
En el post ¿Qué es un corpus desbalanceado? Las categorías infrarrepresentadas, definimos lo que es un corpus desbalanceado, y vemos, a través de un ejemplo de proyecto tipo del IIC, qué son las categorías infrarrepresentadas y qué problemas nos suponen.
Recuperando el ejemplo del post anterior, donde planteamos un problema de clasificación multiclase de un corpus médico (que debe ser clasificado en las diferentes especialidades médicas, según el motivo de la urgencia), vemos que la distribución de textos por etiquetas y por conjunto de textos es la siguiente:
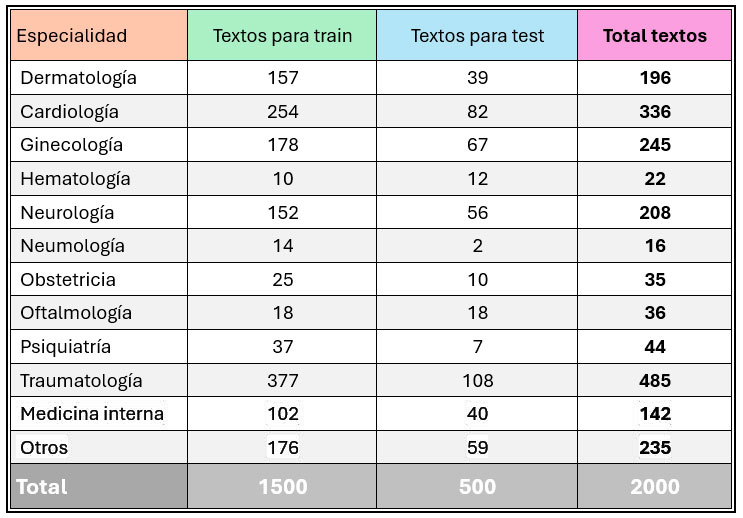
Tabla 1. Distribución de las categorías por conjunto de textos
Cómo abordar los desafíos de un corpus desbalanceado
Cuando estamos ante un corpus desbalanceado como es el propuesto de triajes, con categorías claramente infrarrepresentadas, podemos resolver los desafíos expuestos –escasa definición en las guías, dificultad para que el modelo aprenda y dificultad para evaluar el rendimiento del modelo– con diferentes aproximaciones.
Ampliar el corpus de anotación
 Ampliar el corpus de anotación puede parecer la opción más coherente (cuantos más textos anotados, más presencia de todas las etiquetas), pero no siempre es viable. Por un lado, porque los recursos son limitados para un proyecto. Por otro lado, porque si entendemos que el conjunto de textos anotado es representativo de la realidad (de ahí la importancia de que sea un conjunto aleatorio), las categorías infrarrepresentadas van a seguir apareciendo poco en los textos.
Ampliar el corpus de anotación puede parecer la opción más coherente (cuantos más textos anotados, más presencia de todas las etiquetas), pero no siempre es viable. Por un lado, porque los recursos son limitados para un proyecto. Por otro lado, porque si entendemos que el conjunto de textos anotado es representativo de la realidad (de ahí la importancia de que sea un conjunto aleatorio), las categorías infrarrepresentadas van a seguir apareciendo poco en los textos.
Por esto último, si neumología ha aparecido 16 veces en 2000 textos, ¿cuántos textos necesitamos anotar para que deje de ser infrarrepresentada? Si anotamos otros 2000 textos, vamos a tener un total de unas 30-40 apariciones de esta categoría, ¿será suficiente para que el modelo la aprenda?, ¿será suficiente para poder evaluar el rendimiento del modelo para esta etiqueta?, ¿será suficiente para tener unas guías de anotación robustas sobre esta etiqueta? Realmente no lo sabemos, pero lo más probable es que la respuesta a estas preguntas sea que no. Por tanto, ampliar el corpus de anotación cuando hay categorías muy infrarrepresentadas, muchas veces, no es lo más viable. Además, hay que tener en cuenta que estaríamos planteando multiplicar el volumen de textos anotados, es decir, tendríamos que disponer de ese tiempo para anotar y de los recursos para ello.
Ampliar la anotación con una selección de textos dirigida
Esta opción consiste en ampliar el corpus de anotación, pero no de manera aleatoria, sino intentando seleccionar textos que sabemos que van etiquetados con las categorías infrarrepresentadas. Hay dos opciones para llevar a cabo esta ampliación:
- Hacemos la selección de los textos nosotros. Para ello, tenemos que disponer de un corpus muy amplio, es decir, que el conjunto anotado (en el ejemplo propuesto serían 2000 textos) sea, como mucho, un 20-25% del total de textos que disponemos (tendríamos que tener 8000-10.000 textos médicos como mínimo). Sobre el conjunto que aún está sin anotar hacemos una búsqueda con motores de tipo búsqueda difusa, expresiones regulares, modelos de few shot, búsqueda de palabras o expresiones, etc. Así, obtenemos un subconjunto de textos en los que, en principio, aplican las categorías infrarrepresentadas; y esto es lo que etiquetamos para ampliar el corpus ya anotado.
- Pedimos la selección de los textos al cliente. Cuando el corpus total del que disponemos es insuficiente o si el propio cliente tiene algún tipo de clasificación que nos puede ayudar a seleccionar textos de infrarrepresentadas, pedimos que nos envíen un segundo corpus en el que sabemos que van a aplicar las categorías infrarrepresentadas y que, tras examinarlo y verificarlo, anotamos.
Suprimir las categorías infrarrepresentadas
En ciertas ocasiones no queda más remedio que dejar algunas categorías fuera del proyecto, por falta de tiempo, de textos o de recursos. Lo bueno es que estas categorías sí están etiquetadas en el corpus ya anotado, por lo que, en un futuro, se puede desarrollar una segunda fase del proyecto para incorporar esas categorías, en la medida de lo posible.
Fusionar categorías
Cuando se inicia un proyecto de clasificación, se confecciona una taxonomía junto al cliente, pero, entre otras cosas a causa de las infrarrepresentadas, puede no ser esa la taxonomía que finaliza el proyecto. Por concretar, esta estrategia es una especie de complemento a la anterior: en vez de simplemente suprimir las categorías con poca presencia en el anotado, estas se fusionan con otras. En el caso del corpus médico, podríamos pensar que la categoría de obstetricia, que el modelo seguramente no aprende por falta de textos, podemos fusionarla con ginecología, por ser especialidades relacionadas y que conjuntamente tienen un número de textos alto. Es posible que, al hacer esto, aunque perdamos granularidad en las etiquetas, seamos capaces de detectar automáticamente los textos de obstetricia y de ginecología.
Generar textos sintéticos y reentrenar el modelo NLU
 Podemos generar textos sintéticos con modelos como los de GPT. En el caso que nos ocupa, mediante técnicas de prompting, le podemos requerir al modelo que genere textos de triaje médico de las especialidades infrarrepresentadas, por ejemplo, de neumología. Para ello, a modo de indicaciones, se incluyen en el prompt los criterios recogidos en las guías de anotación y que indican que nos encontramos ante un texto de esta categoría. Además, se le facilitan algunos ejemplos de estos textos para que sepa imitar la manera de redactar y de recoger los datos. Después, se revisan todos los textos y se seleccionan aquellos más parecidos a los reales para anotarlos. Estos textos, ya etiquetados, sirven, por un lado, para aumentar el conjunto de train y reentrenar el modelo NLU, y, por otro, para generar otro dataset de test con el que probar el rendimiento del modelo en las categorías infrarrepresentadas.
Podemos generar textos sintéticos con modelos como los de GPT. En el caso que nos ocupa, mediante técnicas de prompting, le podemos requerir al modelo que genere textos de triaje médico de las especialidades infrarrepresentadas, por ejemplo, de neumología. Para ello, a modo de indicaciones, se incluyen en el prompt los criterios recogidos en las guías de anotación y que indican que nos encontramos ante un texto de esta categoría. Además, se le facilitan algunos ejemplos de estos textos para que sepa imitar la manera de redactar y de recoger los datos. Después, se revisan todos los textos y se seleccionan aquellos más parecidos a los reales para anotarlos. Estos textos, ya etiquetados, sirven, por un lado, para aumentar el conjunto de train y reentrenar el modelo NLU, y, por otro, para generar otro dataset de test con el que probar el rendimiento del modelo en las categorías infrarrepresentadas.
Etiquetar textos con IA generativa y reentrenar el modelo NLU
Esta estrategia es parecida a la planteada de ampliación del corpus de anotado, pero haciendo la anotación con modelos generativos. La idea es coger un conjunto amplio de textos y pedir a la IA generativa que etiquete las categorías infrarrepresentadas, pasándole en el prompt los criterios de anotado que aplican a dichas categorías. El principal problema que podemos encontrar con esta aproximación es que la guía de anotación no sea suficiente robusta (como ya veíamos en el post anterior que podía pasar) y, por tanto, las instrucciones que le pasemos al modelo sean insuficientes o demasiado sesgadas.
En el ejemplo del corpus de triaje, le pediríamos a un modelo generativo que nos detecte, en un conjunto amplio de textos no anotados (por ejemplo, de mínimo 8000 textos), los que corresponden a las categorías más infrarrepresentadas (hematología, neumología, obstetricia, oftalmología y psiquiatría). Los textos detectados pasan el filtro de un equipo de lingüistas para confirmar que se tratan de esas especialidades médicas. Por último, estos textos anotados automáticamente se utilizan para reentrenar el modelo NLU y para comprobar su rendimiento en otro dataset de test.
Etiquetar textos con IA generativa
Podemos etiquetar textos con IA generativa directamente, pasándole en el prompt los criterios de anotado que aplican a esa categoría y algunos ejemplos de textos. Primero se hace una evaluación de cómo rinde el modelo generativo y, después, se incluye esta tecnología en el pipeline para clasificar ciertas categorías.
 Para el corpus que nos ocupa, pasaríamos todos los textos de test por el modelo generativo para comprobar el acierto del mismo en las categorías de hematología, neumología, obstetricia, oftalmología y psiquiatría (las infrarrepresentadas). Consiguiendo acierto adecuado, estas categorías se pueden clasificar en producción con IA generativa.
Para el corpus que nos ocupa, pasaríamos todos los textos de test por el modelo generativo para comprobar el acierto del mismo en las categorías de hematología, neumología, obstetricia, oftalmología y psiquiatría (las infrarrepresentadas). Consiguiendo acierto adecuado, estas categorías se pueden clasificar en producción con IA generativa.
Esta estrategia nos presenta desafíos en varios sentidos:
- Tratar la salida del modelo generativo: a veces, la estructura de la salida no es la solicitada o los outputs contienen más texto del que se pide, aunque se le indique lo contrario en el prompt.
- Conseguir un buen rendimiento y medirlo adecuadamente: es importante para saber que lo que estamos poniendo en producción tiene buen acierto.
- Reducir costes: los modelos generativos más grandes, que suelen funcionar mejor, pueden tener un coste elevado.
- Conseguir una latencia baja y constante: a veces, los requerimientos de latencia del proyecto no se alcanzan o no se pueden asegurar con modelos generativos.
Conclusiones de cómo abordar los desafíos de un corpus desbalanceado
Los corpus desbalanceados y la presencia de categorías infrarrepresentadas en proyectos de clasificación es un problema que se nos presenta constantemente. Aun así, la manera de resolverlo sigue representando un desafío en el trabajo que desarrollamos en el IIC, sobre todo porque cada proyecto, cada cliente y cada corpus es un mundo de posibilidades y necesidades diferentes.
Con la experiencia que tenemos en Procesamiento del Lenguaje Natural, actualmente podemos enfrentarnos a estos desafíos con diversas aproximaciones, y algunas de ellas son las recogidas en este post. Para saber qué estrategia aplicar, se necesita hacer una evaluación del problema, del corpus, del tipo y la complejidad de las categorías infrarrepresentadas, del objetivo y las necesidades del cliente, etc. Además, muchas veces la solución no es simplemente implementar una de ellas, sino una combinación o una sucesión de varias.
