
El trabajo con los corpus en el marco de RigoChat-v2 merece capítulo aparte. Como adelantábamos en el post sobre cómo desarrollamos nuestro modelo de lenguaje generativo en español, la preparación de estos conjuntos de textos es esencial para adaptar un LLM existente a tareas y dominios concretos en nuestro idioma.
Como el modelo de lenguaje que queríamos obtener estaba pensado para que sea conversacional y resuelva de forma satisfactoria las consultas de los usuarios, en este trabajo nos hemos centrado solamente en los corpus en formato de instrucción: es decir, en aquellos conjuntos de datos con conversaciones entre usuarios y un LLM. En esta segunda parte, repasamos cómo hemos preparado los corpus de entrenamiento y evaluación de RigoChat-v2, como previa al artículo científico que publicaremos próximamente y que profundizará más en algunos aspectos.
¿Cómo se crean los corpus? Metodología seguida en el IIC
 En la fase de pre-entrenamiento de un modelo de lenguaje, lo único que se le pide es que infiera cuál será la siguiente palabra sobre un texto plano y sin ningún tipo de formato ni interacción con usuarios. El problema de esta fase es que requiere mucho tiempoy recursos, además de que es necesario un corpus de mucha calidad con textos en español.
En la fase de pre-entrenamiento de un modelo de lenguaje, lo único que se le pide es que infiera cuál será la siguiente palabra sobre un texto plano y sin ningún tipo de formato ni interacción con usuarios. El problema de esta fase es que requiere mucho tiempoy recursos, además de que es necesario un corpus de mucha calidad con textos en español.
A pesar de que en el Instituto de Ingeniería del Conocimiento (IIC) contamos con fuentes fiables para este fin, como RigoCORPUS, crear un LLM desde cero a día de hoy es extraordinariamente costoso, así que en el caso de RigoChat-v2 hemos optado por partir de modelos ya existentes para alinearlos a nuestros objetivos, lo cual es más rápido y económico. Aun así, el corpus es esencial para reentrenar esos modelos.
En esta línea, es interesante la investigación que se hizo para obtener FineWeb: un estudio reciente, solo con datos en inglés, sobre cómo la calidad de los corpus de preentrenamiento nos puede ayudar a obtener mejores modelos en mucho menos tiempo. El corpus es público y, a finales de 2024, publicaron una nueva versión, FineWeb-2, que cuenta con múltiples idiomas, entre ellos el español, y con una cantidad considerable de textos.
Teniendo esto en cuenta, en el desarrollo de RigoChat-v2, dedicamos atención a la calidad de estos conjuntos de textos. El proceso de preparación de los corpus consta de cuatro fases:
- recopilación de datos,
- exploración de métodos para filtrar o aumentar los datos recopilados,
- definir criterios para la creación y anotación de datos nuevos y
- establecer criterios para evaluar la calidad de los datos.
Los corpus de RigoChat-v2
Durante este proceso, como veremos a continuación, hemos logrado obtener cuatro familias de corpus perfectamente diferenciados para entrenar a RigoChat-v2:
- Un corpus masivo de instrucciones, de carácter general y con diferentes calidades. Este corpus tan heterogéneo es ideal para tener reservados ejemplos que luego puedan trasladarse a casos de uso específicos.
- Un corpus de instrucciones de alta calidad. Este corpus es un filtrado del corpus masivo, atendiendo a unos criterios predefinidos.
- Un corpus de preferencias. Este conjunto de datos está formado por conversaciones en las que existen varias respuestas alternativas, donde una de ellas es la mejor y, generalmente, ha sido seleccionada por humanos. Nuevamente, es un filtrado y procesado de los corpus mencionados antes.
- Varios corpus de evaluación, centrados en diferentes tareas y dominios, todos ellos diseñados y anotados en el IIC.
Corpus masivo de instrucciones
En una primera fase de recopilación de datos, trabajamos en un corpus masivo de instrucciones. Este corpus es una combinación de múltiples fuentes, tanto públicas como privadas, del IIC. Las fuentes públicas son, en su mayoría, corpus descargados directamente de Hugging Face a los que únicamente se les ha hecho un filtrado del idioma con la librería langdetect, con el fin de seleccionar tan solo las conversaciones en español. Además, se llevó a cabo un procesado posterior para armonizar el formato de las distintas fuentes.
Las fuentes privadas, por otro lado, son corpus generados de manera sintética o anotados por nuestro equipo de lingüistas computacionales, atendiendo a guías de anotación predefinidas. Se aplica un proceso de anotación por pares, donde al menos participan dos lingüistas revisando lo que el otro ha anotado, hasta obtener un corpus de la mayor calidad posible.
Después de todo el proceso de recopilación, generación y curación de los datos, finalmente obtuvimos 1.6 Millones de conversaciones en español, de las cuales 86720 fueron generadas en el IIC, siendo únicamente 2102 de ellas anotadas por nuestros profesionales y utilizadas para entrenar. En las siguientes gráficas (Figura 1) se encuentra resumida la distribución de nuestras conversaciones, tanto por tarea como por dominio.
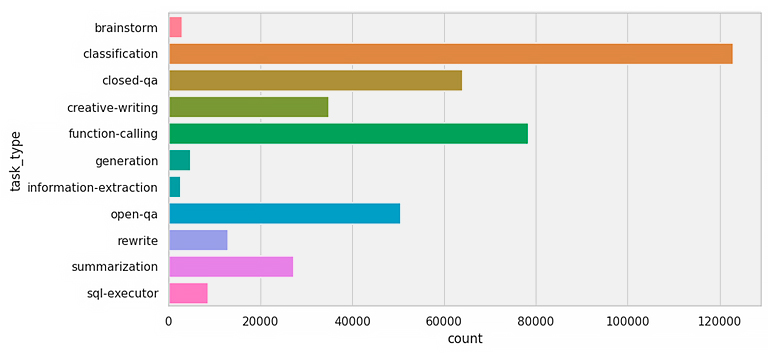
Figura 1: distribución de los tipos de tarea (arriba) y los diferentes dominios (abajo) que conforman algunos de los ejemplos del corpus masivo. Las clasificaciones siguen el formato propuesto en el artículo de InstructGPT.
 Vemos que hay mucha variedad en los datos, pero que tanto los tipos de tarea que se resuelven como los temas que se tratan están desbalanceados, haciendo que haya dominios o tareas infrarrepresentadas. Esto es lo que trataremos de equilibrar en las próximas fases.
Vemos que hay mucha variedad en los datos, pero que tanto los tipos de tarea que se resuelven como los temas que se tratan están desbalanceados, haciendo que haya dominios o tareas infrarrepresentadas. Esto es lo que trataremos de equilibrar en las próximas fases.
Hay que comentar que esta y el resto de las metodologías que aplicamos son dinámicas en el tiempo y, por tanto, el número de ejemplos contenidos en los corpus, especialmente en este primero, es susceptible de crecer todavía más. Los datos que aquí mostramos son el punto de corte desde el cual decidimos comenzar con los experimentos de RigoChat-v2.
Por último, hay que destacar el increíble trabajo que han seguido en esta línea otras iniciativas como SomosNLP, donde se hizo un gran esfuerzo en la recopilación de corpus en español y otras lenguas cooficiales. De hecho, existe una colección en Hugging Face con un catálogo bastante completo.
Corpus de instrucciones de alta calidad
Como hemos visto, el corpus masivo de instrucciones es muy heterogéneo y no todas las fuentes son igual de fiables. Por esto, y dado que valorar por separado cada una de las conversaciones sería una tarea enormemente costosa tanto a nivel de tiempo como de esfuerzo humano, se definieron unos criterios para medir la calidad de todos los corpus recopilados atendiendo a la fuente a la que pertenecían.
Nuestro equipo de lingüistas computacionales puntuó cada fuente con un número entre el 1 y el 10. Después de haber puntuado todos los corpus del conjunto de datos masivo, decidimos quedarnos con aquellas fuentes con una puntuación igual o superior a 7. De esta manera, aunque perdimos la mayoría de los datos que habíamos recopilado en el paso previo conseguimos definir un corpus de instrucciones de alta calidad. Es decir, obtuvimos unos datos mucho más representativos para nuestros objetivos: lograr alinear un LLM ya entrenado para que fuera mejor en determinadas tareas y dominios en español.
Entrenar con menos datos no tiene por qué ser peor, siempre que dichos datos sean mejores y más representativos, como era el caso. Hay que tener en cuenta también que el tiempo de entrenamiento será menor si los datos son menos. Al final, un conjunto de datos estadísticamente significativo, aunque sea acotado, siempre va a ser mejor que un conjunto de datos masivo con mucho más ruido.
El corpus de instrucciones de alta calidad cuenta con 27650 conversaciones en español, de las cuales 2102 son fuentes privadas del IIC anotadas por lingüistas computacionales, ya que las sintéticas se descartaron por el momento. Aquí el resumen de la distribución de conversaciones (Figura 2):
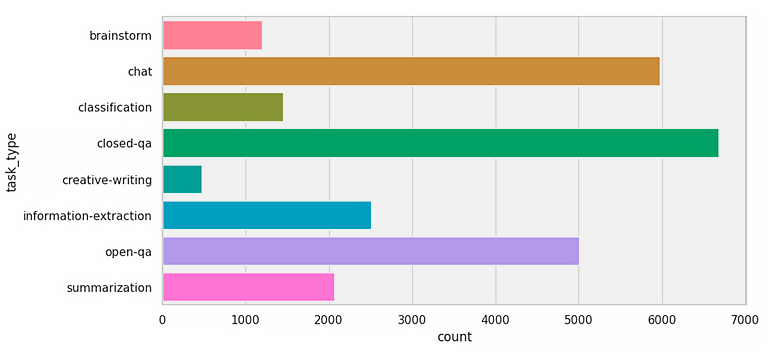
Figura 2: distribución de los tipos de tarea (arriba) y los diferentes dominios (abajo) por los que están formados las conversaciones del corpus de instrucciones de alta calidad.
 Si comparamos las Figuras 1 y 2, vemos que hay una clara diferencia en ambas distribuciones, siendo este segundo corpus de alta calidad excelente para entrenar LLMs de forma supervisada. No obstante, este pequeño estudio sobre cómo se distribuyen nuestras fuentes de datos nos generó cierta inquietud, ya que, mientras que sí teníamos control y suficientes ejemplos para entrenar con datos de calidad, no contábamos con la capacidad para, a partir del corpus masivo, filtrar aquellos datos que son interesantes tanto a nivel de tareas como de dominios.
Si comparamos las Figuras 1 y 2, vemos que hay una clara diferencia en ambas distribuciones, siendo este segundo corpus de alta calidad excelente para entrenar LLMs de forma supervisada. No obstante, este pequeño estudio sobre cómo se distribuyen nuestras fuentes de datos nos generó cierta inquietud, ya que, mientras que sí teníamos control y suficientes ejemplos para entrenar con datos de calidad, no contábamos con la capacidad para, a partir del corpus masivo, filtrar aquellos datos que son interesantes tanto a nivel de tareas como de dominios.
Por eso, aunque contamos con métodos robustos para la generación de corpus nuevos, nos pareció interesante explorar esta línea de filtrado y obtención de conversaciones de calidad de forma automática en función de los tipos de tarea que se quieren resolver y los dominios que se van a tratar. Estas consideraciones fueron las que, como consecuencia y de forma colateral, nos proporcionaron el último corpus que vamos a comentar para la fase de entrenamiento.
Corpus de preferencias
Para construir este último corpus de preferencias es necesario, para cada conversación, contar con diferentes variantes en las respuestas y seleccionar de entre todas ellas cuál es la mejor. El problema es que la mayoría de los corpus no están evaluados por humanos, ni mucho menos cuentan con variantes en sus respuestas.

Por tanto, nuestro conjunto de datos se iba a ver todavía más reducido, ya que, de entre todos los proyectos open-source que utilizamos, tan solo el de OpenAssistant cumplía con los requisitos que queríamos tanto de calidad como de número de variantes en las respuestas. Además, en este proyecto todas las respuestas están evaluadas por humanos.
El objetivo ahora era, con el resto de las conversaciones recopiladas, generar variantes de respuesta y definir métodos para localizar las de calidad de forma automática, para lo que optamos por utilizar modelos de lenguaje. El uso de LLMs para, dado un histórico de una conversación, generar diferentes respuestas tiene bastante sentido, ya que, mientras que la heterogeneidad en las consultas de los usuarios es algo inevitable (de hecho, es ideal) y las respuestas pasadas no podemos cambiarlas, sí que tenemos control sobre lo que el LLM debería contestar a continuación.
Esto es muy relevante, ya que nos está diciendo que toda conversación es susceptible de ser buena para alinear LLMs. A pesar de que la conversación sea potencialmente mala o de calidad discutible, siempre tenemos la oportunidad de proteger al modelo y entrenarlo para generar respuestas seguras y éticas, consiguiendo así modelos más robustos y sin vulnerabilidades. Además, al entrenar por preferencias, se pueden usar los datos de mala calidad como ejemplos de lo que no queremos que el modelo genere.
Todas estas ideas sobre cómo aumentar o valorar nuestras conversaciones se pueden sintetizar en la siguiente tabla:
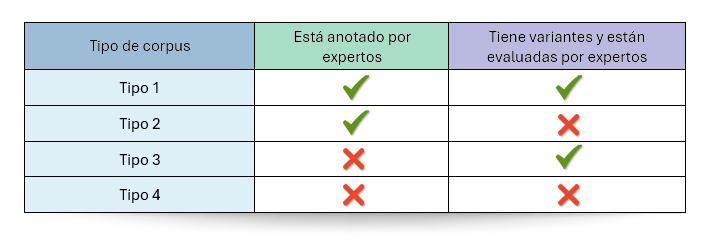
Tabla 1: caracterización de las conversaciones en función de si han sido anotadas o evaluadas por humanos expertos.
La mayoría de nuestros datos son los de Tipo 4, es decir, conversaciones en las que las respuestas del LLM no han sido ni anotadas ni validadas por expertos. Por eso es verdaderamente interesante lograr, con un error asumible, automatizar la generación y evaluación de las respuestas. Esto es: llegar a simular lo máximo posible una conversación del Tipo 1.
Ya que teníamos claro cómo generar nuevas variantes con ayuda de distintos modelos del lenguaje, lo segundo que necesitábamos era definir un método para simular la evaluación humana de nuestras lingüistas computacionales por medio de diferentes técnicas basadas en aprendizaje automático. Entre las técnicas del estado del arte que probamos, podemos diferenciar dos:
- Métricas basadas en similitud semántica. Estas métricas devuelven un número entre cero y uno que representa la distancia entre una respuesta de referencia y otra predicha.
- Métricas basadas en evaluación con LLMs como Prometheus. En este segundo tipo de métricas se clasifican las respuestas en función de unos criterios de calidad definidos. Generalmente también hace falta una respuesta de referencia y hay 5 clases, donde la clase 1 es la peor y la 5 la mejor.
Las métricas basadas en similitud semántica tienen la gran desventaja de que es necesaria una respuesta de referencia anotada por expertos, que justamente era lo que queríamos evitar, mientras que en las métricas basadas en LLMs dicha respuesta de referencia es opcional, ya que la puntuación se puede realizar en base a unos criterios.
En la siguiente tabla (Tabla 2) resumimos todos los experimentos que se han realizado para medir la precisión en la evaluación automática de respuestas generadas por un LLM dada una de referencia. Se ha utilizado un conjunto de 30 conversaciones en español, diferentes de los datos utilizados para entrenar y evaluar, con respuestas generadas por modelos y evaluadas por nuestros lingüistas computacionales. Se han probado distintos tipos de evaluadores:
- LLMs open source (Llama 3.1).
- LLMs comerciales (GPT-4o).
- Modelos especializados en evaluar (Prometheus).
- Métricas basadas en similitud semántica (SAS).
- Ensembles de varias de estas estrategias.
| Evaluador | Precisión |
| Prometheus | 27.6% |
| SAS | 33% |
| Llama-3.1-8B-Instruct | 40.4% |
| Ensemble 3 evaluadores | 39% |
| Ensemble 2 evaluadores | 36.4% |
| Llama-3.1-70B Cuantizado | 45.2% |
| GPT-4o | 35.6% |
Tabla 2: comparativa entre la distribución de puntuaciones reales y anotadas por humanos contra diferentes métodos de evaluación automáticos, sobre un conjunto de test de 30 conversaciones independiente de los corpus de entrenamiento y evaluación y con respuestas de referencia.
Como vemos, los dos evaluadores que más se acercan a la precisión de los humanos son los basados en el modelo Llama-3.1, pero tanto el normal como el cuantizado logran tan solo una accuracy media de 40.4 % y de 45.2%.
En vista de los resultados de los experimentos para simular la evaluación humana, decidimos quedarnos tan solo con las conversaciones de Tipo 1, 2 y 3. Para las conversaciones de Tipo 2, que no cuentan con variantes pero sí están anotadas por expertos, generamos de forma automática nuevas respuestas utilizando LLMs y asumimos que la respuesta anotada por el experto siempre es mejor que la generada por cualquier modelo. Además, se utilizó la métrica basada en Llama-3.1-8B-Instruct para puntuar estas nuevas respuestas, haciendo que la respuesta mejor puntuada y la peor puntuada y, por tanto, ciertas respuestas de los LLMs, también estuvieran reflejadas en el corpus final.
Después de todo el proceso de filtrado y aumento de nuestros datos, finalmente utilizamos tan solo la parte en español de OpenAssistant y las 2102 conversaciones de calidad generadas en el IIC. El corpus de preferencias final tiene 21975 conversaciones, contando las variantes, y se puede utilizar tanto para algoritmos de aprendizaje por refuerzo como, si se utilizan solo las mejores variantes, de aprendizaje supervisado.
Corpus de evaluación y resultados de RigoChat-v2
Por último, elegimos 5 corpus de evaluación para medir el rendimiento de RigoChat-v2 en comparación con otros modelos de tamaño similar y algunos más potentes en las mismas tareas. Estos datos son independientes de los utilizados para el entrenamiento. Y, de nuevo, es importante resaltar que este es un proceso dinámico y en constante desarrollo, por lo que en futuros experimentos que publiquemos es bastante probable que aparezcan más.

- AQuAS: corpus de alta calidad realizado de forma manual por dos lingüistas computacionales con el fin de evaluar modelos de lenguaje en la tarea de Question-Answering Abstractivo en español. Cuenta con ejemplos en los dominios financieros, seguros, clínico, legal y música.
- RagQuAS: corpus de alta calidad realizado de forma manual por dos lingüistas computacionales. Sirve para evaluar sistemas completos de RAG y modelos de lenguaje en la tarea de Question-Answering Abstractivo en español. Cuenta con ejemplos en una gran cantidad de dominios: hobbies, lingüística, mascotas, salud, astronomía, atención al cliente, coches, cotidiano, documentación, energía, esquí, estafas, gastronomía, hobbies, idiomas, juegos, lenguaje, manicura, música, patinaje, primeros auxilios, receta, reciclaje, reclamaciones, seguros, tenis, transporte, turismo, veterinaria, viajes y yoga.
- CAM (evaluación privada): Son preguntas frecuentes (FAQs), sobre temas de consumo de las webs de la Comunidad de Madrid. Las preguntas tienen 3 niveles de degradación: E1, E2 y E3; y el corpus pretende medir la capacidad de los LLMs de comprender y responder con eficacia ante preguntas mal formuladas por: faltas de ortografía, más o menos coloquialismos, etc. La tarea también es Question-Answering Abstractivo.
- Tiendas (evaluación privada): corpus de conversaciones multiturno sobre políticas de diferentes empresas relacionadas con la ropa. Question-Answering Abstractivo Multiturno.
- Seguros (evaluación privada): corpus de conversaciones multiturno sobre políticas de diferentes empresas relacionadas con seguros. Question-Answering Abstractivo Multiturno.
Todas las evaluaciones aquí definidas tratan de medir la precisión de las respuestas que da un LLM en distintos escenarios planteados para casos de usos relacionados con los sistemas de RAG (Retriever Augmented Generation). Como explicamos en el primer post sobre el desarrollo de RigoChat-v2, utilizamos la métrica basada en Llama-3.1 para evaluar automáticamente la calidad de las respuestas de los LLMs, siendo nuestro modelo el que ofrece una mejora notable respecto a los demás en las tareas y dominios interés.
Me interesa RigoChat-v2

RigoChat-v2 es ya un modelo de lenguaje propio del IIC que se encuentra disponible en abierto en Hugging Face y puede usarse para fines comerciales desde AWS Marketplace. Puede adaptarse a distintos dominios y/o sectores para que sea aún más eficiente, reentrenándolo con corpus específicos y representativos. Ofrecemos nuestra metodología y experiencia en PLN para alinearlo según las necesidades de cada organización.
