
En el día a día, cuando los científicos de datos nos enfrentamos a tareas de aprendizaje automático o Machine Learning, existen una serie de problemáticas que estamos acostumbrados a abordar porque pueden llegar a ocurrir en cualquier proyecto. Hablamos, por ejemplo, del sobreajuste y subajuste de los modelos y del tratamiento de los valores faltantes (missing values) o de los valores atípicos (outliers), que afectan a la eficacia y al rendimiento de los modelos planteados.
Sin embargo, existen otro tipo de problemas relacionados con los datos que quizás son menos frecuentes y que también pueden tener un gran impacto, tanto en el rendimiento de los modelos de Machine Learning como por las dificultades que presentan para el científico de datos, al no entender qué está ocurriendo y por qué el modelo se está comportando de la manera en que lo está haciendo. En este artículo vamos a hablar del concepto de “drift” o “deriva” en aprendizaje automático, que puede clasificarse en dos variantes: “Data drifting” y “Concept drifting”. Además, veremos cómo pueden darse en proyectos de procesamiento del lenguaje natural (PLN).
¿Qué es el data drifting y cómo se detecta?
 Se produce data drifting cuando se dan cambios en la distribución de las variables de entrada del modelo de Machine Learning a lo largo del tiempo. Hay que tener en cuenta que esto puede ocurrir cuando el modelo está puesto en producción, por ejemplo, cuando cambia el patrón de comportamiento de los usuarios. Si una tienda empieza a atraer a un público más joven, las variables relacionadas con la edad de los usuarios irán variando y pueden afectar a las predicciones del modelo.
Se produce data drifting cuando se dan cambios en la distribución de las variables de entrada del modelo de Machine Learning a lo largo del tiempo. Hay que tener en cuenta que esto puede ocurrir cuando el modelo está puesto en producción, por ejemplo, cuando cambia el patrón de comportamiento de los usuarios. Si una tienda empieza a atraer a un público más joven, las variables relacionadas con la edad de los usuarios irán variando y pueden afectar a las predicciones del modelo.
Sin embargo, el data drifting también puede ocurrir dentro de los datos de entrenamiento del modelo por diversos motivos como:
- Que los datos hayan sido recopilados en diferentes periodos de tiempo
- Que haya datos que provengan de distintas fuentes
- Que el proceso de recopilación de los datos sea diferente y genere ciertas inconsistencias.
Existen algunos métodos estadísticos que podrán ser utilizados para comparar si dos distribuciones de datos son estadísticamente diferentes y comprobar así si está apareciendo data drifting. Por ejemplo, podemos aplicar la prueba de Kolmogorov-Smirnov.
La prueba de Kolmogorov-Smirnov
La prueba de Kolmogorov-Smirmov es una prueba estadística no paramétrica que permite comparar dos muestras de datos o una muestra respecto a una distribución teórica para determinar si provienen de la misma distribución. La prueba puede ser utilizada para comparar variables numéricas o, por el contrario, cuando queremos comprobar si dos variables categóricas provienen de la misma muestra.
A continuación, se muestra un ejemplo de la prueba de Kolmogorov-Smirnov haciendo uso de la librería Scipy de Python:
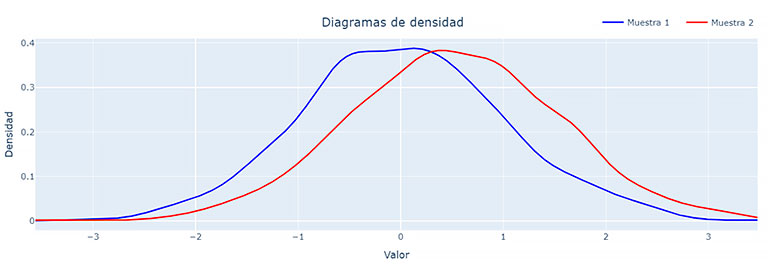 En esencia, la prueba de Kolmogorov-Smirnov mide la distancia (denominada “estadístico de Kolmogorov-Smirnov») entre las funciones de distribución acumulada de las dos muestras de datos. La hipótesis nula (H0) representa que las dos muestras provienen de la misma distribución, mientras que la hipótesis alternativa (H1) representa que las muestras provienen de distribuciones diferentes. Calculando las funciones de distribución acumulada, los estadísticos y determinando el p-valor, se concluye que:
En esencia, la prueba de Kolmogorov-Smirnov mide la distancia (denominada “estadístico de Kolmogorov-Smirnov») entre las funciones de distribución acumulada de las dos muestras de datos. La hipótesis nula (H0) representa que las dos muestras provienen de la misma distribución, mientras que la hipótesis alternativa (H1) representa que las muestras provienen de distribuciones diferentes. Calculando las funciones de distribución acumulada, los estadísticos y determinando el p-valor, se concluye que:
- Si el p-valor es bajo (por debajo del nivel de significancia elegido), se rechazará la hipótesis nula, indicando así que hay evidencia suficiente para concluir que las distribuciones son diferentes.
- Si el p-valor es alto (por encima del nivel de significancia), no se rechaza la hipótesis nula, por lo que hay evidencia suficiente para concluir que las distribuciones son diferentes.
Estadístico KS: 0.196 P-valor: 3.289875262334598e-17 Diferencia significativa entre las dos muestras. |
Concept drifting: tipos y cómo detectarlo
En el caso del concept drifting, nos estamos refiriendo a cambios en la relación entre las variables de entrada y la variable objetivo. Aquí, incluso si la distribución de las variables de entrada no se ve alterada, sí lo hacen las reglas que definen el comportamiento global del sistema con el paso del tiempo.
Un ejemplo de concept drifting podría verse cuando el mismo usuario empieza a cambiar sus gustos en una plataforma de visualización de contenido multimedia. De esta manera, se pueden alterar las relaciones entre las variables que definen al usuario y el producto que se le está recomendando.
Tipos de concept drifting
Se pueden encontrar distintos tipos de concept drifting, los más habituales son:
- Gradual: los cambios se producen de manera lenta y progresiva a lo largo del tiempo.
- Abrupto: los cambios se producen de manera súbita.
- Estacional: los cambios se producen de manera cíclica o estacional.
- Recurrente: los cambios ocurren de manera periódica y pueden repetirse con el tiempo.

En esta situación, la recomendación a seguir para poder identificar si nuestros modelos están sufriendo de concept drifting pasa por realizar una monitorización continua del rendimiento del modelo, analizando sus métricas de precisión, recall, accuracy, etc. De igual manera, resultará imprescindible analizar los propios patrones de los errores para ver si se están produciendo clasificaciones incorrectas de manera sistemática.
Para recapitular, podríamos decir que el data drifting se produce debido a cambios únicamente en las variables de entrada, provocando que los datos no sean representativos. Esto puede atajarse mediante la realización de pruebas estadísticas como la de Kolmogorov-Smirnov o la Chi cuadrado. Por otra parte, el concept drifting tiene lugar cuando cambia la relación entre las variables de entrada y la variable objetivo. Así, el modelo predice incorrectamente porque ha aprendido a encontrar patrones distintos. La manera de atajarlo es mediante visualización y reentrenamiento.
¿Cómo afecta el data drifting a los proyectos de PLN?
Uno de los campos en auge hoy en día gracias a aplicaciones como ChatGPT es el de los modelos de lenguaje y el procesamiento del lenguaje natural (PLN). Aquí se produce una situación interesante, puesto que, como ya hemos visto a lo largo de la historia, el lenguaje también evoluciona, se modifica y se transforma de diversas maneras.
Es por esto por lo que el data drifting también podría manifestarse en aplicaciones de PLN, al producirse alteraciones en la distribución de los datos de tipo texto que procesan los modelos de lenguaje. Por ejemplo, pueden aparecer cambios en el lenguaje o en el vocabulario: nuevas palabras o jergas, cambios en la popularidad de ciertas expresiones, etc. De esta manera, un modelo que hayamos entrenado hace unos años deberá reentrenarse para ajustarse a la evolución del lenguaje.
Sumado a lo anterior, pueden aparecer, además, cambios en el estilo de escritura. Imaginemos una aplicación que procesa lenguaje natural para analizar textos y sentimientos de una encuesta o de una review de un producto. Nuevas palabras, así como cambios en la manera de redactar las opiniones, pueden conducir a un rendimiento por debajo de lo esperado por parte de nuestros modelos.
Desde el Instituto de Ingeniería del Conocimiento (IIC), los expertos en Machine Learning y lingüística computacional que trabajan cada día con este tipo de tecnologías tienen en cuenta estos problemas. Nuestro objetivo es garantizar el mejor rendimiento de los modelos de lenguaje que desarrollamos y aplicamos, y que dan soporte a aplicaciones potentes y de un marcado carácter innovador.
