Si tienes datos, puedes crear un negocio inteligente
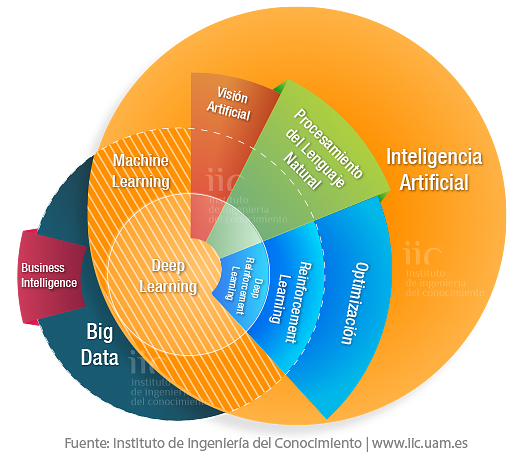
La Inteligencia Artificial necesita Big Data
Los datos son actualmente fuente de aprendizaje de sistemas, software y aplicaciones que están presentes en nuestra vida y trabajo diarios.
Big Data
En la era del dato, las empresas disponen de gran cantidad de información, a partir de las que tomar decisiones estratégicas.


Inteligencia Artificial
La IA da sentido a los datos, identifica cuáles serán útiles y los patrones existentes entre ellos para mejorar los procesos de negocio.


Campos como el Machine Learning y el Procesamiento del Lenguaje Natural convierten los datos en la información que necesitan para conseguir esa Inteligencia Artificial que extraiga conclusiones, haga predicciones o se comunique con nosotros.
Cuantos más datos tengamos, más fiable y representativa será la muestra del proceso que queremos automatizar, y mejor va a funcionar el software que se genere.
Soluciones de Big Data e Inteligencia Artificial para tu negocio
La experiencia del IIC de más de 30 años como centro pionero en Inteligencia Artificial, te ayudará a crear tu negocio más inteligente.