
De la necesidad de contar con grandes modelos de lenguaje (LLMs) competitivos en nuestro idioma, tanto de forma general como en dominios más específicos, surge RigoChat-v2, el modelo de lenguaje generativo en español del IIC. En su desarrollo, investigamos diferentes metodologías para adaptar modelos existentes a varios casos de uso, especialmente relacionados con sistemas de RAG. El objetivo era, a la vez, reducir el coste en tiempo y recursos que normalmente acompaña a la construcción de estos enormes modelos sin comprometer los resultados.
A lo largo de este post y de una segunda entrega que destaca el trabajo con los corpus vamos a ir explicando algunos de los procesos que hemos seguido para obtener RigoChat-v2, y sobre todo los resultados finales de su evaluación en comparación con otros modelos de lenguaje del estado del arte. Sirva como adelanto del artículo científico que publicaremos próximamente y que explicará más rigurosamente estos y algunos pasos intermedios que no vamos a exponer aquí.
¿Por qué reentrenar modelos de lenguaje? El caso de RigoChat-v2
Desarrollar un modelo de lenguaje o LLM desde cero, o simplemente utilizarlo cuando queremos aplicarlo a un caso de uso concreto, puede presentar varias dificultades. El principal problema de los LLMs es que desarrollarlos supone un costoso proceso de entrenamiento que normalmente solo es alcanzable si se cuenta con un enorme poder computacional. Generalmente se utilizan centros de datos de gran tamaño, con miles de GPUs solo para este fin, y tan solo unas pocas compañías tienen la capacidad de contar con esos recursos.
 Por otro lado, utilizarlos tampoco es posible siempre, ya que existe una inevitable correlación entre su tamaño y la destreza a la hora de resolver las tareas que se les piden. Esto significa que los modelos más útiles y efectivos suelen ser, a su vez, los más costosos, haciendo inmanejable el uso privado de estas inteligencias artificiales tan potentes y necesitando acudir a terceros que las ofrezcan.
Por otro lado, utilizarlos tampoco es posible siempre, ya que existe una inevitable correlación entre su tamaño y la destreza a la hora de resolver las tareas que se les piden. Esto significa que los modelos más útiles y efectivos suelen ser, a su vez, los más costosos, haciendo inmanejable el uso privado de estas inteligencias artificiales tan potentes y necesitando acudir a terceros que las ofrezcan.
Además, los LLMs que se utilizan son estáticos y están pensados para usos generales, haciendo que, en ocasiones, sea difícil tratar de ajustarlos por medio de prompting a la tarea que se pretende resolver. No obstante, estas dificultades se pueden mitigar con el conocimiento adecuado.
Ante este panorama, desde el IIC probamos cómo, dado un modelo de tamaño intermedio –y, por tanto, más usable y alcanzable–, podíamos superar a otros modelos del estado del arte de tamaño similar, o incluso a modelos más potentes como GPT-4o, en ciertas tareas y dominios en español. El resultado fue RigoChat-v2, un ejemplo para mostrar cómo, con pocas horas de computación, se pueden lograr unos resultados notables partiendo de modelos pre-entrenados.
Básicamente, lo necesario es:
- Calidad en los corpus para su entrenamiento.
- Un conocimiento y uso adecuado de los algoritmos existentes para entrenar.
- Buenas evaluaciones con las que poder obtener conclusiones.
Los corpus de RigoChat-v2
La preparación de los corpus para reentrenar un modelo de lenguaje existente es esencial si queremos mejorarlo en dominios y tareas concretos. En el caso de RigoChat-v2, pensado para ser un modelo conversacional, se optó por corpus en formato de instrucción, que incluyen preguntas de usuarios y respuestas de LLMs.
El equipo de lingüistas computacionales del IIC es el encargado de trabajar estos conjuntos de textos para asegurar la calidad de los datos con los que se entrenarán los modelos. Se encargan, en concreto, de recopilar los datos, filtrarlos, anotarlos y evaluarlos.
Corpus de entrenamiento
Para la fase de entrenamiento de RigoChat-v2 se trabajó con distintos corpus hasta obtener 3 diferenciados:
- Un corpus masivo de instrucciones, de carácter general y con diferentes calidades. Este corpus tan heterogéneo es ideal para tener reservados ejemplos que luego puedan trasladarse a casos de uso específicos.
- Un corpus de instrucciones de alta calidad. Este corpus es un filtrado del corpus masivo, atendiendo a unos criterios predefinidos.
- Un corpus de preferencias. Este conjunto de datos está formado por conversaciones en las que existen varias respuestas alternativas, donde una de ellas es la mejor y, generalmente, ha sido seleccionada por humanos. Nuevamente, es un filtrado y procesado de los corpus mencionados antes.
Corpus de evaluación
 Por otro lado, se trabajó en cinco corpus de evaluación, que fueron diseñados y anotados en el IIC. Se trata de datos diferentes a los utilizados en el entrenamiento, para evaluar el rendimiento de RigoChat-v2 y otros LLMs en distintos casos de uso relacionados con sistemas de RAG.
Por otro lado, se trabajó en cinco corpus de evaluación, que fueron diseñados y anotados en el IIC. Se trata de datos diferentes a los utilizados en el entrenamiento, para evaluar el rendimiento de RigoChat-v2 y otros LLMs en distintos casos de uso relacionados con sistemas de RAG.
- AQuAS: corpus de alta calidad realizado de forma manual por dos lingüistas computacionales con el fin de evaluar modelos de lenguaje en la tarea de Question-Answering Abstractivo en español. Cuenta con ejemplos en los dominios financieros, seguros, clínico, legal y música.
- RagQuAS: corpus de alta calidad realizado de forma manual por dos lingüistas computacionales que sirve para evaluar sistemas completos de RAG y modelos de lenguaje en la tarea de Question-Answering Abstractivo en español. Cuenta con ejemplos de una gran cantidad de dominios: hobbies, lingüística, mascotas, salud, astronomía, atención al cliente, coches, cotidiano, documentación, energía, esquí, estafas, gastronomía, hobbies, idiomas, juegos, lenguaje, manicura, música, patinaje, primeros auxilios, receta, reciclaje, reclamaciones, seguros, tenis, transporte, turismo, veterinaria, viajes y yoga.
- CAM (evaluación privada): Son preguntas frecuentes (FAQs) sobre temas de consumo de las webs de la Comunidad de Madrid. Las preguntas de los usuarios tienen 3 niveles de degradación: E1, E2 y E3; y el corpus pretende medir la capacidad de los LLMs de comprender y responder con eficacia ante preguntas mal formuladas por faltas de ortografía, más o menos coloquialismos, etc. La tarea también es Question-Answering Abstractivo.
- Tiendas (evaluación privada): corpus de conversaciones multiturno sobre políticas de diferentes empresas relacionadas con la ropa. Question-Answering Abstractivo Multiturno.
- Seguros (evaluación privada): corpus de conversaciones multiturno sobre políticas de diferentes empresas relacionadas con seguros. Question-Answering Abstractivo Multiturno.
En un segundo post ampliaremos este proceso de preparación y refinamiento de los corpus utilizados para entrenar y evaluar RigoChat-v2.
Entrenamiento y cuantizaciones de RigoChat-v2
Una vez creados los corpus, en el apartado de entrenamiento del modelo se realizaron varios experimentos hasta apreciar mejoras notables en las tareas y dominios de interés. En concreto, RigoChat-v2 se basa en el modelo Qwen2.5-7B-Instruct y fue finetuneado mediante el algoritmo de Direct Preference Optimization (DPO) utilizando el corpus de preferencias mencionado más arriba, que contenía 27650 conversaciones en castellano. Por otro lado, el modelo fue entrenado en una única GPU NVIDIA A100 durante 8,5 horas.
Antes, entre todas las pruebas realizadas (resumidas en la Tabla 2), se intentó partir del modelo base Qwen2.5-7B, hacer aprendizaje supervisado con el corpus de instrucciones de alta calidad y, finalmente, repetir el proceso de DPO con el modelo resultante, pero las evaluaciones realizadas no fueron tan buenas como cuando partíamos directamente de Qwen2.5-7B-Instruct. De igual forma, tratamos de ver qué ocurría si solo aplicábamos aprendizaje supervisado, sin DPO, siendo el modelo resultante el que daba los peores resultados de todos.
| Modelo y Algoritmos | Puntuación media basada en Llama-3.1 |
| Instruct | 77% |
| Instruct + SFT | 70% |
| Instruct + SFT + DPO | 72% |
| Instruct + DPO | 79% |
| Base | 68% |
| Base + SFT | 69% |
| Base + SFT + DPO | 72% |
Tabla 2: batería de pruebas realizada sobre el modelo Qwen-2.5 de 7 mil millones de parámetros, partiendo tanto del modelo base como del modelo Instruct.
Como vemos en la Tabla 2, solo logramos superar al modelo del que partimos y queremos mejorar(Qwen2.5-7B-Instruct) si aplicamos tan solo DPO sobre él. Partir del modelo base, aplicar aprendizaje supervisado y, posteriormente, DPO, nos da mejoras, pero no consigue llegar a la altura de la versión con instrucciones. Por último, lanzamos estos mismos experimentos sobre otros modelos, como el Llama-3.1, pero los resultados eran algo peores, siendo el mejor de ellos de alrededor de 78 %.
No probamos a aplicar aprendizaje supervisado con el corpus masivo por el tiempo y coste que supondría y porque sabíamos que había muchos ejemplos de respuestas de poca calidad. En este sentido, y cómo desarrollaremos en el post sobre los corpus de RigoChat-v2, tampoco teníamos un método todo lo robusto que nos gustaría para generar respuestas nuevas de forma sintética y puntuarlas del todo bien.
Sin embargo, sí que entrenamos varios modelos de recompensa basados en Qwen2.5-7B con la intención de aprovechar todos nuestros datos. La idea era utilizar el algoritmo de HYPERLINK «https://arxiv.org/pdf/1707.06347″Proximal Policy Optimization (PPO) sobre nuestro mejor modelo (el que resulta de partir de Qwen2.5-7B-Instruct y aplicarle DPO sobre el corpus de preferencias) y sobre este modelo de recompensa, pero al final decidimos descartar estos experimentos.(el que resulta de partir de Qwen2.5-7B-Instruct y aplicarle DPO sobre el corpus de preferencias) y sobre este modelo de recompensa, pero al final decidimos descartar estos experimentos.
Resultados de RigoChat-v2 y otros LLMs
Por último, evaluamos los distintos LLMs del estado del arte en comparación con RigoChat-v2. Para este benchmark utilizamos una métrica propia basada en Llama-3.1 que evalúa automáticamente la calidad de las respuestas de los LLMs y que definimos al desarrollar nuestro corpus de preferencias. En concreto, en esta investigación asociada, probamos distintos modelos para simular la evaluación humana, y el que más se acercó fue el basado en Llama-3.1.
Así pues, en la siguiente gráfica (Figura 4) se resumen los resultados de aplicar dicho modelo evaluador a las respuestas de los LLMs comparados. Vemos que RigoChat-v2 ofrece una mejora notable con respecto a otros modelos de tamaño similar.
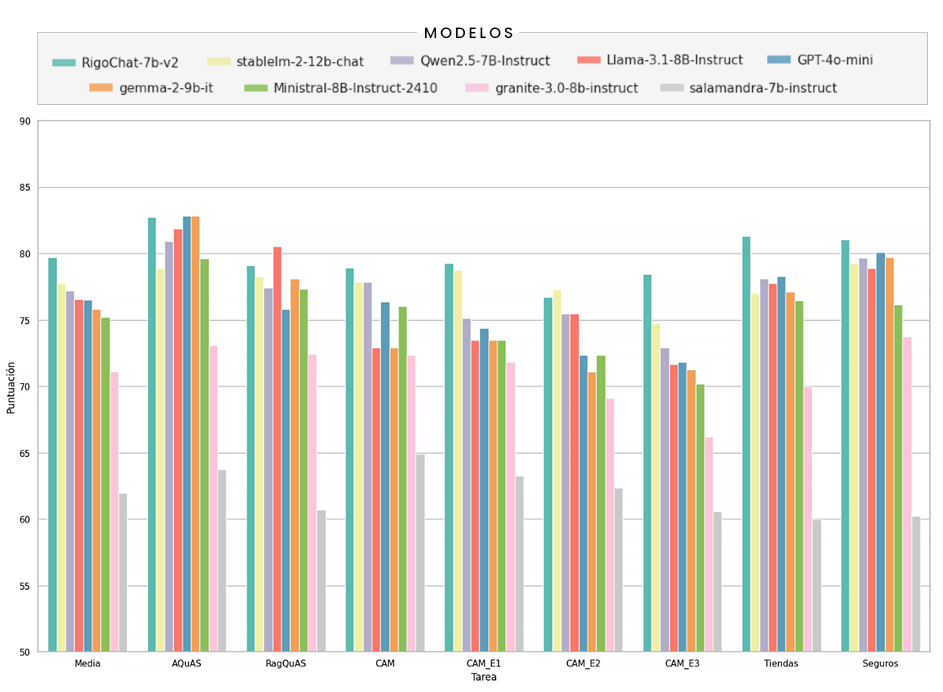
CLICK PARA AMPLIAR LA IMAGEN. Figura 4: comparativa de RigoChat-v2 con otros modelos públicos sobre los corpus de evaluaciones y utilizando una métrica basada en Llama-3.1. Para mayor claridad, el eje de puntuación va de 55 a 90.
También era interesante ver cuál es el rendimiento de RigoChat-v2 si lo comparamos con otros modelos de mayor tamaño pertenecientes a la familia de Qwen-2.5 o con los más potentes, como GTP-4o. La siguiente gráfica (Figura 5) nos muestra esto.
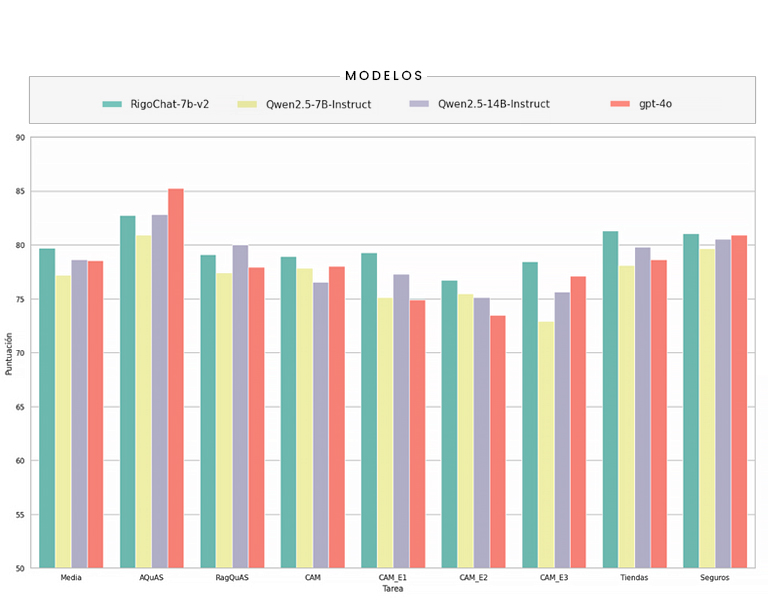
Figura 5: comparativa de RigoChat-v2 y Qwen-2.5-7B frente a otros modelos de tamaño mayor.
Vemos que RigoChat-v2 logra superar a modelos de 14 mil millones de parámetros y que también consigue puntuar mejor que GPT-4o en las diferentes tareas, demostrando así que es posible, con limitados recursos y un tiempo reducido, adaptarnos a los casos de uso de interés.
Una última comparativa que se puede realizar de forma visual es medir cómo de sensibles son los modelos de lenguaje a los coloquialismos, las “jergas” o cualquier tipo de ruido que podamos añadir a las consultas que hagan los usuarios. Para ello, tenemos el corpus de evaluación CAM, donde precisamente contamos, para cada pregunta, diferentes variantes con distintos niveles de degradación. La Figura 6 muestra un evolutivo del desempeño de los modelos en función del ruido que se va añadiendo a las preguntas de los usuarios.
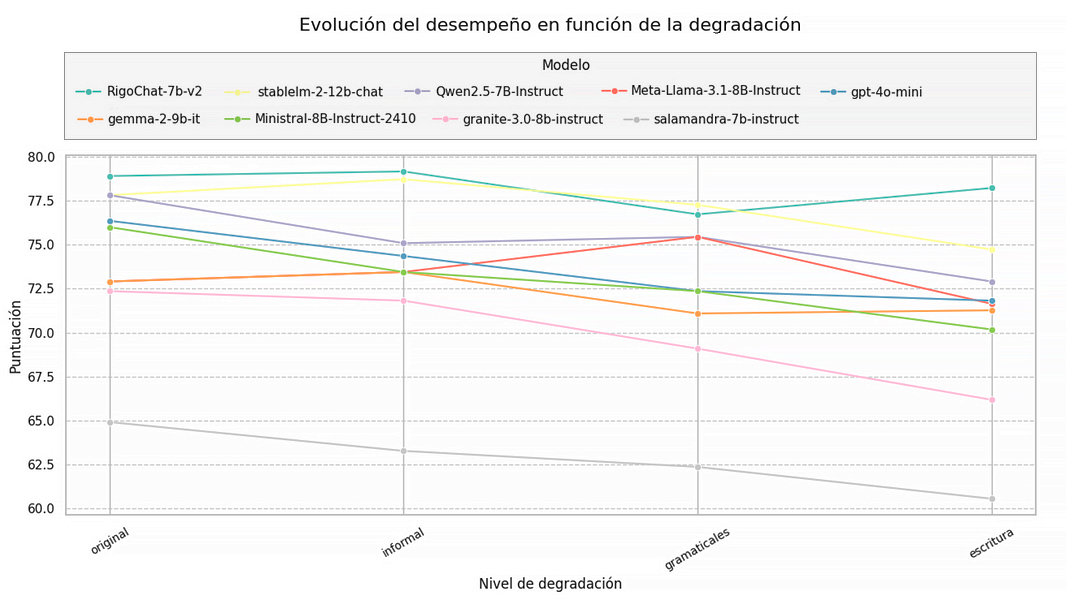
Figura 6: Evolución del desempeño de los LLMs en función de la degradación.
Vemos que la tendencia es decreciente, esto es: los LLMs pierden precisión conforme aumentan los coloquialismos, las jergas, los errores gramaticales, etc. No obstante, RigoChat-v2 en concreto consigue mantener su rendimiento mejor que el resto de los modelos.
Por último, cuantizamos RigoChat-v2 a diferentes tipos de precisión con el fin de poder utilizarlos en infraestructuras más económicas o, directamente, desde el procesador del propio ordenador. Es interesante ver cómo decae el rendimiento del modelo conforme vamos disminuyendo su tamaño y precisión, así que decidimos realizar todas las cuantizaciones posibles con la librería llama.cpp y lanzar la batería de evaluaciones con cada una de ellas. La Figura 7 muestra estos resultados.
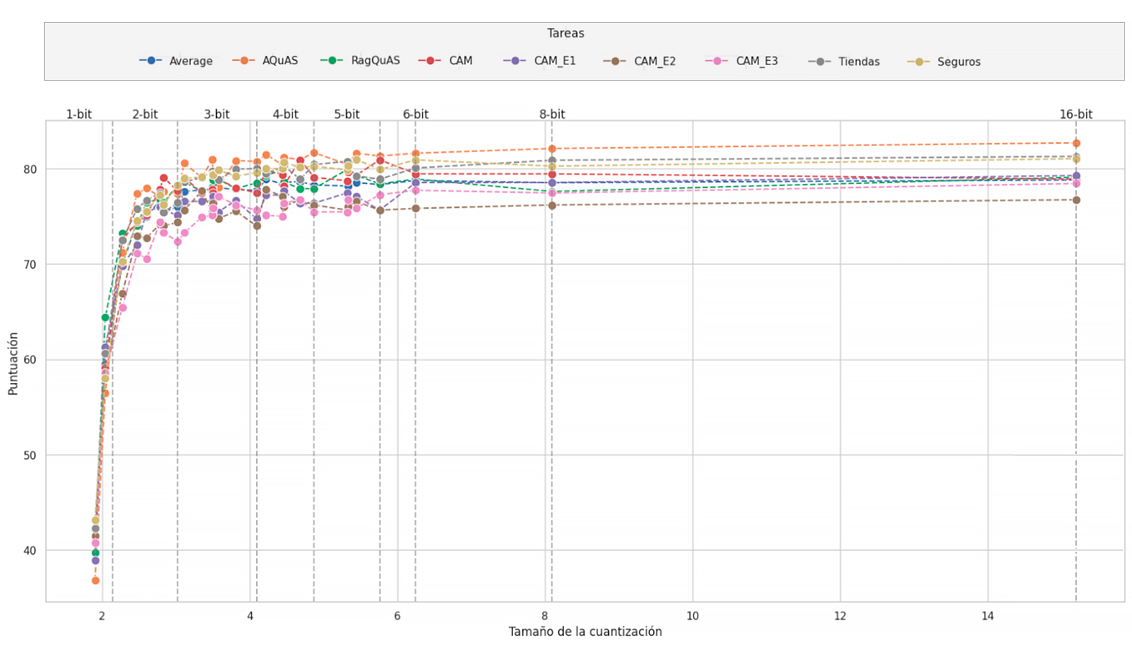
CLICK PARA AMPLIAR LA GRÁFICA. Figura 7: evolución de la puntuación de las diferentes cuantizaciones de RigoChat-v2 en función del número de bits de precisión.
Vemos que, a partir de 3 bits de precisión, los modelos se convierten en alternativas razonables y muy económicas para su uso. Hasta los 5 bits es totalmente factible correr estos modelos en una CPU normal con 16 Gigas de memoria RAM.
Conclusiones de la investigación con RigoChat-v2
Los experimentos realizados desde el IIC y el ejemplo de RigoChat-v2 muestran que se pueden obtener buenos resultados con el uso de hardware limitado, e incluso mejorar modelos de lenguaje del estado del arte en ciertos escenarios. Esto hace posible el acercamiento de los modelos de inteligencia artificial más potentes a los distintos sectores, de forma privada y sin necesidad de tener que acudir a terceros, con el ahorro de recursos que supone.
Para futuras investigaciones, se planea ampliar los corpus de evaluación y entrenamiento, encontrar metodologías más robustas para simular la evaluación humana de forma automática y así aprovechar al máximo nuestros datos y volver a medir cómo de factible es conseguir un modelo base en castellano competente utilizando pocos recursos computacionales. Por otro lado, y en la línea de aprovechar todos nuestros datos, tenemos pendiente la prueba de aplicar Proximal Policy Optimization (PPO) con el modelo de recompensa y con el mejor modelo obtenido con DPO sobre el corpus masivo de instrucciones.
Me interesa RigoChat-v2

RigoChat-v2 es ya un modelo de lenguaje propio del IIC que se encuentra disponible en abierto en Hugging Face y puede usarse para fines comerciales desde AWS Marketplace. Puede adaptarse a distintos dominios y/o sectores para que sea aún más eficiente, reentrenándolo con corpus específicos y representativos. Ofrecemos nuestra metodología y experiencia en PLN para alinearlo según las necesidades de cada organización.
