
“Una fotografía de un astronauta montando a caballo” o “Un bol de sopa que es un portal a otra dimensión como arte digital” son frases que describen escenas inverosímiles cuya creación normalmente habría que dejar en manos de un artista.

 Sin embargo, las dos imágenes que encabezan este post han sido creadas en apenas segundos gracias a un modelo de Inteligencia Artificial o, más concretamente, un modelo de difusión. Se trata de un tipo de modelo generativo capaz de pintar imágenes a partir de textos tan intrincados como uno pueda concebir.
Sin embargo, las dos imágenes que encabezan este post han sido creadas en apenas segundos gracias a un modelo de Inteligencia Artificial o, más concretamente, un modelo de difusión. Se trata de un tipo de modelo generativo capaz de pintar imágenes a partir de textos tan intrincados como uno pueda concebir.
En este blog ya se ha hablado previamente de modelos generativos de imágenes como las GANs. El principal problema de las GANs es que su capacidad de generar imágenes muy diversas es limitada debido a la naturaleza de su entrenamiento. Por el contrario, los modelos de difusión, inspirados en la difusión en termodinámica de no equilibrio, tienen la capacidad de generar imágenes con una variedad prácticamente ilimitada.
¿Cómo funcionan los modelos de difusión?
Los modelos de difusión se basan en una idea relativamente simple: añadir ruido a una imagen hasta difuminarla completamente y luego ser capaces de revertir este proceso. Es decir, a partir de una imagen compuesta únicamente por ruido, son capaces de generar una imagen nítida. Como uno ha podido adivinar, el proceso de difuminar una imagen es más o menos sencillo, la complicación de los modelos de difusión reside en aprender a deshacer el proceso de difuminación.
Difusión de imágenes hacia delante y difusión hacia atrás
El proceso de difuminar una imagen, el cual llamaremos a partir de ahora “difusión hacia delante”, se hace en T pasos, produciendo así una secuencia x1, x2, …, xT de imágenes. En cada paso se introduce una pequeña cantidad de ruido gaussiano, es decir, ruido que sigue una distribución normal, de manera que cuando T tienda a infinito, xT sea únicamente ruido. El objetivo de la difusión hacia delante es generar las muestras de entrenamiento para el modelo de difusión y cabe destacar que cada paso de este proceso depende únicamente del anterior q(xt| xt-1). A este tipo de procesos se les denomina cadenas de Markov.

Por otra parte, al proceso de reconstruir la imagen se le denomina “difusión hacia atrás” y se trata de otra cadena de Markov en la que se realiza el proceso inverso al de “difusión hacia delante”, esto es, se dan T pasos q(xt-1|xt) que siguen una distribución normal inversa. Calcular la distribución inversa en su totalidad no es posible, pero al tratarse de una cadena de Markov es posible calcular una aproximación p(xt-1|xt), que es una manera matemática de decir “calcular una imagen ligeramente menos ruidosa que la anterior”. El objetivo del entrenamiento de un modelo de difusión es precisamente calcular una distribución p(xt-1|xt) lo más cercana posible a la distribución real q(xt-1|xt).

¿Cómo se entrena un modelo de difusión?
Al final, añadir ruido a una imagen es muy sencillo, lo que nos permite entrenar un modelo de difusión de una manera semi-supervisada siguiendo estos cinco pasos:
- Se toma una imagen del conjunto de entrenamiento.
- A dicha imagen se le aplica ruido aleatorio t De esta manera, se obtienen dos imágenes: xt y xt-1. xt, más ruidosa que la segunda, será la entrada del modelo.
- Se le suministra al modelo como entrada la imagen xt y el valor de t.
- Se calcula la pérdida entre la salida del modelo y la imagen xt-1.
- A partir de la pérdida calculada, se modifican los pesos del modelo mediante descenso por gradiente.
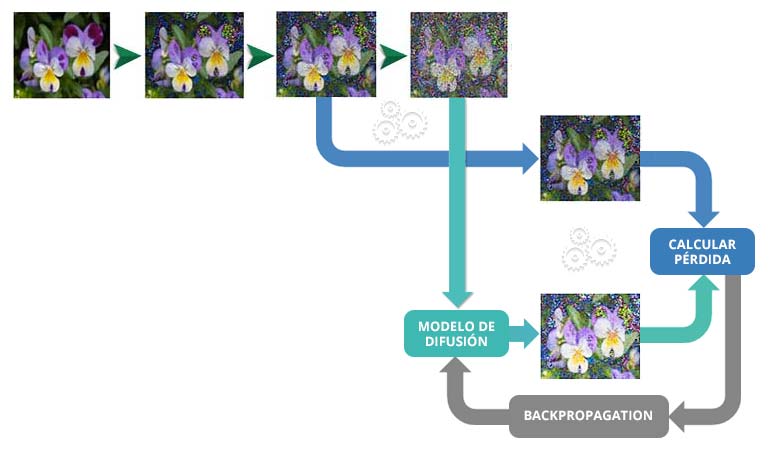 Este proceso se repite numerosas veces hasta que el modelo aprende a deshacer el proceso de difuminación. En este punto cabe preguntarse qué arquitectura tienen este tipo de modelos.
Este proceso se repite numerosas veces hasta que el modelo aprende a deshacer el proceso de difuminación. En este punto cabe preguntarse qué arquitectura tienen este tipo de modelos.
Arquitectura de un modelo de difusión
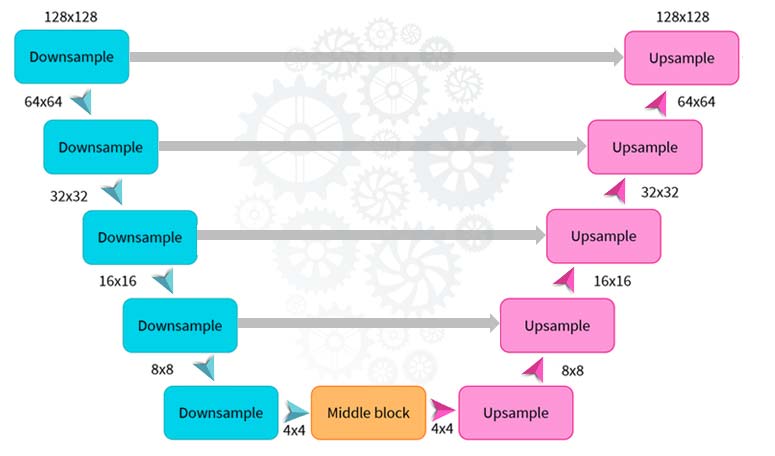
Habitualmente los modelos de difusión usan algún tipo de variante de la arquitectura U-net (figura 5), cuya idea principal es reducir la imagen mediante varios bloques convolucionales (combinaciones de una capa convolucional, una función de activación y una capa de pooling) y posteriormente deshacer este proceso de la misma manera.
A esto hay que añadir conexiones residuales entre las capas de reducción y las de aumento que tengan el mismo tamaño. Una de las claves de esta arquitectura es que la entrada y la salida tienen el mismo tamaño. Esto permite que, en el proceso de inferencia, la salida del modelo pueda ser devuelta a la entrada y así obtener progresivamente fotos con menos ruido.
Entrenando un modelo de difusión
De momento tenemos un modelo que, una vez entrenado a partir de un conjunto grande de imágenes, es capaz de generar nuevas imágenes similares a las que ha visto en ese conjunto. Veamos hasta dónde somos capaces de llegar con este modelo.
Para ello, vamos a tomar el dataset huggan/flowers-102-categories, compuesto por más de 8.000 imágenes de flores. Después, haciendo uso de las funcionalidades de la librería diffusers de huggingface, vamos a construir y entrenar un modelo de difusión durante 50 épocas.

En la figura 6 se pueden ver 8 imágenes: las 4 de la izquierda pertenecen al dataset original, mientras que las 4 de la derecha han sido generadas por nuestro modelo de difusión después de haber sido entrenado. Los resultados no son perfectos, pero entrenando el modelo durante más épocas o empleando un dataset más grande probablemente sea posible generar imágenes incluso más realistas. Llegados a este punto, uno se puede preguntar: ¿y dónde entra en juego el texto?
Difusión guiada por texto
El proceso de difusión guiada por texto se apoya en un modelo denominado CLIP (Contrastive Language-Image Pre-Training), cuyo objetivo es codificar texto e imágenes en un espacio común. Para conseguir esto, CLIP se entrena a partir de imágenes con sus correspondientes descripciones textuales, con el fin de que el vector que representa a una imagen y el vector que representa a un texto sean más cercanos entre sí cuanto más relacionados estén dicha imagen y dicho texto.
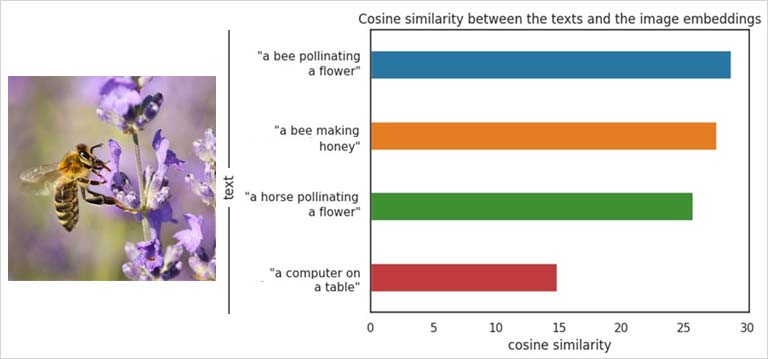
Usando CLIP se puede diseñar un sistema que reconozca cuan similares son una imagen y un texto. En la siguiente imagen, en la gráfica de la derecha, se puede ver cómo los textos que más se aproximan a lo que vemos en la imagen de la izquierda tienen codificaciones con mayor similaridad coseno a la codificación de la imagen.
En primer lugar, se introduce un texto a un “encoder” que se encarga de mapearlo a un espacio vectorial, de forma que el texto queda representado por un vector que de manera latente almacena su información. Este “encoder” se entrena de la misma manera que CLIP, para que las representaciones vectoriales de los textos estén ligadas a las de las imágenes que representan y una vez entrenado se congela.
El segundo paso es emplear un modelo de difusión para reconstruir la imagen con un ligero cambio: mediante conexiones residuales, las capas de la U-Net reciben información sobre el texto. Esta información se combina con los píxeles para condicionar la imagen que va a ser generada. Además, hay que destacar que los procesos de difusión hacia adelante y difusión hacia atrás se llevan a cabo en el espacio latente, es decir, en lugar de difuminar la imagen, lo que se difumina es la codificación vectorial de la imagen. Esta codificación vectorial, al igual que pasaba con el texto, almacena las características más esenciales de la imagen.
Finalmente, tras el proceso de difusión hacia atrás, un modelo decoder se encarga de transformar la codificación latente de la imagen en píxeles que pueden ser dibujados de nuevo.
![]()
¿Hasta dónde pueden llegar los modelos de difusión?
Las capacidades de los modelos de difusión van mucho más allá de los modelos de texto a imagen. Por ejemplo, el hecho de poder codificar las características esenciales de una imagen posibilita crear distintas variaciones de una misma imagen sin perder su esencia. En la imagen de abajo se pueden ver distintas variaciones hechas por DALL-E 2 de Los relojes derretidos de Dalí.

De la misma manera, si se interpolan en distintas proporciones las representaciones vectoriales de dos imágenes, se pueden obtener nuevas imágenes que tomen características de ambas, como sucede en la siguiente imagen:
 Otra aplicación muy práctica de este tipo de modelos es pedirles mediante texto que introduzcan en la imagen nuevos elementos. Para conseguirlo, nuevamente se emplean las representaciones vectoriales tanto de la imagen original como del texto que describe el elemento que se desea introducir en la imagen.
Otra aplicación muy práctica de este tipo de modelos es pedirles mediante texto que introduzcan en la imagen nuevos elementos. Para conseguirlo, nuevamente se emplean las representaciones vectoriales tanto de la imagen original como del texto que describe el elemento que se desea introducir en la imagen.
Como vemos, los modelos de difusión tienen posibilidades muy creativas, aunque el potencial de estas recientes técnicas de Inteligencia Artifical todavía se encuentra en fase de investigación. En el Instituto de Ingeniería del Conocimiento (IIC) estamos al día de los avances y sus posibles aplicaciones.
Si quieres leer la versión en inglés haz click en:
«Diffusion models: the guide you were looking for to understand them once and for all«.
Referencias
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
https://github.com/openai/CLIP
https://huggingface.co/docs/diffusers/index
https://gpt3demo.com/apps/openai-glide
IMAGENES 1 y 2 – https://openai.com/dall-e-2/
IMAGENES 3, 4 y 5 – Sergio Gil
IMAGENES 7, 8 y 9 – Sergio Gil
IMAGENES 10 y 11 – https://cdn.openai.com/papers/dall-e-2.pdf
IMAGEN 12 – https://gpt3demo.com/apps/openai-glide
