
En la lingüística computacional y el procesamiento de lenguaje natural (PLN) se utilizan conjuntos de textos que representan una muestra representativa de un dominio/tema/lengua concretos, para tratar muchas tareas y problemas. A estos textos se les denomina corpus.
Tal y como se tratamos en el post Retos de corpus reales en PLN: representatividad y equilibrio, los corpus pueden no estar equilibrados (balanceados). De hecho, en nuestro día a día en el Instituto de Ingeniería del Conocimiento (IIC), los datos con los que trabajamos suelen estar desbalanceados. Esto suele presentar un reto para el equipo que trabaja en el proyecto que se está desarrollando. Este post explica cómo afectan los corpus desequilibrados en los proyectos y algunas posible soluciones, todo mediante un ejemplo práctico en proyecto tipo.
Clasificación multiclase de categorías y desbalanceo de un corpus médico
Algunos de los proyectos en los que trabajamos buscan dar solución a un problema de clasificación de categorías multiclase. Esto es, dado un texto, clasificarlo en una categoría de todas las posibles. Para ello, a veces seguimos una estrategia de embeddings de un modelo del lenguaje, como la que vamos a exponer a continuación; siguiendo la metodología de anotación que utilizamos en el IIC.
El ejemplo que analizaremos es un corpus médico, concretamente de triajes de urgencias, que debe ser clasificado en las diferentes especialidades médicas, según el motivo de la urgencia.
Tras hacer una anotación de 2000 textos, se divide el corpus etiquetado en dos conjuntos aleatorios:
- Textos para train: sirven para entrenar al modelo en la tarea.
- Textos para test: sirven para evaluar el acierto del modelo en la tarea.
La distribución de las categorías en cada conjunto es la siguiente:
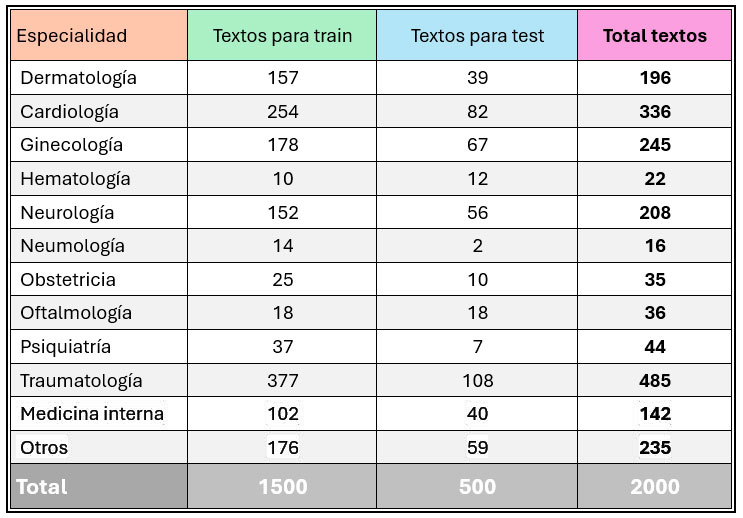
Tabla 1. Distribución de las categorías por conjunto de textos
Cuando tenemos un proyecto de clasificación en el que la distribución de las categorías es similar al que muestra la tabla 1, es decir, en el que hay categorías representadas en muchos textos y hay categorías que apenas aparecen en el corpus, podemos afirmar que tenemos un corpus desbalanceado para esta tarea. Así, al haber categorías con tan pocos textos, hablamos de categorías infrarrepresentadas, o lo que es lo mismo, categorías con poca presencia en el corpus.
Problemas de un corpus desbalanceado
Algunos de los problemas típicos que conlleva el fenómeno de un corpus desbalanceado son:
- Escasa definición de las categorías infrarrepresentadas en las guías de anotación.
- Dificultad para que el modelo aprenda esas etiquetas.
- Dificultad para evaluar el rendimiento del modelo en esas etiquetas.
Escasa definición de las categorías infrarrepresentadas en las guías de anotación
 En las guías de anotación se van concretando los criterios de anotación para cada una de las categorías en base a los textos que van apareciendo en la preanotación (fase en las que se construyen principalmente las guías de anotado[1]) y, en menor medida, en la anotación. El número de textos que se etiquetan durante la preanotación y la anotación, en el caso de las infrarrepresentadas, es escaso y, por tanto, los criterios para estas categorías suelen ser muy generales y muy centrados en el tipo de textos que se hayan observado.
En las guías de anotación se van concretando los criterios de anotación para cada una de las categorías en base a los textos que van apareciendo en la preanotación (fase en las que se construyen principalmente las guías de anotado[1]) y, en menor medida, en la anotación. El número de textos que se etiquetan durante la preanotación y la anotación, en el caso de las infrarrepresentadas, es escaso y, por tanto, los criterios para estas categorías suelen ser muy generales y muy centrados en el tipo de textos que se hayan observado.
Por ejemplo, para el caso de hematología, asumamos que han aparecido en la preanotación un número de textos parecido al del proceso de anotación, es decir, se han visto unos 20 textos en la fase de preanotación. Los tipos de trastornos relacionados con hematología, las palabras clave, los términos y todos los indicadores que los criterios de anotación van a recoger y que indican que un texto es de hematología son, principalmente, los que se derivan de esos 20 textos.
Obviamente, la complejidad y variabilidad de los criterios para hematología van a ser escasas en comparación con las de los criterios de cardiología, donde el número de textos anotado es muy superior y, por tanto, la casuística revisada para este tipo de patologías es mayor.
La escasez o generalidad de criterios puede derivar en problemas para etiquetar otros textos más complejos o que no se adhieren a ninguno de los criterios descritos. También se puede incurrir en inconsistencias en el anotado, al faltar criterios concretos para ciertas casuísticas de una categoría.
Dificultad para que el modelo aprenda las infrarrepresentadas
Al modelo le ocurre que, cuantos más textos vea de una categoría, más fácil le es entender esa categoría y, por tanto, detectar los textos que pertenecen a ella. La poca presencia de ciertas categorías en un corpus suele implicar que el modelo de lenguaje no sea capaz de obtener un buen rendimiento en esas categorías infrarrepresentadas.
 Por tanto, es fácil entender que un modelo de lenguaje sea capaz de predecir mejor los textos de traumatología que los de neumología: hay mucha diferencia entre el número de textos que ha “visto” para entender cuándo asignar cada una de esas categorías. No tiene ni 20 ejemplos para neumología, oftalmología o hematología y, por tanto, le va a costar generalizar cuándo asignar esas etiquetas. Por lo menos, podemos afirmar que no va a saberlo hacer tan bien como para categorías como traumatología o cardiología, en la que el modelo ha revisado más de 200 textos para cada una.
Por tanto, es fácil entender que un modelo de lenguaje sea capaz de predecir mejor los textos de traumatología que los de neumología: hay mucha diferencia entre el número de textos que ha “visto” para entender cuándo asignar cada una de esas categorías. No tiene ni 20 ejemplos para neumología, oftalmología o hematología y, por tanto, le va a costar generalizar cuándo asignar esas etiquetas. Por lo menos, podemos afirmar que no va a saberlo hacer tan bien como para categorías como traumatología o cardiología, en la que el modelo ha revisado más de 200 textos para cada una.
Cabe destacar que el rendimiento de una categoría, a priori, no se puede medir por la presencia de la misma en el corpus, puesto que dependiendo de la complejidad que entrañe una categoría, el modelo va a necesitar más o menos textos para aprenderla.
Por ejemplo, en dos proyectos diferentes para los que tenemos el mismo número de textos y de categorías, y para los que tenemos una etiqueta con tan solo 20 textos en el conjunto de train: si la categoría es más sencilla en un proyecto que en el otro, es probable que el rendimiento del modelo sea diferente para cada problema. O en el caso que nos ocupa, quizá podemos suponer que el número de textos de medicina interna que necesita ver el modelo para tener un buen rendimiento es mayor que para aprender a detectar los textos de oftalmología. Porque la propia naturaleza de la especialidad de medicina interna es más compleja y amplia que la de oftalmología.
Dificultad para evaluar el rendimiento del modelo en las infrarrepresentadas
 Por último, el acierto del modelo en las categorías infrarrepresentadas puede no ser representativo del desempeño del modelo.
Por último, el acierto del modelo en las categorías infrarrepresentadas puede no ser representativo del desempeño del modelo.
Para entenderlo, si el modelo etiqueta bien los dos textos de test que tiene la categoría neumología, digamos que el modelo tendrá un 100% de acierto; ahora bien, si falla uno de ellos, el acierto baja al 50%; y si no acierta ninguno, el acierto sería del 0%. Esta métrica no es comparable ni tan sólida como las de otras categorías, como puede ser cardiología, donde para que el acierto del modelo baje al 50%, los textos fallados tienen que ser 41. Por todo ello, las métricas de acierto del modelo para las categorías infrarrepresentadas tienen que ser entendidas y consideradas como lo que son: poco representativas del desempeño real del modelo.
Conclusiones de un corpus desbalanceado
Los corpus con los que trabajamos en nuestro día a día suelen estar desbalanceados y es imprescindible conocer los desafíos que esto nos supone. Siempre que el problema necesite de una anotación, la parte infrarrepresentada va a impactar en las guías de anotación, quedando, seguramente, poco definida y concreta. Si se necesita entrenar un modelo con esos datos, es imprescindible tener presente que al modelo seguramente le cueste aprender las categorías infrarrepresentadas y que, una vez entrenado, el acierto del modelo sobre los datos con poca representación en el corpus no sea muy representativo del desempeño real.
Es importante destacar que, por ejemplo, en un problema de clasificación multiclase, el criterio para considerar una categoría infrarrepresentada o con suficiente presencia en un corpus depende del tipo de problema que se quiera resolver, de las necesidades del cliente, del rendimiento general del modelo, y de otros muchos factores que vamos determinando y descubriendo según avanza el proyecto.
En el siguiente post de esta serie sobre categorías infrarrepresentadas, veremos algunas posibles soluciones a los desafíos que presentan los corpus desbalanceados.
[1] Para conocer los conceptos de preanotación, guías de anotado, etc., se recomienda leer este whitepaper sobre la metodología de anotación que se sigue en el IIC.
