilidad.
El procedimiento que se ha llevado a cabo es el siguiente: primero,
- Se construye un modelo de IA que se amolde al problema en cuestión. Uno de los rasgos más restrictivos de la explicabilidad es la eficacia del modelo, si el modelo no consigue los resultados esperados, por mucho que consigamos interpretarlo, estaríamos interpretando un modelo que no es robusto.
- Tras evaluar y comprobar la validez del modelo construido, utilizando la técnica de los valores Shapley, podemos obtener la importancia de cada variable con respecto a la aceptación del presupuesto.
A continuación, se muestra un gráfico en el que se han ocultado las variables (también los valores se han normalizado) y se han utilizado datos simulados para cumplir la protección de los datos. En él, podemos ver el comportamiento de la interpretabilidad con valores Shapley.
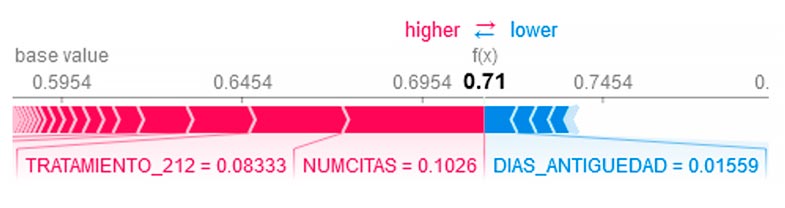 El porcentaje de aceptación que da el modelo sobre este presupuesto es 71% (0,71 en el gráfico). Y podemos ver, en rojo, las variables que influyen de forma positiva a que el porcentaje sea más alto. En azul, vemos las variables que influyen en la bajada de la probabilidad de aceptación. Analizando estos datos vemos que, para este presupuesto en cuestión, hay un tratamiento, el 212 (TRATAMIENTO_212), que influye más sobre la aceptación del presupuesto que otras variables. Y en este caso, la variable que indica los días de antigüedad (DIAS_ANTIGÜEDAD) que un paciente lleva adscrito a la clínica influye de forma negativa a la probabilidad de aceptación del presupuesto.
El porcentaje de aceptación que da el modelo sobre este presupuesto es 71% (0,71 en el gráfico). Y podemos ver, en rojo, las variables que influyen de forma positiva a que el porcentaje sea más alto. En azul, vemos las variables que influyen en la bajada de la probabilidad de aceptación. Analizando estos datos vemos que, para este presupuesto en cuestión, hay un tratamiento, el 212 (TRATAMIENTO_212), que influye más sobre la aceptación del presupuesto que otras variables. Y en este caso, la variable que indica los días de antigüedad (DIAS_ANTIGÜEDAD) que un paciente lleva adscrito a la clínica influye de forma negativa a la probabilidad de aceptación del presupuesto.
Explicabilidad de las alertas médicas
La explicabilidad puede aplicarse también a un modelo que emite alertas sobre el estado de los pacientes que padecen una enfermedad concreta en un hospital.

La alerta saltará cuando un paciente se encuentre en estado grave y necesite una intervención inmediata del personal sanitario. Sin embargo, puede ocurrir que a priori el especialista no sepa por qué la situación de este paciente ha empeorado y debe analizar todas las constantes del paciente durante las últimas horas.
Gracias a un modelo con un sistema de interpretabilidad, el especialista puede saber qué variables han influido en esa alerta y han tenido un mayor efecto en el estado del paciente, según el modelo. Este sistema de apoyo tan sencillo puede hacer que un especialista centre su atención en lo realmente importante, en tratar a los pacientes, sin necesidad de estar revisando toda la información del mismo.
Al final, la interpretabilidad de los modelos sirve de apoyo a profesionales médicos a la hora de acelerar procesos que puedan llevar mucho más tiempo del necesario. Un tiempo que, en ocasiones, puede ser determinante para ayudar a un paciente.
Te puede interesar leer Inteligencia Artificial explicable y confiable
