
Como parte de nuestra misión de implementar soluciones de vanguardia en procesamiento del lenguaje natural (PLN) y de encontrar la tecnología que mejor se adapte a las necesidades de nuestros clientes, desde el Instituto de Ingeniería del Conocimiento (IIC) llevamos recientemente a cabo una evaluación integral para comparar varios modelos de lenguaje de gran tamaño (LLM) especializados en IA generativa.
Esta se centró en aplicaciones del mundo real en español (dominios de retail, seguros y preguntas frecuentes de ciudadanos) y se realizó con diferentes corpus lingüísticos anotados en español, para identificar el modelo que ofrezca las respuestas en nuestro idioma más precisas desde el punto de vista semántico en escenarios relevantes y prácticos.
 En concreto, decidimos enfocarnos en modelos en el rango de 7 a 12 mil millones de parámetros (7B a 12B), ya que ofrecen un equilibrio ideal entre capacidades lingüísticas y rentabilidad. Comparamos los modelos más populares entre los desarrolladores y clientes, y que, en particular, pudieran ejecutarse en instancias G5 de AWS (que son más económicas que las instancias de alta gama requeridas para modelos más grandes) y, aun así, ofrecer un rendimiento competitivo.
En concreto, decidimos enfocarnos en modelos en el rango de 7 a 12 mil millones de parámetros (7B a 12B), ya que ofrecen un equilibrio ideal entre capacidades lingüísticas y rentabilidad. Comparamos los modelos más populares entre los desarrolladores y clientes, y que, en particular, pudieran ejecutarse en instancias G5 de AWS (que son más económicas que las instancias de alta gama requeridas para modelos más grandes) y, aun así, ofrecer un rendimiento competitivo.
Los modelos comparados incluyen aquellos de organizaciones líderes en IA como Meta, MistralAI, Microsoft y Stability. Entre estos, el modelo StableLM2 de StabilityAI (stabilityai/stablelm-2-12b-chat) destaca al ofrecer consistentemente resultados superiores sobre el resto de modelos de tamaño similar.
Corpus anotados de QA en español para comparar LLM
La evaluación se basó en cuatro corpus lingüísticos anotados en español desarrollados por el IIC que cubren una variedad de escenarios, desde tareas de preguntas y respuestas de distintas temáticas hasta conversaciones comerciales del mundo real. Así pues, los corpus consisten en pares de preguntas y respuestas en forma conversacional creados manualmente, así como algunos que son generados semi automáticamente y posteriormente curados por el equipo de lingüistas computacionales del IIC.
En concreto, utilizamos tres corpus de tareas de Question-answering (QA) y un cuarto, llamado citizen_information, que contiene una serie de preguntas en las que se ha insertado errores de escritura y ortográficos de forma gradual. Esta degradación de las preguntas permite evaluar la sensibilidad del modelo a la variabilidad del estilo real del usuario al preguntar.
IIC/AQuAS: contiene preguntas, respuestas y sus contextos para una variedad de temáticas. Este conjunto de datos está disponible públicamente en Hugging Face (https://huggingface.co/datasets/IIC/AQuAS).
IIC/Retail: contiene conversaciones de múltiples turnos incluyendo el contexto para cada pregunta, enmarcadas en el dominio retail.
IIC/Insurance: conversaciones de múltiples turnos incluyendo el contexto para cada pregunta, enfocadas en el dominio de seguros.
IIC/citizen: conjunto de datos de preguntas y respuestas de preguntas frecuentes que contienen preguntas con errores de escritura y ortográficos.

Nuestros corpus lingüísticos para la evaluación están diseñados para imitar tareas de tipo RAG (Retreival Augmented Generation, en inglés) y evalúan el rendimiento de los LLM en entornos complejos. En particular, estos conjuntos de evaluación ayudan a seleccionar el mejor modelo para casos de uso específicos, como apoyar consultas de documentación interna en tiendas minoristas o ayudar a los operadores de centros de llamadas a responder consultas específicas de los clientes. Además, los sistemas de RAG son útiles para controlar la tendencia del modelo a «alucinar», asegurando respuestas más precisas y confiables.
Evaluación y comparación de los modelos de lenguaje generativos
Una vez definido el corpus, cada modelo se evaluó en función de su capacidad para generar respuestas con precisión. Para medir la corrección de las respuestas, empleamos una métrica de Similitud Semántica de Respuestas (SAS, por sus siglas en inglés) (https://arxiv.org/abs/2108.06130) sobre las respuestas con respecto a una referencia creada por anotadores humanos. Dicha métrica emplea otro modelo de lenguaje para evaluar la similitud semántica entre la respuesta y la referencia.
Además, los experimentos se llevaron a cabo en una instancia p4 en AWS (https://aws.amazon.com/es/ec2/instance-types/p4/). Estas instancias permiten incluir el modelo más grande de la comparativa (Stable LM 2 12B), ya que las instancias G5 son ligeramente más pequeñas que este modelo sin cuantizar.
Resultados de la evaluación de LLMs
La Figura 1 muestra los resultados de la comparación de los corpus QA, donde las tareas están ordenadas en tamaño decreciente (número de ejemplos de prueba). Vemos que StableLM2 supera a los otros modelos en cada tarea.
- Dataset IIC/Retail (1326 preguntas y respuestas):
- Stable LM 2 12B: 0.86
- Otros modelos, incluidos Phi y Llama-3, tuvieron un rendimiento notablemente inferior, con 0.74 y 0.73 respectivamente.
- Dataset IIC/Insurance (821 preguntas y respuestas):
- Stable LM 2 12B: 0.88
- El siguiente mejor, Phi-Small, obtuvo 0.75, demostrando una clara diferencia en el rendimiento.
- Dataset IIC/AQuAS (107 preguntas y respuestas):
- Stable LM 2 12B: 0.94
- El competidor más cercano, Phi-3, obtuvo 0.93, mientras que otros como Mistral y Llama3 quedaron más rezagados.
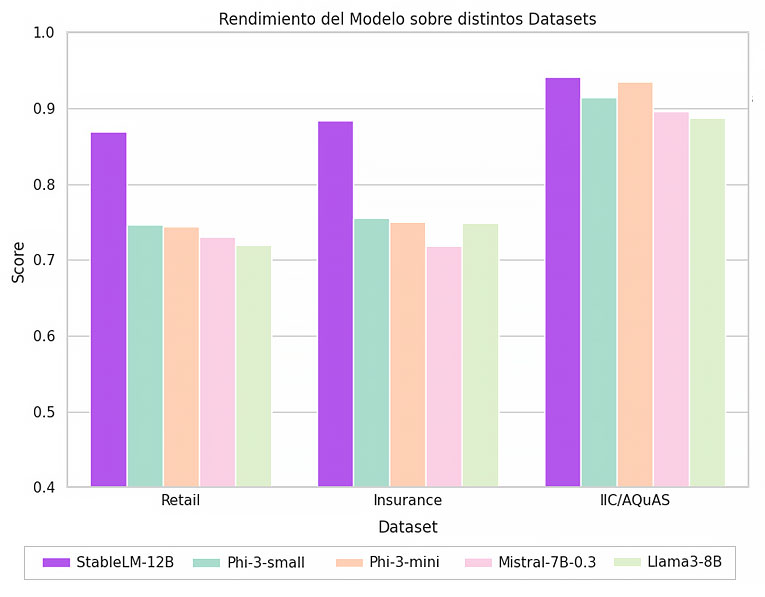
Figura 1. Resultados de la comparación empleando tres corpus de Question-Answering
La Figura 2 muestra el resultado de la evaluación empleando un corpus citizen_information. Se observa una clara disminución en la calidad de las respuestas para todos los modelos, pero algunos, como Phi3-mini, presentan una pendiente más pronunciada hacia el final, lo que indica una mayor sensibilidad a la calidad de las preguntas. Por otro lado, StableLM2 mantiene una pendiente baja, lo que significa una baja sensibilidad a medida que se degeneran las preguntas con errores de escritura u ortográficos.
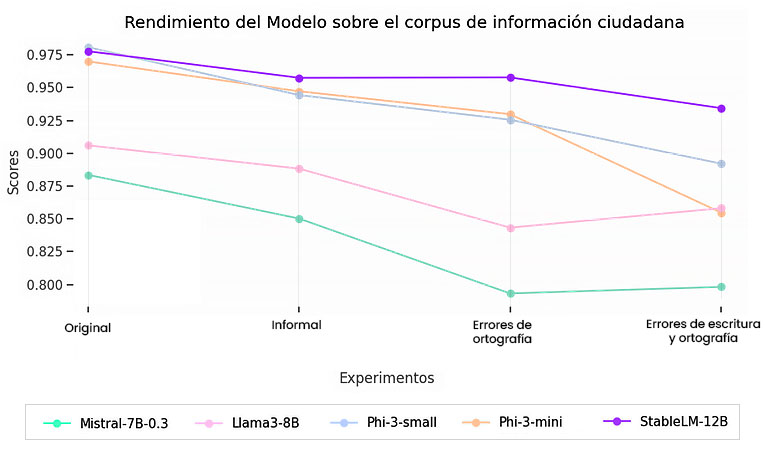
Figura 2. Resultados de la evaluación con el corpus citizen_information. Cuanto más a la derecha en la gráfica, más errores tienen las preguntas.
Nuestros resultados sugieren que StableLM2 12B es el modelo más prometedor, seguido de Phi3. La evaluación de modelos es un aspecto técnico difícil de la inteligencia artificial moderna. Desde el IIC, esperamos seguir avanzando al vincular las evaluaciones con casos de uso prácticos en la industria, especialmente en el entorno de LLM multilingüe donde con frecuencia está la lengua española que a menudo es ignorado.

Will the business make money from LLM generative AI? or Will LLM Gen AI consume too much energy? Therefore, renewable energy is actually very important.