
Tal y como vimos en el post LLMs como sintetizadores de respuestas, existen algunas limitaciones en los modelos de lenguaje o Large Language Models (LLMs) a la hora de contestar de forma satisfactoria preguntas que se basan en contextos, causado por su conocimiento previo, que en ocasiones entra en conflicto con la información que se le facilita.
 Existe un método para mejorar los modelos de lenguaje a través del algoritmo desarrollado por DeepSeek, GRPO, utilizando datasets clásicos de Question-Answering en español, catalán e inglés. A su vez, vamos a conocer las limitaciones del entrenamiento y posibles mejoras a futuro.
Existe un método para mejorar los modelos de lenguaje a través del algoritmo desarrollado por DeepSeek, GRPO, utilizando datasets clásicos de Question-Answering en español, catalán e inglés. A su vez, vamos a conocer las limitaciones del entrenamiento y posibles mejoras a futuro.
En este post entrenamos un LLM base con GRPO, en concreto el modelo Falcon3-3B-Base, partiendo de un prompt inicial, para que el modelo obtenido pueda extraer de manera correcta los metadatos de un contexto para una pregunta sobre él. Veremos que, definiendo unos criterios sencillos como funciones de recompensa, emerge un comportamiento que deriva en un LLM que sintetiza mejor la información. El modelo está disponible en HuggingFace accesible para utilizarlo con fines de investigación.
Cómo funciona el Closed Question Answering
El Closed Question Answering (CQA) es una tarea del Procesamiento del Lenguaje Natural (PLN) en la que un modelo de lenguaje debe responder preguntas basándose únicamente en un contexto específico.
A diferencia de otros enfoques que permiten respuestas abiertas, en el CQA, la información relevante está acotada al contenido disponible a la información que se proporciona. Esto resulta especialmente útil en aplicaciones donde se requiere precisión y fidelidad en la información que se quiere utilizar como referencia para las respuestas.
Existen dos tipos principales de respuestas en CQA:
- Respuestas extractivas: En este caso, el modelo de lenguaje extrae literalmente un fragmento del contexto proporcionado para responder la pregunta. No genera información nueva, sino que selecciona el texto más adecuado dentro del contenido disponible. Este enfoque es útil para tareas como recuperación de información en documentos legales o médicos, así como extracción de metadatos tales como fechas o lugares.
- Respuestas abstractivas: Aquí el modelo de lenguaje genera una respuesta basada en su comprensión del contexto, reformulando o sintetizando la información en lugar de extraerla textualmente. Por ejemplo, el modelo podría necesitar realizar una operación aritmética para calcular unos costes o comprender el contexto de forma más profunda para deducir desde él las respuestas a preguntas menos triviales, comunes en dominios con lenguajes más de nicho como los ya mencionados documentos legales o médicos.
 Para conseguir un LLM que sea completamente fiel a los contextos dados, proponemos utilizar el algoritmo de GRPO, un algoritmo de aprendizaje por refuerzo, desarrollado por DeepSeek, que necesita de recompensas verificables para aplicarse.
Para conseguir un LLM que sea completamente fiel a los contextos dados, proponemos utilizar el algoritmo de GRPO, un algoritmo de aprendizaje por refuerzo, desarrollado por DeepSeek, que necesita de recompensas verificables para aplicarse.
Una recompensa verificable es una forma totalmente objetiva de medir si una respuesta está bien o mal. Por ejemplo, si en una respuesta debe aparecer una fecha, podemos comprobar si dicha fecha se encuentra dentro del texto generado por el LLM.
Hemos acotado el experimento a la tarea de Extractive Question-Answering y hemos seleccionado datasets clásicos de esta tarea para las pruebas, como veremos a continuación. El entrenamiento del modelo de lenguaje está diseñado para ser ejecutado en 4 GPUs 3090 y, aproximadamente, debería tardar una semana en completarse. El modelo seleccionado ha sido un LLM base de tamaño pequeño: tiiuae/Falcon3-3B-Base.
Prompt inicial
Con el fin de guiar al LLM para que tenga un determinado comportamiento, es necesario definir un prompt para asegurarnos de que las respuestas tengan algo de coherencia. Este prompt es el que se va a utilizar como base para generar, para cada pregunta, una familia de respuestas en las que habrá algunas que sean mejores que otras a ojos de la función de recompensa. Es con este prompt y con múltiples iteraciones del algoritmo de GRPO con lo que lograremos mejorar el modelo.
El prompt es el siguiente:
EXTRACTIVE_QA_PROMPT = «»»A conversation between a User and an AI assistant. Your task is to answer the user’s question based solely on the provided contexts. Provide a concise, clear, and accurate answer in the same language as the User Question.
Contexts:
—
{context}
—User Question:
{question}
Assistant Response:
«»»
Como se puede observar, este prompt contiene dos variables: context y question, que son las que introduciremos en cada ejemplo para que el modelo aprenda a responder de forma satisfactoria.
Corpus de entrenamiento del modelo
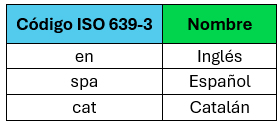 El corpus de entrenamiento del modelo de lenguaje está formado por varios datasets clásicos de Question-Answering donde la información de las respuestas se encuentra estrictamente incluida en los contextos. Los idiomas elegidos son los que se muestran en la tabla de la derecha.
El corpus de entrenamiento del modelo de lenguaje está formado por varios datasets clásicos de Question-Answering donde la información de las respuestas se encuentra estrictamente incluida en los contextos. Los idiomas elegidos son los que se muestran en la tabla de la derecha.
Se ha seleccionado una submuestra de cada fuente, con una semilla para que su creación sea totalmente reproducible, obteniendo la siguiente distribución:
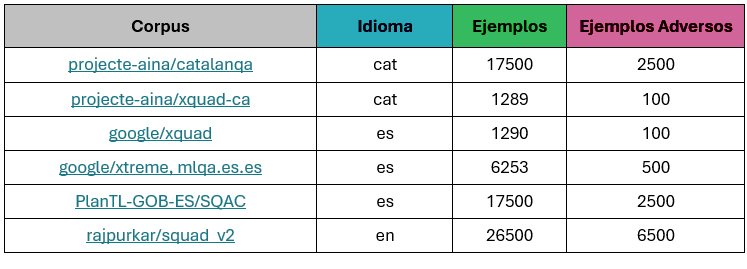
Para generar las preguntas adversarias, se ha dado la vuelta a la columna question, ya que los contextos están ordenados, y se ha muestreado alrededor de un 10% del tamaño original. Además, el squad_v2 cuenta con preguntas adversarias diseñadas de antemano, que también hemos aprovechado.
Algunos ejemplos de textos formateados de estos corpus clásicos son los siguientes:

Como vemos, existe una columna “ground_truth” donde aparece el metadato asociado a la pregunta, en el caso de que esta pueda responderse. Nuestro objetivo será definir una serie de propiedades para que, al aplicar GRPO, nos aseguremos de que el metadato esté incluido en la pregunta y que el modelo no alucina en caso de que la pregunta no pueda responderse.
Criterios de recompensa del modelo de lenguaje
El bucle de entrenamiento de un modelo de lenguaje comprueba cuatro aspectos clave:
- Formato de respuesta:
- El modelo debe generar el final de la respuesta correctamente.
- La respuesta debe empezar con una letra mayúscula.
- Inclusión de metadatos:
- Si la pregunta no es adversaria, el metadato asociado debe estar en la respuesta y los metadatos adversarios no (mirar el siguiente apartado).
- Si la pregunta es adversaria, se verifica que ciertas palabras clave estén presentes en la respuesta (“no”, “not”, “contexto”, “context”).
- Verbosidad controlada:
- El modelo debe ser explicativo, pero de forma controlada. Las respuestas no pueden ser demasiado largas.
- Idioma:
- La respuesta debe estar en el mismo idioma que la pregunta.
Cada una de estas comprobaciones define la función de recompensa final, y se bonifica con un 25% si se cumplen.
Configuración del entrenamiento del modelo
El entrenamiento del modelo de lenguaje está diseñado para aprovechar al máximo las 4 GPUs y, por ello, se ha utilizado DeepSpeed. Se puede ejecutar con las configuraciones ZeRO-2 y ZeRO-3.
En nuestro caso, hemos utilizado ZeRO-2, que optimiza la distribución del estado del optimizador, los gradientes y los pesos del modelo entre las GPUs disponibles. Para más información, revisar el enlace correspondiente.
Las configuraciones de DeepSpeed se han basado en las propuestas del repositorio open-r1, en concreto en el siguiente enlace.
Aunque podríamos haber añadido esta configuración directamente en los argumentos del script de entrenamiento para parametrizarlo, hemos decidido no hacerlo para garantizar la reproducibilidad.
Selección del Checkpoint
Al inicio, la función de recompensa crece rápidamente, pero cuando alcanza valores altos, comienza a oscilar, generando checkpoints con rendimientos variables, como puede observarse en la siguiente gráfica.

Finalmente, hemos seleccionado el checkpoint con mejor puntuación en la evaluación.
Resultados del entrenamiento
A pesar de haber utilizado corpus antiguos y acotados, en una tarea tan simplificada como la de extracción de metadatos sobre preguntas, los resultados son bastante prometedores.
Hemos evaluado el mejor checkpoint utilizando las metodologías definidas en el post de LLMs como sintetizadores de respuestas. Las dos pruebas de evaluación definidas son las mismas:
- Context Adherence: el modelo se adhiere al contexto, ignorando su conocimiento previo. Para ello, hemos definido unos contextos con un montón de metadatos a priori absurdos, como por ejemplo que América se descubrió en el 1800. Esto hace que muchos LLMs se anclen a su conocimiento previo y digan que el contexto está mal, que la fecha correcta es 1492.
- Preguntas adversarias: para medir si el modelo alucina o no al responder cuando no se puede.
Los resultados muestran que el modelo base entrenado con GRPO es mejor que el resto en todas las tareas, destacando su capacidad a la hora de no alucinar. También hemos detectado que sus respuestas suelen ser más cortas.
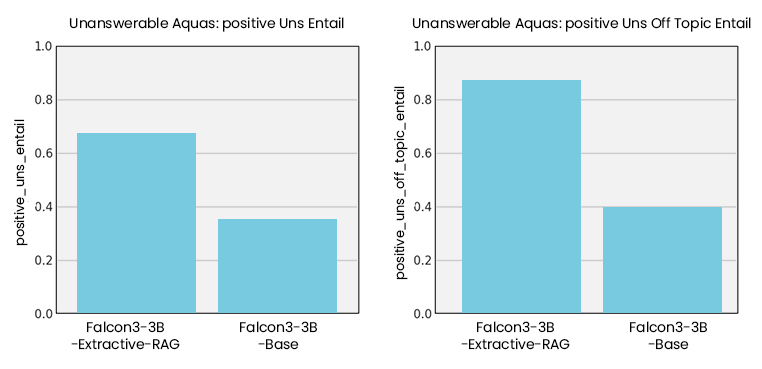
Mejora sobre el modelo base

Comparativa con otros modelos
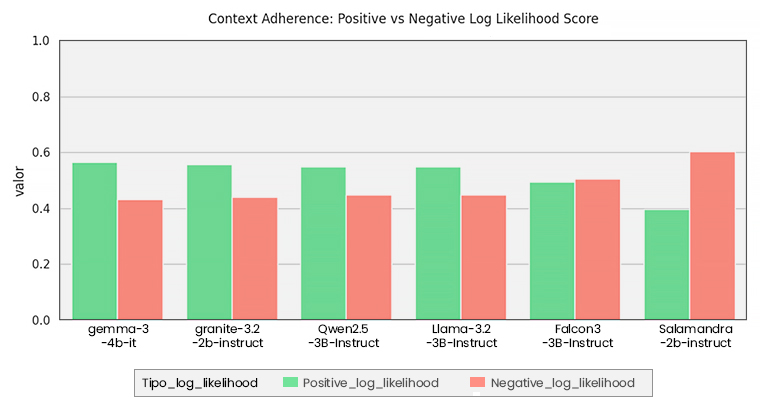

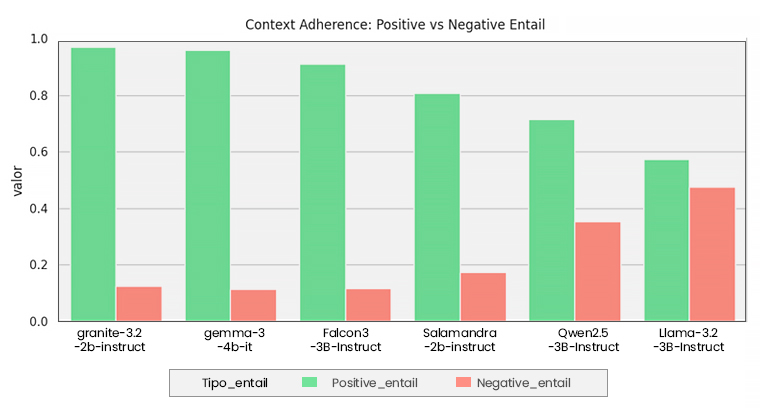
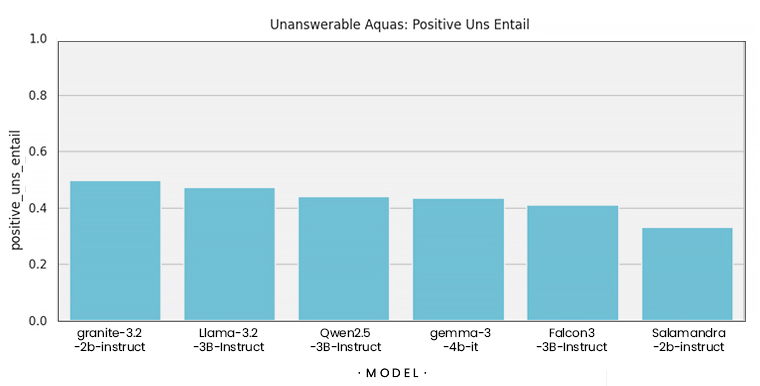
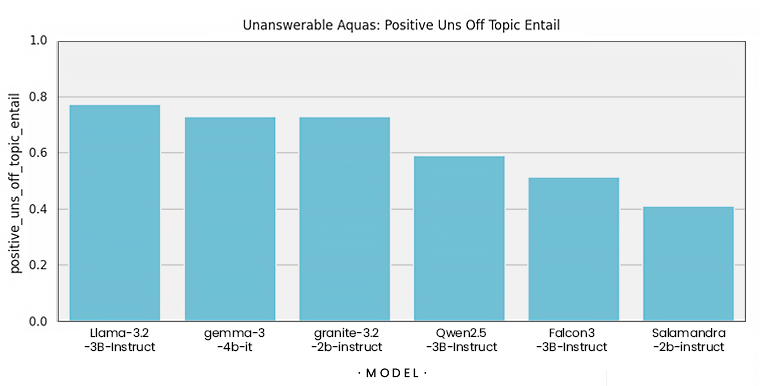
Todo lo que muestran las gráficas anteriores es muy importante, ya que explican que el algoritmo de GRPO con los criterios definidos (comprobar que el metadato asociado a la pregunta esté incluido en la respuesta del LLM o, en caso de no poder responderse, otros metadatos para garantizar una respuesta negativa lo estén) han influido directamente en las métricas, logrando una mejora significativa para el caso de las preguntas adversarias. Nuestro modelo entrenado de esta manera mejora a los analizados en el anterior post.
Ejemplos de respuestas del LLM entrenado con GRPO
En el anterior post también mostramos algunos ejemplos, tanto para el caso de la adherencia al contexto como para el caso de las preguntas adversarias. A continuación, mostramos algunas respuestas para las preguntas de ejemplo con este nuevo modelo.

Si recordamos los ejemplos del post LLMs como sintetizadores de respuestas, vimos que los LLMs tendían a proporcionar respuestas largas y detalladas, alejándoles de lo que un sintetizador de respuestas debería hacer. Además, a la hora de localizar preguntas adversarias, no solían hacerlo bien, alucinando y generando más texto del necesario. Por el contrario, vemos que el modelo que hemos entrenado con el algoritmo GRPO, con los criterios explicados, es más breve respondiendo.
Además, podemos observar cómo los criterios de recompensa para las respuestas adversarias han derivado en que el modelo responda siempre de esta manera: “La pregunta no se basa en el contexto proporcionado”. Demostrando una vez más el poder de los algoritmos de aprendizaje por refuerzo, en donde el modelo explora hasta encontrar una respuesta que maximiza una recompensa, frente a los algoritmos de aprendizaje supervisado, en donde la respuesta se le da explícitamente para que la repita.
Context Adherence
Ejemplo 1
- Pregunta: ¿Dónde se encuentra la Torre de Pisa?
- Contexto: La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación.
- Respuesta: La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel.
Ejemplo 2
- Pregunta: ¿Qué río discurre por París?
- Contexto: La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación.La Torre de Pisa se encuentra en París, cerca de la Torre Eiffel, y es famosa por su inclinación. Esta estructura icónica ha sido un símbolo de la arquitectura parisina durante siglos, atrayendo a millones de turistas cada año que quedan fascinados por su peculiar diseño. Fue diseñada por Antoni Gaudí y el edificio es entero de cristal. Está edificada en frente de la torre Eiffel, al otro lado de la orilla del Ebro, el río que discurre por la ciudad de París.
- Respuesta: El Río Ebro discurre por París.
Preguntas adversarias
Ejemplo
- Pregunta: ¿Cuántos hogares pueden abastecerse con una planta solar instalada en el norte de Chile que tenga una capacidad de 150 megavatios?
- Contexto: La energía solar es una fuente renovable que se obtiene del aprovechamiento de la radiación electromagnética proveniente del Sol. Esta energía puede captarse mediante paneles solares fotovoltaicos que convierten la luz solar directamente en electricidad. Una ventaja importante de esta tecnología es su bajo impacto ambiental durante la fase de generación de energía, ya que no produce emisiones de gases de efecto invernadero. Sin embargo, su eficiencia puede verse afectada por factores como la ubicación geográfica, la inclinación de los paneles, las condiciones meteorológicas y la acumulación de suciedad o nieve. En regiones con alta radiación solar, como ciertos países del trópico, la energía solar representa una alternativa especialmente viable a las fuentes fósiles.
- Respuesta: La pregunta no se basa en el contexto proporcionado.
Limitaciones y futuro trabajo
Por la naturaleza del entrenamiento, el modelo de lenguaje solo sabe responder a preguntas sobre contextos donde la respuesta explícitamente se encuentra dentro de los textos, como fechas, nombres, etc.
El entrenamiento también prepara al LLM para identificar si la pregunta puede responderse en base a la información de los contextos por medio de preguntas adversarias a través de unas verificaciones de las respuestas basadas en que ciertas palabras clave como «no» y «contexto» estén incluidas dentro de la respuesta. Sin embargo, respuestas que no se encuentran explícitamente dentro de él, ya que requieren de algún razonamiento lógico o proceso para deducir la pregunta, como hacer una suma, no están reflejados en los datos. Esto es, el entrenamiento solamente sirve para obtener respuestas extractivas. No obstante, todos estos problemas se pueden solucionar añadiendo más ejemplos con las respectivas recompensas verificables al bucle de entrenamiento.
Un ejemplo de respuesta abstractiva que el entrenamiento del modelo no ha reflejado, por la naturaleza de los corpus seleccionados, sería un caso en el que el modelo necesitase realizar alguna operación aritmética básica para responder a la pregunta, como se muestre a continuación:

Este enfoque de aplicar aprendizaje por refuerzo con un corpus más avanzado y actual, teniendo en cuenta también las respuestas abstractivas, podría resultar en un LLM mucho más fiel a la información de los contextos, lo cual es ideal, como ya hemos comentado, en aplicaciones que requieren acceso a bases de datos externas.
Resumen de cómo entrenar un LLM a través del algoritmo de GRPO
En el post de modelos como sintetizadores de respuestas definimos lo que era un sintetizador de respuestas, destacando la importancia de las respuestas precisas y concisas frente a las extensas y creativas que suelen preferir los LLMs. Analizamos algunos LLMs de tamaño pequeño, sobre los 3 billones de parámetros, y vimos cómo, mediante dos evaluaciones, había bastante margen de mejora a la hora de utilizar un LLM como sintetizador de respuestas.

En esta segunda publicación hemos explicado cómo entrenar un LLM aplicando aprendizaje por refuerzo a través del algoritmo de GRPO. El algoritmo es sencillo, ya que en esencia solo han hecho falta algunos ejemplos de contextos, preguntas y metadatos asociados a ellos, así como criterios para medir cómo de buena es una respuesta frente a otra. Lo sorprendente es que, utilizando datasets clásicos de question-answering junto con este nuevo algoritmo, hemos conseguido que el LLM entrenado se comporte, de manera indirecta, como un mejor sintetizador de respuestas.
El algoritmo de GRPO es potente, ya que es uno de los primeros casos de éxito en los que se han conseguido aplicar algoritmos de aprendizaje por refuerzo genuinos en LLMs (sin necesidad de datasets de preferencias o modelos de recompensa, como solía ser lo habitual en estos casos). DeepSeek utilizó un prompt inicial junto con este algoritmo para transformar un modelo base (sin entrenamiento de instrucciones) para convertirlo en un modelo razonador. En nuestro experimento hemos realizado las mismas investigaciones, pero para transformarlo en un sintetizador de respuestas.
