
Durante el desarrollo de aplicaciones que implementan métodos de Inteligencia Artificial, los problemas de la privacidad y el tratamiento de los datos personales adquieren un alto nivel de importancia y se deben resolver con sensibilidad. Más aún si hablamos del ámbito de la salud.
Son muchas las ventajas de utilizar algoritmos de aprendizaje automático en el entorno de la salud, como ha demostrado Bisepro en la detección precoz de sepsis. Sin embargo, el proceso de validación de un modelo de Inteligencia Artificial, es decir, la comprobación de que toma las decisiones correctas, puede complicarse debido a características específicas de la aplicación y al problema de los datos.
La validación ideal de un modelo de Inteligencia Artifical consiste en “simular” el entorno real en el que van a funcionar estas aplicaciones, con un flujo de datos continuo, sin que se repitan cíclicamente; potencialmente ilimitado. Así, podríamos poner el algoritmo a funcionar durante horas, y hasta días, en un entorno cercano a los desarrolladores para examinar su comportamiento.
Esto que, a priori, parece imposible, resulta estar al alcance cuando hablamos de datos generados sintéticamente. Con ello, se resuelve el evidente problema del volumen de datos y, a su vez, no se vulnera la privacidad de sus propietarios. En este post veremos cómo generar datos sintéticos de salud mediante un uso novedoso de las llamadas Generative Adversarial Networks (GANs).
Datos sintéticos y GANs
 La Generative Adversarial Network es una arquitectura basada en redes neuronales de Deep Learning propuesta por Ian J. Goodfellow en 2014. El resultado de esta arquitectura es una red neuronal profunda generadora que, a partir de un vector de ruido aleatorio, es capaz de generar datos sintéticos únicos.
La Generative Adversarial Network es una arquitectura basada en redes neuronales de Deep Learning propuesta por Ian J. Goodfellow en 2014. El resultado de esta arquitectura es una red neuronal profunda generadora que, a partir de un vector de ruido aleatorio, es capaz de generar datos sintéticos únicos.
El autor propone un juego competitivo entre dos redes neuronales: el Generador (G) y el Discriminador (D). Evocando la metáfora descrita en la propia publicación de Goodfellow, el primero (G) hace las veces de un estafador que trata de fabricar billetes de dinero falsos y el segundo (D), del policía que intenta identificarlos.
Mediante esta competición, tanto el Generador como el Discriminador van aprendiendo a realizar mejor su papel, lo que al final redundaría en un Generador que crea datos sintéticos indistinguibles de los reales. De esta manera se entrenan las dos redes neuronales de forma iterativa, siendo el error cometido por el Generador la tasa de acierto del Discriminador.
Mientras que su autor demostró el gran potencial de las GANs en el problema de la generación sintética de imágenes, y después la investigación lanzó propuestas adicionales para la transformación de imágenes y generación de sonido, una aplicación potencial no muy explotada es la de generación de datos tabulares.
Generación de datos tabulares con GANs
Cuando hablamos de datos tabulares, nos referimos a datos numéricos (discretos y continuos) como la temperatura, la humedad o la velocidad del viento de una zona en un momento dado, o a la edad y la estatura de una cierta persona. Se ha demostrado que las GANs consiguen un rendimiento óptimo con distribuciones de probabilidad muy concretas y bien definidas, como pueden ser la del color de los píxeles de una imagen (un número que puede, por ejemplo, estar comprendido entre 0 y 255). Sin embargo, también demuestran un buen desempeño en otras distribuciones algo más difusas, en las que puede haber valores atípicos y hasta errores humanos.
 Entrenando a la GAN con datos tabulares (con valores tanto discretos como continuos) y con el debido post-procesado, es posible generar valores sintéticos que imiten la distribución de los datos de partida y que sean totalmente distintos entre sí. Este comportamiento no determinista es debido a que los nuevos datos salen de un vector inicial aleatorio al que el Generador aplica transformaciones a través de sus capas hasta conseguir que sus valores se aproximen a la distribución de los datos originales.
Entrenando a la GAN con datos tabulares (con valores tanto discretos como continuos) y con el debido post-procesado, es posible generar valores sintéticos que imiten la distribución de los datos de partida y que sean totalmente distintos entre sí. Este comportamiento no determinista es debido a que los nuevos datos salen de un vector inicial aleatorio al que el Generador aplica transformaciones a través de sus capas hasta conseguir que sus valores se aproximen a la distribución de los datos originales.
Generación de datos de un paciente
El caso de uso planteado para Bisepro exige la generación de los datos de un monitor de vigilancia médica de un hospital, que es lo que utiliza su modelo predictivo para la detección precoz de los casos de sepsis. Estos son datos tabulares continuos y discretos como, por ejemplo, la edad del paciente o su temperatura corporal.
Estos indicadores combinan, en un mismo set de datos, diferentes distribuciones de probabilidad según la variable medida. Además, también dependiendo de si el paciente es positivo o negativo en sepsis, esta distribución variará aún más (la temperatura corporal de los pacientes con sepsis es de media algo más alta que la de una persona sana). Todos estos detalles los tiene que capturar el Generador si tiene como objetivo confundir al Discriminador, y, por tanto, generar datos que parezcan reales.
Datos de entrenamiento de la GAN
Para entrenar la GAN se ha tomado una muestra de datos de 19.000 registros de pacientes de los cuales se sabía que 4.000 padecían sepsis. De entrada, es un problema de clasificación con clases no equilibradas, lo que supone un esfuerzo adicional en el trabajo de modelado.
El pre-procesado consistió sencillamente en la transformación de variables categóricas a números discretos y en el escalado de todos los valores al intervalo [0, 1]. Este es un paso necesario para trabajar con redes neuronales, puesto que los propios valores de los datos son luego multiplicados por los pesos que la red aprende. Para que durante el entrenamiento no se subestimen las variables con menor valor numérico, estos tienen que estar en el mismo rango. Tras aplicar esta normalización, nos guardamos los parámetros utilizados para interpretar los datos generados más adelante.
Entrenamiento de la GAN
 La GAN procesa iterativamente subconjuntos aleatorios (batches, o “lotes”) de todos los datos originales y tanto el Discriminador (D) como el Generador (G) van aprendiendo de los errores de cada uno.
La GAN procesa iterativamente subconjuntos aleatorios (batches, o “lotes”) de todos los datos originales y tanto el Discriminador (D) como el Generador (G) van aprendiendo de los errores de cada uno.
El resultado final del entrenamiento es una red neuronal generadora, G, que, al introducirle como entrada un vector aleatorio de ruido, debería de devolver datos que se parecen a los de un paciente. Pero la realidad, como observamos en la imagen, es bien distinta…
Post-procesado de los datos sintéticos
Como la red neuronal generadora de datos (G) fue entrenada con datos entre [0, 1] (como es necesario), lógicamente ha aprendido a generarlos cerca de ese intervalo. Puede dar como resultado números hasta por encima y por debajo de sus límites, dependiendo del vector inicial de ruido, y de los pesos que tenga aprendidos. Es por ello que, durante el pre-procesado, nos quedamos con los parámetros utilizados para la normalización.
A continuación, es necesaria una fase de post-procesado, con pasos fundamentales como la transformación inversa de estos valores que ha devuelto G, a la escala original, o truncar los valores que eran discretos. El resultado son datos ficticios, generados desde una entrada aleatoria, que podrían ser perfectamente reales: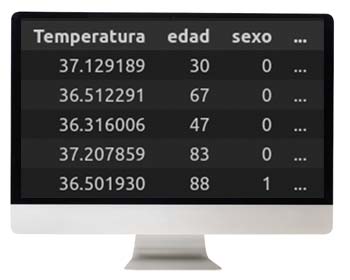
Evaluación de los datos sintéticos
Tras generar un dataset de las mismas dimensiones que el de partida, creando 19.000 pacientes ficticios, procedemos a evaluarlos. Nuestro propósito no deja de ser el de generar datos sintéticos o ficticios que nos sirvan para evaluar un modelo de aprendizaje automático como si de datos reales se tratase. Con esto en mente, realizamos una prueba práctica de predicción sobre los datos generados, para verificar que podemos, dado un modelo entrenado, sustituir los datos originales por los sintéticos.
Para ello, entrenamos y validamos un modelo del algoritmo Random Forest, que tomamos como referencia. Utilizamos el 70% de los datos originales para entrenar y, al hacer predicción sobre el 30% de los restantes, obtenemos las siguientes métricas (la clase positiva en sepsis es 1.0 y la negativa, 0.0):
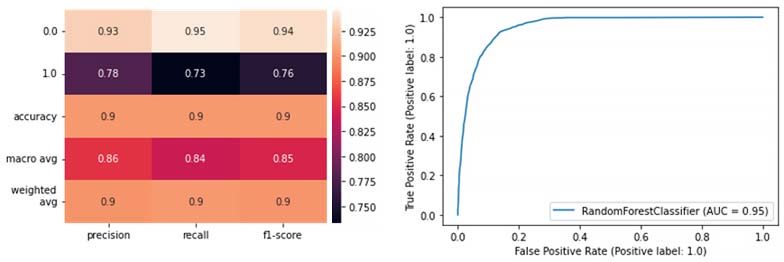
Estos son los resultados que arroja un Random Forest muy básico, utilizado en la prueba. Se obtiene un F1 del 0,9 y un área bajo la curva ROC del 0,95; de nuevo, prediciendo sobre los datos originales. Veamos ahora los resultados del mismo modelo al predecir sobre datos sintéticos:
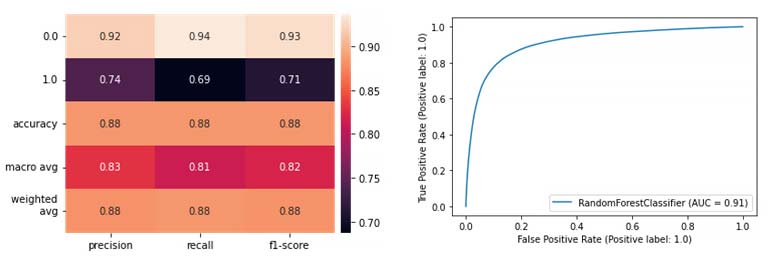
Salvando cambios poco significativos producto de la aleatoriedad, lo más destacable, a la vista de estos resultados, es el decremento de la exhaustividad (recall) y la precisión de la clase positiva hasta 0,69 y 0,74, respectivamente, disminuyendo por tanto el área bajo la curva ROC a 0,91.
Sin embargo, la conclusión prominente de esta prueba es que el modelo de Random Forest, habiendo sido entrenado con los datos originales, obtiene un rendimiento muy similar al predecir sobre datos sintéticos de nuestra GAN.
Ventajas del uso de datos sintéticos en salud
Concluimos que, mediante una arquitectura GAN, pueden generarse no sólo imágenes y sonidos sintéticos a partir de ejemplos previos, sino también datos tabulares que pueden resultar útiles en el entorno empresarial para facilitar el desarrollo y evaluación de cualquier aplicación de aprendizaje automático.
En este caso particular, el potencial de estos datos sintéticos es abrumador, pues permiten generar un flujo continuo de datos que puede servir para evaluar aplicaciones en un entorno simulado cercano a los desarrolladores y sin vulnerar la privacidad de sus propietarios. Lo cual abre un camino de posibilidades, en concreto en el ámbito de la salud, debido a la dificultad que existe en el acceso a datos de salud y al llevar a cabo este tipo de aplicaciones.
