Durante el desarrollo de proyectos que involucran Inteligencia Artificial (IA), en especial los que abarcan también un gran volumen de datos (Big Data), se invierte muchas horas en la realización de pruebas con diferentes algoritmos, ajuste de hiperparámetros, recogida y comparación de resultados… y vuelta a empezar. Se capturan los datos, se les realiza un pre-procesamiento y entonces el ciclo de trabajo gira en torno al entrenamiento y evaluación de modelos. Esta forma de hacer IA es conocida como “IA centrada en modelo” (model-centric AI).
Sin embargo, el estado del arte cada vez más apuesta por una “IA centrada en los datos” (data-centric AI), pues la experiencia ha demostrado que, más allá de lo innovadores que resulten ser los últimos algoritmos, si no son entrenados con unos datos bien etiquetados y de calidad, será imposible que ofrezcan resultados de interés.
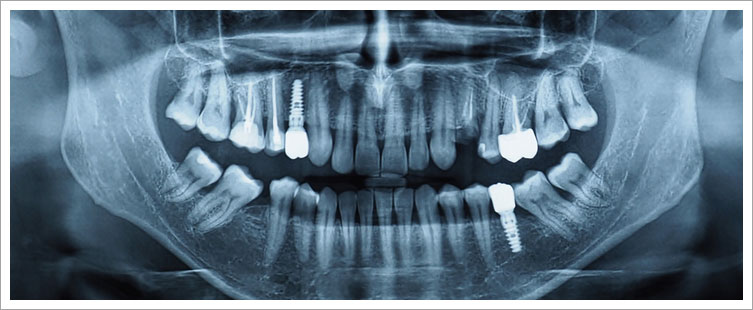
En nuestro caso de uso, partimos de un conjunto de datos –muchos gigabytes de radiografías dentales en formato DICOM– sin etiqueta alguna. Son sólo eso: imágenes tomadas por rayos X sin más información que la fotografía en blanco y negro. Nos propusimos un primer objetivo sencillo: detectar mediante IA si existen implantes en tales radiografías, y segmentarlos con un polígono en caso afirmativo. Pero, ¿cómo hacerlo, si tan sólo tenemos la imagen, sin variable o etiqueta que nos revele si hay implante o no?
Este es un gran problema en el mundo de la IA, y es en este contexto donde adquieren relevancia las herramientas de etiquetado de datos, y más si ofrecen la posibilidad de realizarlo de manera automática. En este post, veremos cómo desarrollamos un modelo automático para etiquetar las radiografías usando YOLO.
Etiquetado (manual) de implantes en radiografías dentales
Para automatizar el etiquetado de datos, necesitamos presentarle a un algoritmo las radiografías y los implantes bien delimitados para que aprenda a distinguirlos (aprendizaje supervisado). Esto supone un trabajo manual de etiquetado que tradicionalmente ha sido realizado por humanos, y expertos donde fuera necesario. Por ejemplo, resultados de los esfuerzos colectivos por etiquetar imágenes con objetos se ven en conjuntos de datos tan importantes en el mundo de la visión artificial como el COCO Dataset, que acumula más de 200.000 fotografías etiquetadas con 80 clases diferentes, como señales de tráfico, vehículos, animales o diferentes objetos.

Sin embargo, no existe un conjunto de datos público para nuestro caso de uso, tan específico como lo suelen ser en el ámbito médico: no tenemos una colección de radiografías dentales con implantes etiquetados sobre la imagen. Así que toca crear la nuestra.
Antes de proceder al etiquetado automático de implantes, los primeros pasos hemos de darlos de manera manual. Partimos de un conjunto de 8.000 radiografías, de las cuales, en torno a 1.000 contienen un número variable de implantes.
Comenzamos etiquetando a mano 100 de estas radiografías; esto es, dibujamos polígonos que encerraban todos los implantes que se encontraban en cada imagen. Para hacer esto, y luego exportar la información en un formato que un algoritmo de IA pueda entender, es imprescindible utilizar un software de etiquetado como Label Studio. Con este pequeño conjunto de datos, pasamos a la fase de entrenamiento de un modelo.
YOLO en la detección y segmentación de objetos
Se entiende por “detección de objetos” el problema de la delimitación mediante rectángulos de uno o varios objetos en una imagen, que pueden pertenecer a una o varias clases, mediante varias redes neuronales. La segmentación de objetos, por otro lado, es un problema parecido, en el que, en vez de rectángulos, se utilizan polígonos con un gran número de vértices. YOLO es un algoritmo que, con la evolución que ha tenido en los últimos años, puede resolver ambos problemas a la vez y, además, tiene implementaciones en Python que lo hacen muy accesible.
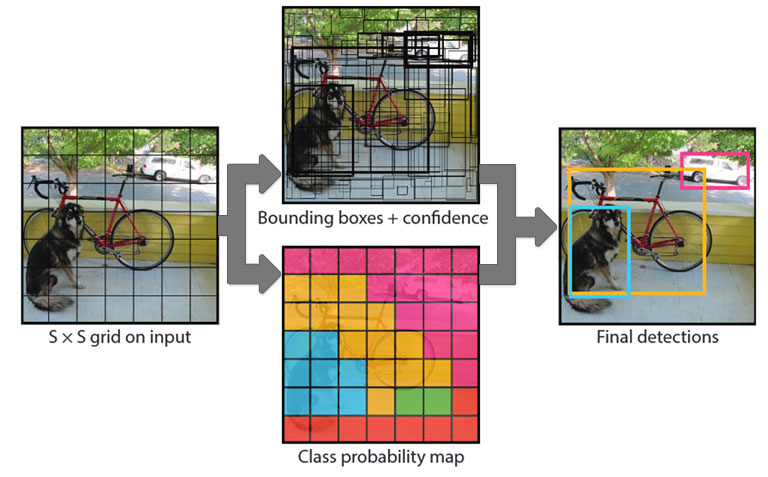
Figura 1. Gráfico resumen del algoritmo YOLO, del artículo original (https://arxiv.org/abs/1506.02640).
La idea detrás de YOLO puede definirse en términos muy sencillos: se dibuja sobre la imagen una cuadrícula de SxS cuadrados, de los que cada uno de ellos tienen la responsabilidad de i) clasificar el objeto que contiene (si lo hubiera) y ii) calcular B cuadros delimitadores alrededor del objeto, junto con el valor de confianza de haber acertado. En este contexto, el valor de S y B representarían hiperparámetros.
El proceso que sigue es conocido como non-max suppresion, por el que se van refinando los límites de los cuadros y eliminando los que tengan una confianza inferior a un threshold y los duplicados, hasta obtener las detecciones finales del algoritmo.
Volviendo al caso de las radiografias, y siguiendo nuestro proceso para llegar al etiquetado automático, primero desarrollamos un modelo sencillo con las 100 imágenes etiquetadas a mano. En 10 imágenes de prueba no vistas durante el entrenamiento, nuestro modelo ya detectaba correctamente todos sus implantes.
Un ejemplo de estas se muestra en la Figura 2, en donde se puede observar tanto el rectángulo de la detección (en rojo), como el polígono de la segmentación (en verde). Se puede ver cómo la detección con el rectángulo es correcta, mientras que la segmentación del implante de la derecha cubre un poco más de área de la que debería.
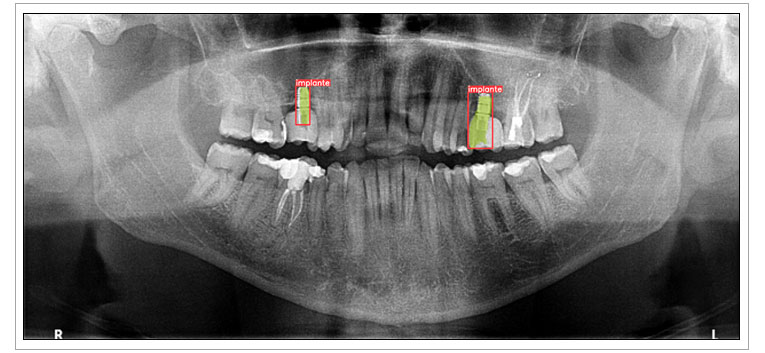
Figura 2. Detección y segmentación de implantes por un modelo entrenado con 100 imágenes. Radiografía real proporcionada por un paciente.
El ciclo de desarrollo data-centric
Aún así, este modelo inicial ya demostró ser un buen eslabón para comenzar a etiquetar de forma automática grandes conjuntos de datos: el trabajo humano se reduce a comprobar y corregir las predicciones del modelo de forma iterativa, haciendo uso del mismo software de etiquetado. A partir de aquí, comienzan varios ciclos de desarrollo data-centric en dos fases, en las que:
- Se utiliza el modelo entrenado y correcciones humanas para etiquetar más datos.
- Se reentrena el modelo con un conjunto de datos más grande, obteniendo mejores resultados.
Con cada iteración de este ciclo, el conjunto de datos crece en tamaño y calidad, mejorando también las predicciones del modelo y, por tanto, reduciendo el trabajo humano cada vez más. Los hiperparámetros del modelo no son tan importantes en esta parte del desarrollo, pues nos estamos centrando primero en los datos, pero una vez los tengamos etiquetados, podemos pasar a pulir el modelo de IA.
Detección y segmentación automática de implantes en radiografías dentales
Con esta metodología para detectar y segmentar objetos automáticamente se reduce considerablemente la carga de trabajo y, por tanto, el coste económico que supone etiquetar un gran conjunto de datos. Donde antes se necesitaba toda la atención de una o varias personas, ahora sólo hace falta un mínimo de supervisión humana, que, además, será menos necesaria conforme el modelo avance en su aprendizaje, etiquetando cada vez mejor.
Gracias a estas soluciones de código abierto es posible utilizar las predicciones de cualquier modelo de Machine Learning para clasificar datos no vistos e incorporarlos a su ciclo de aprendizaje, programando su reentrenamiento de forma periódica y automática. En el IIC tenemos experiencia en el uso de tales soluciones para abordar problemas reales del sector de la salud, además de mantenernos actualizados con el estado del arte de las tecnologías de visión artificial y de sus aplicaciones en este campo.

Buenas tardes, mi nombre es Ángel López. Actualmente soy estudiante del Curso de Especialización en Big Data e Inteligencia Artificial.
Me gustaría probar esta red neuronal de Etiquetado automático de implantes en radiografías dentales. No se si sería posible su descarga y uso.