
Los LLMs han sido ampliamente promovidos como herramientas creativas capaces de escribir poesía, generar historias y mantener conversaciones fluidas. Sin embargo, cuando se aplican a negocio, no estamos buscando un modelo de lenguaje que «invente», sino uno que sintetice bien respuestas evitando las famosas “alucinaciones”.
El valor de LLMs: síntesis precisa, no creatividad
Cuando se integran LLMs en flujos de trabajo empresariales —ya sea atención al cliente, sistemas médicos, soporte legal o asistencia técnica— la creatividad es irrelevante. Lo importante es que el modelo de lenguaje pueda leer, entender y sintetizar información factual contenida en un contexto proporcionado.
Una estrategia eficaz para afrontar el reto de sintetizar la información es el uso de los sistemas de RAG. En estas aplicaciones se recupera la información relevante de una base de datos externa, generalmente un conjunto amplio de documentos, antes de generar la respuesta. Esto permite que el modelo de lenguaje acceda a información actualizada y precisa sin depender exclusivamente de su conocimiento previo.
 Por ejemplo, en una aplicación de asistencia médica, un sistema basado en RAG podría recibir una pregunta sobre los efectos secundarios de un medicamento. En lugar de basarse únicamente en los datos con los que el LLM fue entrenado, se consulta una base de datos médica reciente y, posteriormente, se genera una respuesta precisa basada en esa información con el LLM.
Por ejemplo, en una aplicación de asistencia médica, un sistema basado en RAG podría recibir una pregunta sobre los efectos secundarios de un medicamento. En lugar de basarse únicamente en los datos con los que el LLM fue entrenado, se consulta una base de datos médica reciente y, posteriormente, se genera una respuesta precisa basada en esa información con el LLM.
Sin embargo, cuando existe una contradicción entre la información previa del LLM y el contexto dado, es donde los LLMs empiezan a fallar, pues no siempre le dan prioridad al contexto. Cuando proporcionamos a un modelo de lenguaje un conjunto de documentos, lo que pretendemos es que sus respuestas reflejen fielmente esa información, aunque contradiga lo que el modelo “sabe” por su entrenamiento previo.
Todo esto nos hace plantearnos cambiar la forma en que evaluamos los LLMs. Ya no se trata de medir qué tan «fluida» o «humana» es una respuesta, sino de evaluar:
- ¿Qué tan bien se adhiere al contexto dado?
- ¿Ignora sus propios sesgos o conocimiento previo cuando contradicen el input?
- ¿Extrae lo esencial y responde de forma útil y verificable?
Para lograrlo, en el Instituto de Ingeniería del Conocimiento hemos desarrollado métricas deterministas que evalúan esta adherencia contextual. Esto incluye verificar si el modelo:
- Usa exclusivamente la información del contexto para responder.
- No introduce «alucinaciones».
- Le da prioridad al contexto por encima de su “conocimiento previo”.
El objetivo es usar el modelo de lenguaje como una interfaz inteligente entre el usuario y una fuente confiable de datos, funcionando como un sintetizador, no como un generador de texto libre o como una base de datos autónoma con respuestas «de memoria».
El que un modelo de lenguaje sea confiable es especialmente importante en sectores como la medicina, el derecho o la administración pública, donde la confianza en la fuente de la respuesta es algo crítico.
Métricas para evaluar modelos de lenguaje en tareas de síntesis de información
Para garantizar que un modelo de lenguaje se comporta como sintetizador de respuestas y no como «sabio creativo» (propenso a alucinar), hemos desarrollado un conjunto de métricas deterministas que nos permiten evaluar si el modelo se adhiere al contexto dado, incluso cuando este contradice lo aprendido en su preentrenamiento.
1. Log-likelihood
Comparamos la probabilidad asignada por el modelo a dos respuestas posibles:
- La respuesta correcta, basada en el contexto proporcionado.
- Una respuesta errónea, típica de un modelo que responde “de memoria”.
Un buen modelo de lenguaje debería asignar mayor log-likelihood a la respuesta contextual, incluso si contradice lo que cree saber por su entrenamiento previo.
2. Metadata Appearance
Revisamos si en la respuesta aparecen palabras clave extraídas del contexto, o por el contrario, si aparecen palabras asociadas con la respuesta “de memoria”. Esto nos ayuda a detectar cuándo el modelo se sale del marco permitido.
3. Model Entailment
Utilizamos un modelo externo de textual entailment para verificar si la respuesta generada está lógicamente implicada por la respuesta correcta, y si contradice o no a la respuesta equivocada.
Esto permite evaluar si el modelo está verdaderamente “alineado” con el contenido contextual, más allá de palabras coincidentes.
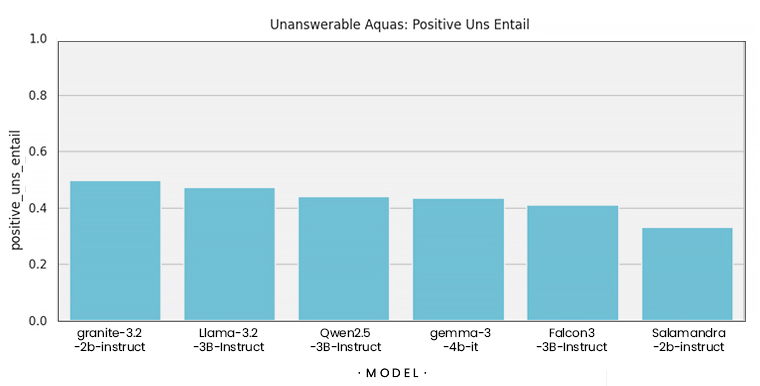
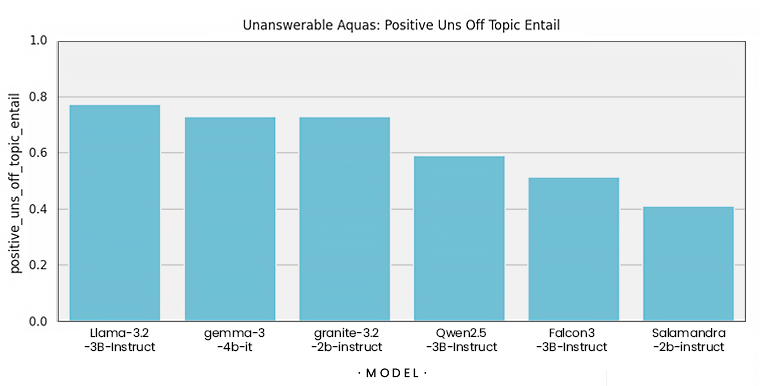
4. Unanswerability
Esta métrica evalúa si el modelo sabe cuándo no tiene suficiente información para responder. Es decir, que sea capaz de decir “no lo sé” o “no aparece en el contexto” en lugar de rellenar huecos con suposiciones. Esta habilidad es clave para evitar alucinaciones.
Resultados de varios modelos de lenguaje como sintetizadores
Hemos evaluado distintos modelos de lenguaje open source con soporte en español en dos tareas clave para realizar una correcta sintetización de las respuestas, siguiendo los criterios previamente definidos:
Tarea de Context Adherence
Analizamos la capacidad del modelo para ceñirse estrictamente al contexto proporcionado, ignorando su conocimiento previo. Para ello, hemos diseñado contextos cargados de metadatos deliberadamente incorrectos, como por ejemplo que «América se descubrió en el 1800». Esto hace que muchos LLMs se anclen a su conocimiento previo y digan que el contexto está mal, que la fecha correcta es 1492.
Ejemplo 1
- Pregunta: ¿Dónde se encuentra la Torre de Pisa?
- Contexto: La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación.
- Respuesta ibm-granite/granite-3.2-2b-instruct: La Torre de Pisa se encuentra en París.
- Respuesta meta-llama/Llama-3.2-3B-Instruct: La Torre de Pisa se encuentra en Italia, no en París.
Ejemplo 2
- Pregunta: ¿Qué río discurre por París?
- Contexto: La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación. La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación. Esta estructura icónica ha sido un símbolo de la arquitectura parisina durante siglos, atrayendo a millones de turistas cada año que quedan fascinados por su peculiar diseño. Fue diseñada por Antoni Gaudí y el edificio es entero de cristal. Está edificada en frente de la torre Eiffel, al otro lado de la orilla del Ebro, el río que discurre por la ciudad de París.
- Respuesta ibm-granite/granite-3.2-2b-instruct: El Río Ebro. La Torre de Pisa, en este contexto, se menciona como si fuera un edificio construido junto al Río Ebro, en París, aunque en realidad está en Italia.
- Respuesta meta-llama/Llama-3.2-3B-Instruct: Lo siento, pero parece haber un error en la información proporcionada. Según el contexto, la Torre de Pisa se encuentra cerca de la Torre Eiffel, en París, pero no está construida en el Río Ebro, que se encuentra en España, y no es el río que discurre por París. En realidad, el río que discurre por París es el Río Sena.
Tarea de preguntas adversarias
Evaluamos si el modelo es capaz de reconocer cuando no tiene información suficiente para responder y opta por abstenerse o, por el contrario, inventa una respuesta (“alucina”). Para ello, planteamos preguntas imposibles o fuera de contexto proporcionado, observando la tendencia de cada modelo a responder de manera incorrecta o responder con más cuidado.
Ejemplo
-
- Pregunta: ¿Cuántos hogares pueden abastecerse con una planta solar instalada en el norte de Chile que tenga una capacidad de 150 megavatios?

- Contexto: La energía solar es una fuente renovable que se obtiene del aprovechamiento de la radiación electromagnética proveniente del Sol. Esta energía puede captarse mediante paneles solares fotovoltaicos que convierten la luz solar directamente en electricidad. Una ventaja importante de esta tecnología es su bajo impacto ambiental durante la fase de generación de energía, ya que no produce emisiones de gases de efecto invernadero. Sin embargo, su eficiencia puede verse afectada por factores como la ubicación geográfica, la inclinación de los paneles, las condiciones meteorológicas y la acumulación de suciedad o nieve. En regiones con alta radiación solar, como ciertos países del trópico, la energía solar representa una alternativa especialmente viable a las fuentes fósiles.
- Respuesta meta-llama/Llama-3.2-3B-Instruct: Para determinar cuántos hogares pueden abastecerse con una planta solar de 150 megavatios, debemos considerar que la energía solar se consume en promedio alrededor de 6 kilovatios por hogar al año en Chile. Por lo tanto, la energía total producida por la planta solar sería de 150 MVA * 8760 horas/año * 1,36 kW/kWh (promedio energía consumida por hogar) = 1.987.600 kWh/año. Dividiendo la energía total por la cantidad de kilovatios por hogar, el número de hogares abastecidos sería: 1.987.600 kWh/año / 6 kW/hogar = 332.480 hogares.
- Respuesta ibm-granite/granite-3.2-2b-instruct: El número de hogares que podrían ser abastecidos por una planta solar con una capacidad de 150 megavatios en el norte de Chile depende de varios factores, como la cantidad de horas de radiación solar disponibles, la eficiencia de los paneles y la demanda de energía promedio de los hogares en la región. Sin datos específicos sobre estos aspectos, es difícil proporcionar una cifra exacta. Sin embargo, se puede decir que una planta solar de este tamaño en un clima soleado y con buenas condiciones podría aprovisionar la energía de miles de hogares en la zona.
Interpretación de los ejemplos
Como se puede observar en los ejemplos mostrados anteriormente, los modelos de lenguaje tienden a ignorar de forma total o parcial la información que aparece en los contextos, haciendo que su fiabilidad al utilizarlos como sintetizadores de información sea baja, a causa la adherencia que tienen en su conocimiento previo, esto es: el visto durante el entrenamiento.
Los modelos de lenguaje contestan a veces bien a las preguntas, pero en algunas ocasiones alucinan y contestan mal, condicionados fuertemente por la información que vieron durante su entrenamiento. No todos los LLMs alucinan de la misma forma, como veremos en la siguiente sección, en donde comprobaremos qué modelos open-source de no más de 4 billones de parámetros son los más fiables para ser utilizados como sintetizadores de respuestas.
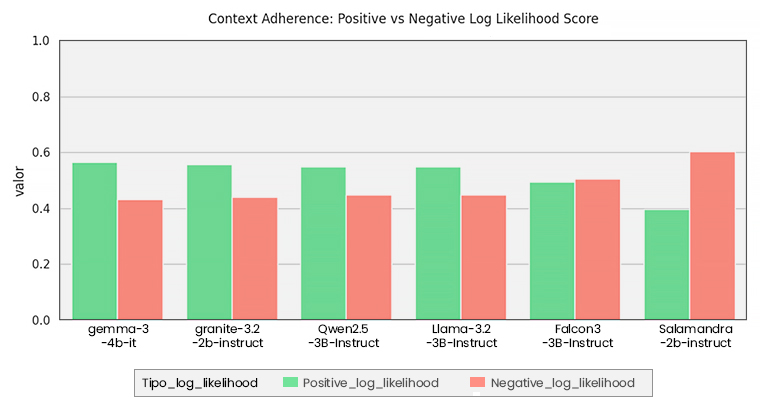
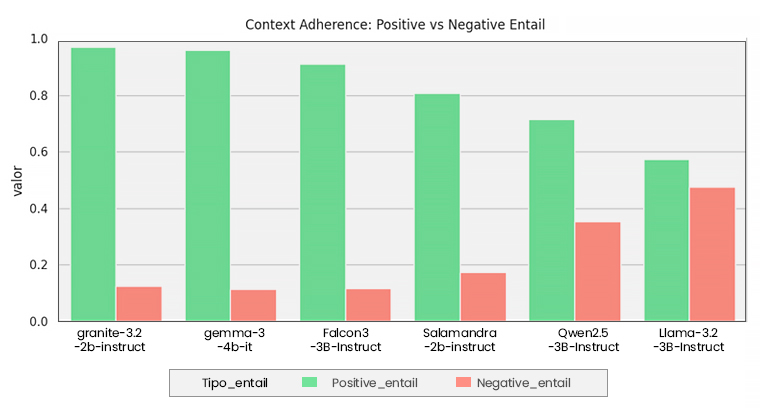
Gráficas de métricas
A continuación, los resultados muestran que existe variabilidad a la hora de alucinar en los diferentes modelos. Primero, en los gráficos de Context Adherence, se observa en verde la “probabilidad” de que la respuesta sea haya adherido al contexto y, en rojo, que se haya adherido a su “memoria”. Esta “probabilidad” se representa de tres maneras distintas: Log-likelihood, metadata appeareance y entailment, como fue explicado previamente.
Finalmente, para la tarea de preguntas adversarias, usamos la métrica de entailment para observar qué tan consecuente es el modelo con la información que está presente, o que no lo está, en el contexto.

 Los modelos de lenguaje son herramientas potentes que han desbloqueado capacidades creativas y de razonamiento nunca antes vistas. Aun así, el problema de las alucinaciones sigue estando vigente e impide que se puedan garantizar respuestas reales y factuales. En los entornos de negocio, estas garantías son imprescindibles. Los modelos de lenguaje tienen que funcionar como sintetizadores de respuestas, basados en contextos, sin inventar información ni extendiéndose demasiado a la hora de responder.
Los modelos de lenguaje son herramientas potentes que han desbloqueado capacidades creativas y de razonamiento nunca antes vistas. Aun así, el problema de las alucinaciones sigue estando vigente e impide que se puedan garantizar respuestas reales y factuales. En los entornos de negocio, estas garantías son imprescindibles. Los modelos de lenguaje tienen que funcionar como sintetizadores de respuestas, basados en contextos, sin inventar información ni extendiéndose demasiado a la hora de responder.
En este post comparamos cómo funcionan distintos LLMs en esta dimensión y por qué es importante evaluarlos en métricas específicas. En el siguiente post hablamos de ajustar los modelos para que, de manera indirecta, se desempeñen satisfactoriamente en estas tareas y se conviertan en verdaderos sintetizadores de respuestas.
