
Más que un evento, Databeers es una comunidad en torno a los datos y lo que se puede hacer con ellos. Diferentes ponentes cuentan cómo los utilizan en distintos ámbitos y proyectos, desde investigar el medio ambiente, pasando por cómo encontrar a gente en Facebook con datos genéricos o sacarles partido en el sector legal.
El Instituto de Ingeniería del Conocimiento (IIC) tuvo la oportunidad de estar presente en la vuelta de estos encuentros, con la participación de Helena Montoro, lingüista computacional. La experta en Procesamiento del Lenguaje Natural (PLN) explicó cómo se trabajaron y se prepararon textos reales en un proyecto del sector legal.
También contaron sus data stories Ana Tudela, de Datadista, José González, de UC3M-Santander Big Data Institute, y Antonio Fernández-Anta, de IMDEA Networks.
La calidad de los datos en Mapa del Expediente
A través del proyecto Mapa del Expediente, desarrollado por el IIC en colaboración con el despacho de abogados Garrigues, Helena Montoro se centró en el trabajo con los datos, en este caso textos legales, y sobre todo en la realidad de los datos.
El fin último del proyecto era agilizar la revisión de expedientes judiciales de gran volumen, mediante la clasificación de documentos legales y la detección de entidades jurídicas, para lo que se trabajó con 79,6 GB de datos sin etiquetar, pertenecientes a 6 expedientes judiciales.
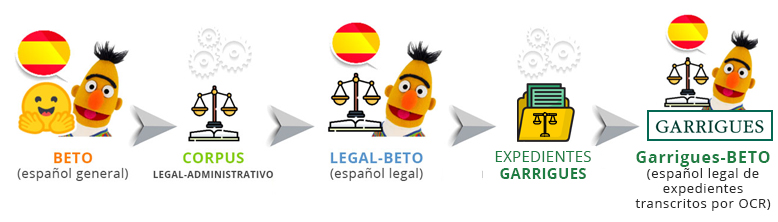
Antes de nada, había que revisar los textos de cara a la anotación de los mismos. Es entonces cuando el equipo se encuentra algunos problemas a resolver: los documentos no están digitalizados, hay páginas que no aportan nada (no informativas) y los archivos PDF contienen documentos legales concatenados que hay que delimitar.
Por tanto, a las tareas para alcanzar los objetivos principales del proyecto, se sumaron otras para tratar los textos y asegurar la calidad de los mismos. Por ejemplo, hubo que utilizar técnicas de reconocimiento de caracteres (OCR-Optical Character Recognition) para transcribir y digitalizar los documentos. También se entrenaron diferentes modelos para descartar las páginas no informativas y para dividir los archivos PDF en los documentos individuales que contenían.
Así, la experta quiso plasmar algunos retos frecuentes que el equipo de lingüistas computacionales del IIC afronta al trabajar con los datos, donde lo que se espera no suele ser lo que los textos reales recogen. Por tanto, la revisión, el tratamiento y el preprocesado de los datos es imprescindible en los proyectos de PLN y esencial para obtener los mejores resultados.

Muy informativo, ya que los datos hay que saberlos tratar, primero por la seguridad y segundo por la privacidad. Muchas gracias.