
En pleno boom de la inteligencia artificial generativa, con la irrupción de modelos como ChatGPT, todo parecía posible. Tareas que históricamente siempre requerían desarrollar modelos de lenguaje específicos para dominios concretos, parecían resolverse con escribir un buen prompt. Redactar textos perfectamente adecuados para distintos ámbitos e idiomas, resolver preguntas complejas e incluso programar, parecían tareas triviales para estos nuevos sistemas.
Con el tiempo, esa euforia inicial dio paso a un entendimiento más realista. Cada vez comprendemos mejor la complejidad de la tecnología, lo que nos permite a su vez ver con mayor claridad sus límites.
Sistemas de RAG y embeddings
Un buen ejemplo de los desafíos actuales en las soluciones de inteligencia artificial, son los sistemas RAG (Retrieval-Augmented Generation), una técnica que combina la recuperación de información con la generación de texto natural.
 En un escenario ideal, los sistemas RAG permiten responder con precisión a preguntas basándose en información externa al modelo de lenguaje. Sin embargo, en la práctica, nos encontramos con diversos obstáculos:
En un escenario ideal, los sistemas RAG permiten responder con precisión a preguntas basándose en información externa al modelo de lenguaje. Sin embargo, en la práctica, nos encontramos con diversos obstáculos:
- Recuperaciones poco precisas.
- Dificultades para escalar la técnica a problemas más amplios o contextos que no se ajustan a las necesidades del modelo.
- El ritmo de mejora de estas herramientas comienza a ralentizarse.
Esto se debe, en parte, a que los modelos generativos —por muy potentes que sean— no son el único componente crítico en soluciones basadas en IA. Especialmente en sistemas no triviales como RAG, no basta con conectar un modelo de lenguaje a una base de datos, es imprescindible afinar con precisión cómo se representa y accede al conocimiento. Y aquí es donde entran en juego los embeddings, una pieza clave en este proceso.
Cómo funcionan los embeddings
Los embeddings son representaciones numéricas que transforman la información —en nuestro caso, texto— en vectores dentro de un espacio vectorial. Estos vectores capturan relaciones de significado como frases, párrafos o documentos similares estarán próximos entre sí, mientras que aquellos menos relacionados estarán más alejados. Por ejemplo, en un espacio vectorial bien construido, los vectores de “ley” y “juez” estarán cerca uno del otro, y a su vez lejos de conceptos como “fotosíntesis”.
Este mecanismo es fundamental para el buen funcionamiento del RAG. Si los embeddings no capturan bien el dominio específico en el que trabajamos, la recuperación de documentos será irrelevante o poco útil, sin importar cómo de avanzado sea el modelo generativo.
Por tanto, si queremos mejorar nuestros sistemas de RAG, debemos prestar especial atención a cómo representamos el conocimiento mediante embeddings, ya que de ello depende en gran parte la calidad de las respuestas generadas.
Evaluación de un modelo de embeddings en español con MTEB
 En el Instituto de Ingeniería del Conocimiento (IIC), hemos investigado en el entrenamiento de modelos de embeddings multilingües, con un enfoque especial en el español.
En el Instituto de Ingeniería del Conocimiento (IIC), hemos investigado en el entrenamiento de modelos de embeddings multilingües, con un enfoque especial en el español.
Para evaluar el rendimiento de nuestros modelos, utilizamos el benchmark MTEB (Massive Text Embedding Benchmark), una suite de tareas que permite medir la calidad de los embeddings en contextos diversos como clasificación, clustering, re-ranking y, especialmente, recuperación de información (retrieval).
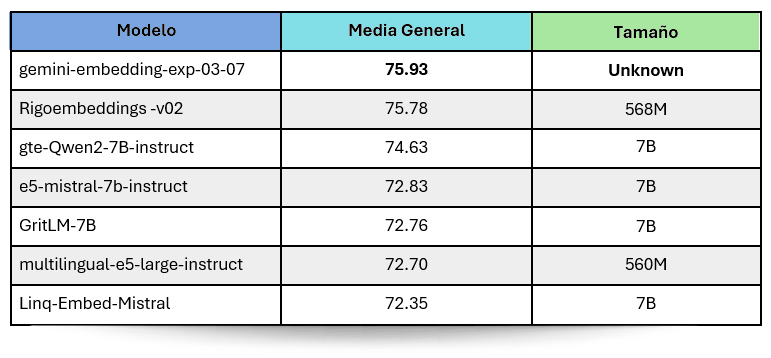
Uno de nuestros principales objetivos era entrenar un modelo de lenguaje competitivo para tareas en español. En las siguientes tablas presentamos los resultados obtenidos y cómo se comparan con otros modelos de referencia ampliamente utilizados.
Separación de tareas: Retrieval vs. Resto del benchmark
El benchmark MTEB contiene tareas de muy distinta naturaleza. En nuestro caso, decidimos separar las tareas de recuperación de información o “Retrieval” del resto, ya que estas suelen tener características particulares y un peso muy relevante en aplicaciones reales como buscadores semánticos o sistemas de preguntas y respuestas.
De este modo, presentamos dos conjuntos de resultados:
- Media en tareas de retrieval.
- Media general considerando todas las tareas del benchmark.
Resultados en tareas de retrieval
Estas tareas consisten en recuperar los textos más relevantes dada una consulta. En MTEB, esto se evalúa usando datasets de distintos idiomas, incluyendo varios en español. A continuación, se muestran los resultados promedio para cada modelo evaluado:
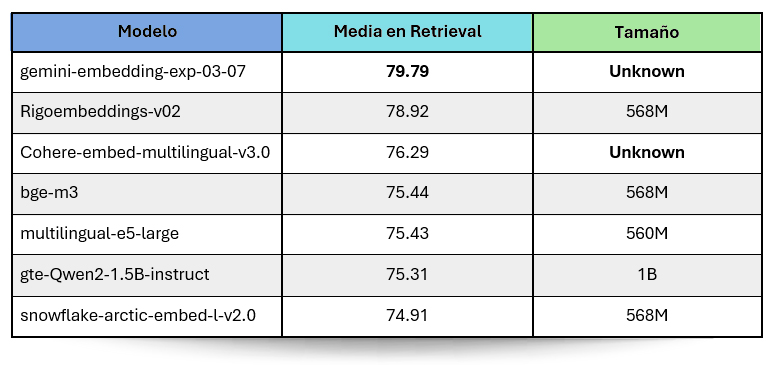
Resultados en todas las tareas del benchmark
Optimización de modelos de Embeddings en español para recuperación y generación de información
En los sistemas de recuperación y generación de información (por sus siglas en inglés, RAG), los modelos generativos han demostrado ser muy eficientes en tareas como la síntesis de contextos y la respuesta coherente a preguntas.

Sin embargo, uno de los mayores retos sigue siendo la parte de recuperación de información. A menudo, los modelos no logran recuperar de manera eficiente los pasajes relevantes a partir de grandes volúmenes de datos, por lo que proponemos mejorar el modelo de embeddings.
En este punto, decidimos centrarnos en mejorar uno de los componentes clave en la arquitectura de RAG: el modelo de embeddings. Para ello, optamos por entrenar un modelo de lenguaje especializado en español, ya que muchos de los modelos disponibles son optimizados para inglés y tienen dificultades para manejar correctamente el idioma español.
Datos utilizados y minado de Hard Negatives
Para ello, partimos de datasets como MS MARCO y su versión multilingüe mMARCO, un conjunto de datos de consultas realizadas a Bing con respuestas generadas por humanos. Este dataset contiene tripletas: consulta, pasaje positivo (el que responde correctamente a la consulta) y pasaje negativo (irrelevante para la consulta).
La verdadera clave para mejorar la recuperación es el hard negative, es decir, pasajes que, aunque parecen relevantes a primera vista, no lo son. Esto desafía al modelo a aprender a distinguir entre información útil y no útil, incluso cuando los pasajes negativos son sutilmente parecidos a los positivos.
Proceso de minado de Hard Negatives
Para generar estos hard negatives, utilizamos un modelo de embeddings previamente optimizado para inglés (como el BGE-large-eng de Beijing Academy of Artificial Intelligence).
Con este modelo, codificamos las consultas y pasajes positivos en inglés y, mediante la distancia entre embeddings, encontramos los pasajes más similares que no sean el pasaje positivo. A continuación, extraemos los índices de estos pasajes similares y los aplicamos al dataset en español.
Comparación de Embeddings
La comparación de embeddings es crucial pero debido a la gran magnitud del dataset (¡más de 39 millones de consultas y pasajes!), este proceso se volvió un desafío en términos de tiempo de cómputo. Para abordar esto, probamos varias soluciones:
- Comparación Aleatoria: Desarrollamos un algoritmo que seleccionaba aleatoriamente un subconjunto de pasajes y calculaba la distancia coseno entre las consultas y los pasajes. Sin embargo, este método tenía limitaciones en cuanto a la calidad de los hard negatives, ya que solo analizaba una fracción pequeña del total de datos.
- Búsqueda Semántica con Sentence Transformers: Aquí es donde realmente mejoramos. Usamos Sentence Transformers para realizar una búsqueda semántica más eficiente y de alta calidad. Con la ayuda de 8 GPUs RTX 3090, procesamos y codificamos los 39 millones de queries y pasajes positivos en solo 56 horas. Este proceso nos permitió realizar una búsqueda mucho más precisa y obtener los top K pasajes más relevantes.
Fine-tuning del Modelo de Embeddings
 Una vez que teníamos los datos listos, el siguiente paso fue ajustar el modelo para mejorar su capacidad de recuperación en español. Para ello, seleccionamos el modelo BAAI/bge-m3, un modelo multilingüe que mostró un buen rendimiento en benchmarks previos. La razón de nuestra elección fue que, al estar bien documentado y optimizado para ajustes, nos permitió una integración eficiente.
Una vez que teníamos los datos listos, el siguiente paso fue ajustar el modelo para mejorar su capacidad de recuperación en español. Para ello, seleccionamos el modelo BAAI/bge-m3, un modelo multilingüe que mostró un buen rendimiento en benchmarks previos. La razón de nuestra elección fue que, al estar bien documentado y optimizado para ajustes, nos permitió una integración eficiente.
Proceso de Fine-tuning
El ajuste más preciso del modelo se realizó en varias etapas:
- Carga del modelo preentrenado: Usamos la API de Hugging Face para cargar el modelo y su arquitectura.
- Preprocesamiento de datos: Cargamos y tokenizamos las consultas y los pasajes en formato JSON.
- Entrenamiento: Configuramos los parámetros de entrenamiento (como tasa de aprendizaje, número de épocas y recursos de hardware). Durante el entrenamiento, medimos la pérdida con entropía cruzada, lo que permitió al modelo mejorar progresivamente su rendimiento.
Al seguir este enfoque de entrenamiento de embeddings, hemos logrado alcanzar la segunda posición en los benchmarks, situándonos únicamente por debajo de Gemini.
Este resultado refleja la efectividad de nuestro proceso de entrenamiento, lo que no solo valida la metodología basada en Hard Negatives, sino que también abre la puerta a la posibilidad de obtener rendimientos aún mejores en el futuro.
Este progreso gradual tiene el potencial de optimizar significativamente la eficiencia de las búsquedas en espacios vectoriales, como lo demuestra el caso del modelo RAG.
Como conclusión, este avance sienta las bases para seguir perfeccionando las técnicas utilizadas en el IIC y obtener resultados cada vez más precisos y competitivos en la mejora y evaluación de un modelo de embeddings en español.
