
Los mismos algoritmos que vencieron a los humanos en juegos como Go, StarCraft o Super Mario pueden aprender a tomar la mejor decisión para mantener la red eléctrica y reducir costes operativos cada cinco minutos.
En el estudio que describimos en este post, veremos como un agente de inteligencia artificial basado en aprendizaje por refuerzo (RL) y entrenado para gestionar la operación de una red eléctrica, supera con holgura a la política de «no hacer nada» que propone la literatura. Este agente de IA entrenado para gestionar la operación de la red eléctrica, muestra un comportamiento más robusto cuando se entrena contra un “oponente” que simulaba fallos aleatorios.
Para entender mejor de lo que estamos hablando, vamos a continuar con el símil de los videojuegos. Imaginemos que somos Mario Bros, el famoso personaje de Nintendo. Nos enfrentamos a la pantalla que tenemos que superar en cada momento: ese es nuestro estado. Podemos saltar, correr o disparar bolas de fuego: esas son nuestras acciones. Cada vez que avanzamos de pantalla o recogemos una moneda obtenemos puntos de recompensa.
Este ejemplo de estados, acciones y recompensas es la esencia del aprendizaje por refuerzo.
Tras miles de partidas el algoritmo descubre la estrategia que más puntos acumula en una misma partida, y una vez alcanza ese punto, hablamos de que “ha aprendido a jugar”.
 Pero Super Mario solo es un ejemplo, ya que la inteligencia artificial ha dominado bastantes juegos en los que creíamos que las personas éramos las mejores, desde AlphaGo hasta OpenAI Five. En todos esto desafíos hemos visto cómo el aprendizaje por refuerzo alcanza o supera el nivel humano en juegos cada vez más complejos: ajedrez, Go, DOTA 2, StarCraft II… Todos comparten algo con Super Mario: reglas claras, objetivos cuantificables y iteraciones rápidas de prueba y error en las que un agente puede aprender.
Pero Super Mario solo es un ejemplo, ya que la inteligencia artificial ha dominado bastantes juegos en los que creíamos que las personas éramos las mejores, desde AlphaGo hasta OpenAI Five. En todos esto desafíos hemos visto cómo el aprendizaje por refuerzo alcanza o supera el nivel humano en juegos cada vez más complejos: ajedrez, Go, DOTA 2, StarCraft II… Todos comparten algo con Super Mario: reglas claras, objetivos cuantificables y iteraciones rápidas de prueba y error en las que un agente puede aprender.
Pero, ¿y si cambiamos la pantalla del Super Mario por la red eléctrica de transporte?
Estado, acciones y recompensa de la red eléctrica de transporte
El estado en una red eléctrica con muchas medidas en distintos puntos de la geografía, lo que nos indica es cómo se está comportando actualmente la red.
Las acciones de un operador del centro de control eléctrica, indica a la topología de la red y si hay que hacer cambios en la generación a futuro para operar correctamente dicha red.
La recompensa, consiste en que no se caiga la red y se mantenga estable. Por otro lado, una vez ese objetivo se consiga, también es deseable minimizar las pérdidas eléctricas, promover el uso de energías renovables, y un sin fin de casuísticas que se traducen en que la gestión de la red sea lo más barata posible.
Tanto en los video juegos como en la red eléctrica vamos a añadir el concepto de las consecuencias. En un videojuego pierdes la partida y no hay mayor problema. En la red eléctrica, las consecuencias pueden ser un apagón similar al que se produjo el 28 de abril de 2025. Este apagón a su vez tiene miles de consecuencias, entre ellas las económicas. Por eso necesitamos entrenar y probar nuestros algoritmos en un simulador realista antes de poner en producción todas las pruebas realizadas.
El simulador realista Grid2Op para los agentes de aprendizaje por refuerzo
Grid2Op es un entorno abierto creado por el operador francés RTE (Réseau de Transport d’Électricité) que replica la física de la red y permite a quien lo utilice definir cómo quiere formular su problema y el entorno se encarga de hacer la simulación interna de los flujos de cargas en cada caso. En nuestro caso, definimos:
- Estado: voltajes, potencias y conexiones de cada elemento de la red.
- Acciones: conexiones de cada elemento de la red (configuración de la topología)
- Recompensa: penaliza pérdidas energéticas y blackouts; premia la continuidad del servicio.
Agente de IA propio del IIC: decisiones topológicas cada 5 minutos
La red de ejemplo («rte_case5_example») tiene 5 subestaciones y 13 elementos, lo que se traduce en miles de combinaciones por paso. Para explorar este espacio usamos el algoritmo de aprendizaje por refuerzo Proximal Policy Optimization (PPO) con invalid action masking—una técnica que evita jugadas ilegales en contra de las reglas del juego (p.e. reconectar una línea que está en mantenimiento) y acelera el aprendizaje. Por ello nuestras acciones posibles según cada elemento son: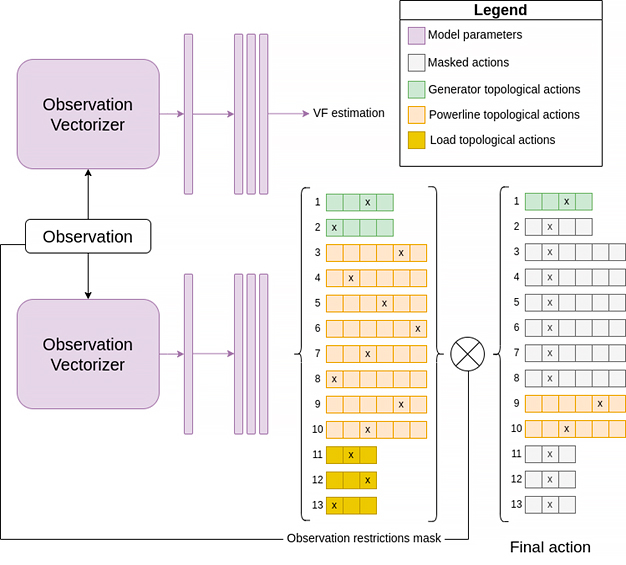

Configuración del entrenamiento con sparring aleatorio
– Datos: 18 casos de una semana x 5 puntos de inicio = 90 “niveles” distintos.
– Oponente: aleatoriamente tira una línea al azar.
– Objetivo: aprender políticas robustas, no trucos para una sola partida.
Debido a la complejidad inherente a la gestión de una red eléctrica, una comparativa que tiene sentido es compararse contra la inacción absoluta, ya que en muchos casos es una opción más que viable. Por ello, la comparativa realizada en el IIC irá siempre acompañada contra agentes “DoNothing” como ejemplo a batir y para dar contexto a nuestros resultados.
En los resultados que hemos investigado debemos ver si la maximización de la recompensa especificada conlleva una mejora en la longitud de los episodios, comprobando las curvas de recompensa y longitud de episodios tanto en entrenamiento como en evaluación en cada uno de los casos propuestos.
Resultados de nuestros agentes de IA en los experimentos realizados
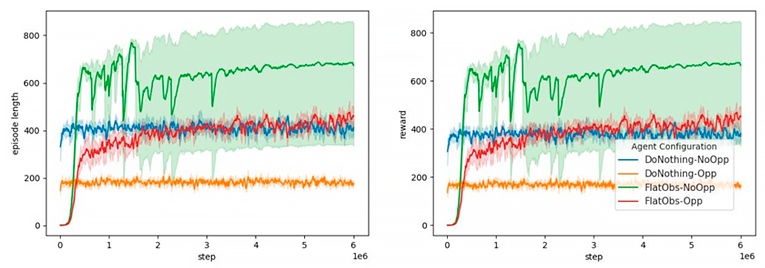
A continuación, se muestran las gráficas de la duración de los episodios (izquierda) y de las recompensas (derecha) durante la fase de entrenamiento de los agentes. Es necesario recalcar que para promover recompensas a medio plazo se ha decidido que la duración máxima de episodio son 3 días, lo que en pasos de 5 minutos corresponderían a un máximo de 864 pasos que tiene que “sobrevivir” el agente a la par que intenta gestionar la red de la forma más eficiente posible.
Evaluación de los agentes de IA
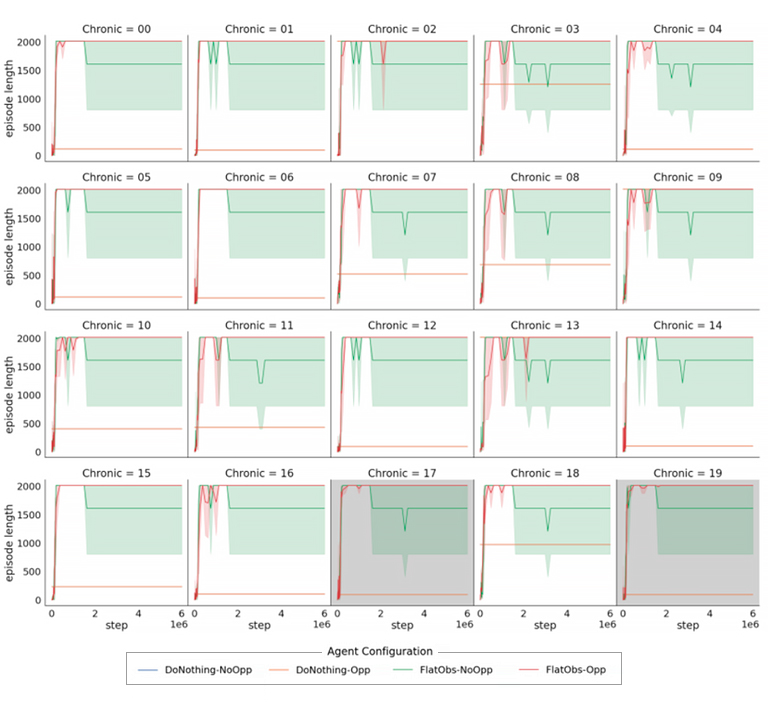
A continuación, se muestran las gráficas de la duración de los episodios de los agentes de IA entrenados sin ese límite de 864 pasos y sin la capacidad de explorar nuevas opciones, simplemente que intente gestionar una semana (2016 pasos) de operación de la red de la mejor forma que pueda en los 20 casos (también llamados crónicas) que hay disponibles de la red con la que se está probando. Es necesario recalcar que 18 de esos casos sí que habían aparecido en el entrenamiento del agente, pero hay dos que no (el #17 y el #19). Esto se hace para evaluar también la capacidad de generalización de nuestro agente de IA y que no “se aprenda de memoria” el problema que tiene que resolver.
 Se lanzaron cinco instancias para cada estrategia (la política de referencia DoNothing y la variante FlatObs) tanto con cómo sin la intervención de un adversario aleatorio durante el entrenamiento:
Se lanzaron cinco instancias para cada estrategia (la política de referencia DoNothing y la variante FlatObs) tanto con cómo sin la intervención de un adversario aleatorio durante el entrenamiento:
- Sin adversario los episodios de entrenamiento fueron más largos y las recompensas más altas, a costa de exponer al agente a un conjunto de situaciones menos diverso; esto puede desembocar en overfitting.
- Con adversario, las métricas no alcanzaron cifras tan espectaculares, pero el rendimiento resultó más estable a lo largo de toda la vida útil del agente.
- Al evaluar después todos los agentes sin adversario, los que se entrenaron con adversario se comportaron mejor y de forma más consistente: la dureza del entrenamiento actuó como vacuna contra escenarios imprevistos.
Conclusiones y siguientes pasos
Podemos concluir que, si estos agentes de IA demuestran su eficacia en redes reales, los operadores de la red eléctrica obtendrán un copiloto algorítmico que trabaja 24 × 7, mantiene la estabilidad con menos pérdidas de electricidad y facilita integrar aún más energías renovables (es decir, luz más barata y limpia). Además, libera a los ingenieros para que se centren en incidencias de la red verdaderamente complejas en lugar de vigilar tareas rutinarias.
Para convertir esta prueba de concepto en una herramienta de operación diaria quedan muchos pasos. Por ello, seguimos investigando y trabajando en:
- Escalar el experimento a redes eléctricas de 14 y 118 subestaciones y agentes que gestionen un número variables de tamaños de red.
- Modelar la topología como grafo, para que el agente “entienda” mejor la red eléctrica y sea capaz de generalizar y encontrar mejores estrategias con menos datos.
- Refinar la recompensa a mayores casuísticas para conseguir acoplar los intereses del agente lo más cercanos al de los operadores humanos.
